



昇思MindSpore 2.8版本正式发布,为超节点而生的HyperParallel架构,训推更灵活、更高效
开发者
发表于 2026/01/29
开发者
发表于 2026/01/29
经过昇思MindSpore开源社区开发者们几个月的开发与贡献,现正式发布昇思MindSpore2.8版本。
面对模型规模持续增长、结构日趋不规则、异构性日益显著的三大紧迫挑战,昇思MindSpore通过与超节点协同设计,推出了HyperParallel架构。此架构将超节点视作一台超级计算机进行编程与调度,其核心由三大关键技术支撑:HyperShard极简声明式并行编程、HyperOffload多级智能卸载,以及HyperMPMD非规则异构并行。
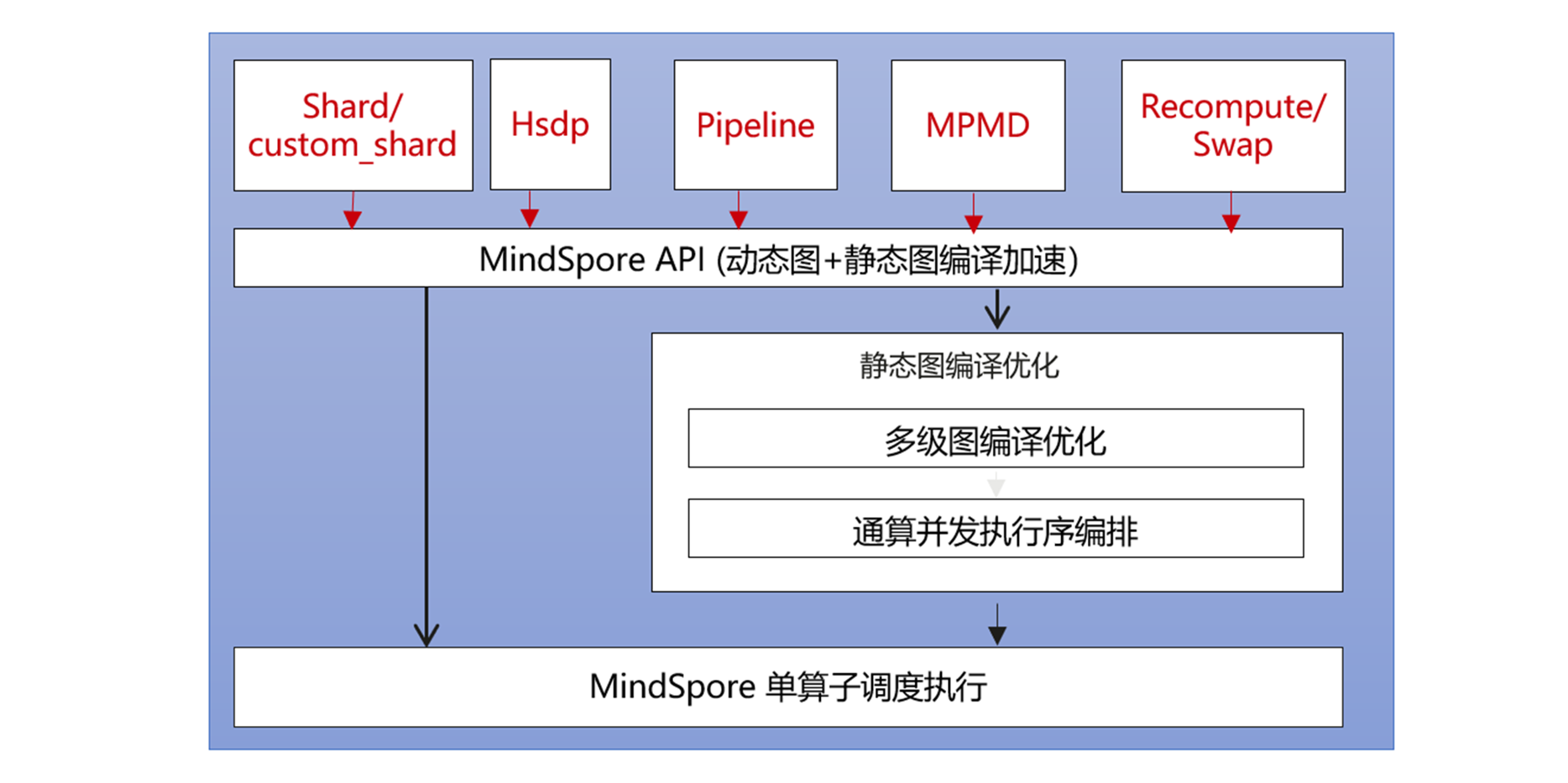
在基础框架演进方面,提供了Dispatch功能、引入saved_tensors_hook机制和算子级注册机制增强动态图能力,并开放多种框架自定义能力提供更灵活、高效的框架扩展机制。
在大模型推理能力提升方面,与SGLang社区合作,提供MindSpore支持并适配Radix Cache等核心特性,升级适配vLLM v0.11.0最新版本并接入了昇腾ACLGraph图下沉功能。
在科学计算套件方面,支持蛋白质结构预测模型Protenix,并实现高性能训推。
下面就为大家详细解读昇思2.8版本的关键特性。
1.支持HyperShard声明式并行,开辟分布式并行领域“Triton范式”
为应对AI模型规模持续扩大、结构日益复杂的趋势,昇思MindSpore 2.8版本推出HyperShard声明式并行编程范式,如下图所示,它旨在彻底简化分布式训练,将并行策略与模型计算逻辑解耦,使用户能摆脱为适配分布式系统而侵入式修改代码的负担,从而专注于模型创新本身。
HyperShard融合了超节点感知调度与全局资源协同,在显著降低编程复杂度的同时,实现接近理论极限的并行效率,致力于开创让高效并行如编写串行代码一样自然的“Triton范式”。它尤其支持多模态大模型编解码器架构的灵活组装,在保障极致性能的同时,提供真正以用户为中心的并行体验。
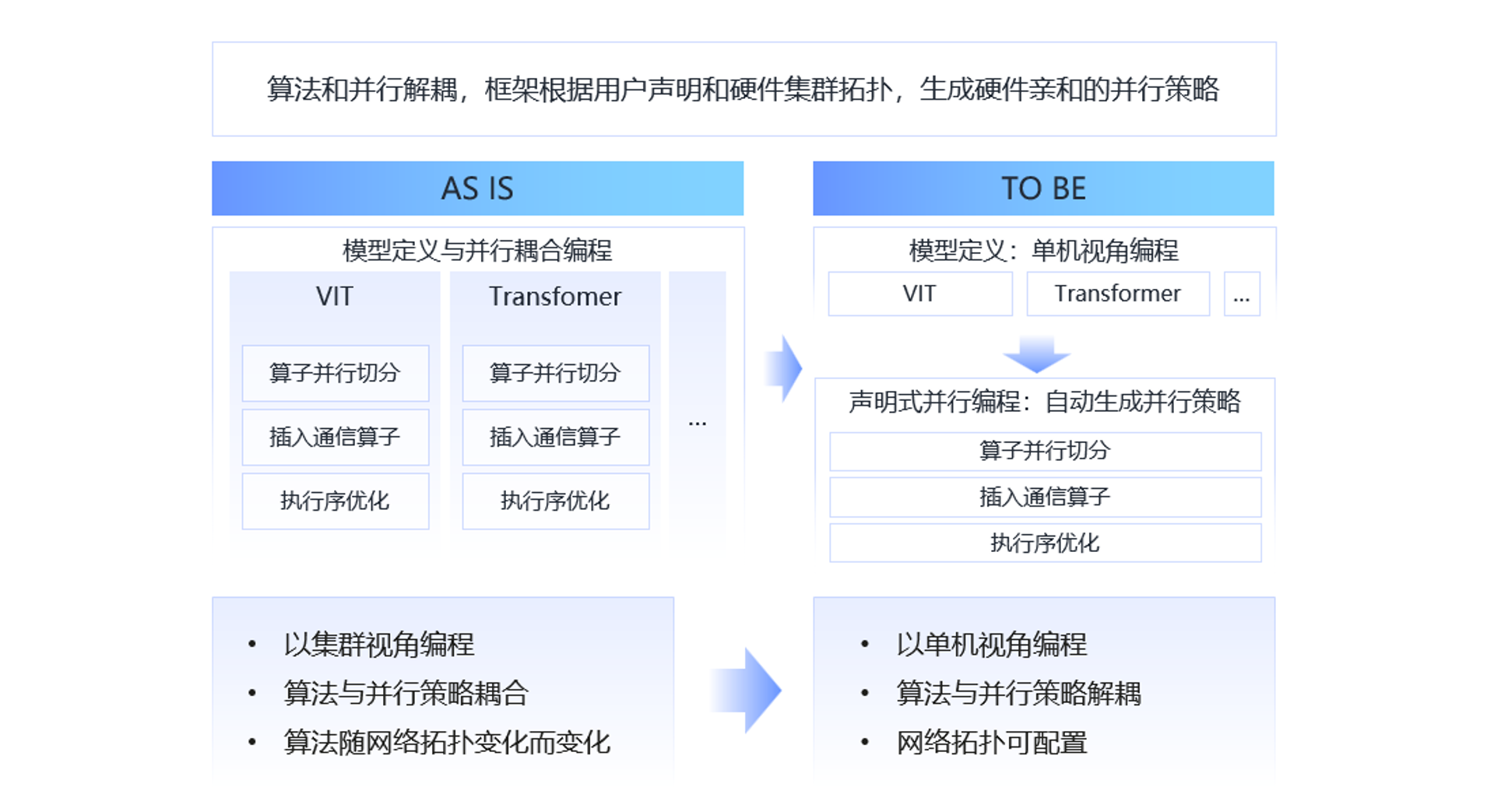 HyperShard构建于昇思MindSpore动静结合的基础之上,提供一套高度解耦、“以模型为中心”的声明式并行库。如下图所示,系统提供手动、DTensor、Shard三种编程范式,支持用户从细粒度控制到全局策略声明灵活选择。其基础并行模块作为可插拔组件,使单卡算法逻辑、并行策略描述、图编译与运行时调度相互分离,从而实现非侵入式的并行扩展——用户只需以单卡视角编写PyNative动态图代码,系统即可自动完成分布式策略推导、子图切分、资源映射与混合并行调度,最终达成“编写即单卡,运行即分布式”的体验。用户只需声明“做什么”,系统自动完成“怎么做”,真正实现极简易用、开箱即优。上述大部分动态图的能力已在HyperParallel子仓中构建,目前提供预览版本,后续会提供更稳定的能力。
HyperShard构建于昇思MindSpore动静结合的基础之上,提供一套高度解耦、“以模型为中心”的声明式并行库。如下图所示,系统提供手动、DTensor、Shard三种编程范式,支持用户从细粒度控制到全局策略声明灵活选择。其基础并行模块作为可插拔组件,使单卡算法逻辑、并行策略描述、图编译与运行时调度相互分离,从而实现非侵入式的并行扩展——用户只需以单卡视角编写PyNative动态图代码,系统即可自动完成分布式策略推导、子图切分、资源映射与混合并行调度,最终达成“编写即单卡,运行即分布式”的体验。用户只需声明“做什么”,系统自动完成“怎么做”,真正实现极简易用、开箱即优。上述大部分动态图的能力已在HyperParallel子仓中构建,目前提供预览版本,后续会提供更稳定的能力。
 参考链接:https://atomgit.com/mindspore/hyper-parallel
参考链接:https://atomgit.com/mindspore/hyper-parallel
2.HyperOffload实现全图自动的数据层次化管理,显著提升显存利用率与训练吞吐
在超大规模模型的训练与推理场景中,硬件加速器的存储容量与数据传输带宽已成为制约系统性能的关键瓶颈。针对这一挑战,昇思MindSpore2.8版本提出并实现了一套基于全图编排的层次化存储管理方案HyperOffload,旨在通过系统级的架构优化,提升异构计算环境下的资源利用率与执行效率。
HyperOffload的核心创新在于数据传输的算子化抽象与流水线并行,打破了传统计算与通信的界限,将跨层级存储的数据搬运操作抽象为图层面的算子,纳入统一的计算图编排体系。依托昇思MindSpore的即时编译(JIT)引擎,系统能够对静态计算图进行深度分析与优化,自动构建计算与通信的并行流水线。通过在计算任务执行期间预取后续数据,该机制有效地掩盖了高延迟的I/O开销,显著降低了计算单元的空闲等待时间。
针对不同开发模式的需求,HyperOffload提供了灵活的接入方式:
温馨提醒:HyperOffload当前处于实验性阶段。虽然初步验证表明该架构在提升显存效率与计算吞吐方面具有显著优势,但针对特定复杂网络结构的适配仍需进一步验证。未来,我们将持续优化内存调度算法与全图编译策略,致力于在更广泛的生产环境中提供稳定、高效的异构存储解决方案。
参考链接:https://www.mindspore.cn/docs/zh-CN/master/api_python/mindspore/mindspore.jit.html
3.增强动态图能力,支持更灵活的执行与扩展机制
昇思MindSpore在动态图(PyNative)模式下持续迭代,围绕易用性、算力利用率以及大规模并行场景的核心痛点,在昇思MindSpore2.8版本中推出三项重要的增强特性。这些能力互相协同,为用户带来更高效、更灵活、更具未来扩展空间的深度学习开发体验。
3.1 动态图Dispatch功能
全新的Tensor Dispatch能力补齐了动态图在异构设备支持上的核心能力。当前作为Demo特性,通过环境变量开启。开启后,用户无需再为算子选择或设备匹配进行额外编码,只需将 Tensor 放置在目标设备上,框架便可基于Tensor的存储位置自动进行算子分发调用。通过这一机制,昇思MindSpore在多设备协同场景下显著提升易用性与一致性。
参考链接:https://www.mindspore.cn/docs/zh-CN/master/api_python/env_var_list.html?highlight=dispatch
3.2 动态图saved_tensors_hook
引入了saved_tensors_hook机制,将激活值生命周期纳入可编排范畴。借助pack/unpack hook,可以在不侵入核心模型逻辑的情况下实现激活offload能力。这不仅为大模型训练提供更主动和更节省显存的策略,也为未来更多创新式的内存优化手段打开了空间,使动态图模式下的训练更加灵活、稳健、高效。
3.3 动态图算子级注册机制
提供了算子级注册机制将动态图的可扩展性提升到全新维度。通过继承Tensor,在子类中实现__fallback__函数,各类组件能够在算子执行链路中注入自定义行为。这一能力对声明式编程尤为关键,用户可以在不修改模型代码的情况下,为算子自动插入并行layout或自定义策略,加速构建复杂分布式训练体系。
随着这三项能力的发布,昇思MindSpore动态图不仅在易用性和兼容性上迈出关键一步,帮助用户从算子调试到大模型训练,都能拥有更高效且更确定性的工作流程。
4.开放多种框架自定义能力,灵活高效实现用户自定义逻辑
随着AI模型与硬件生态的日益复杂,用户在追求极致性能与创新时,常面临两大核心挑战:一是主流深度学习框架的固定算子库难以覆盖所有前沿算法或特定领域(如科学计算)的算子需求;二是框架的默认优化策略与运行时无法充分释放专用硬件(如新型AI加速卡)的全部潜力。这种“框架通用性”与“业务/硬件特殊性”之间的鸿沟,限制了技术落地的深度与效率。昇思MindSpore 2.8版本显著增强框架自定义开放能力,重点围绕自定义算子、自定义PASS和自定义后端三个维度,为用户提供了更灵活、高效的框架扩展机制。
4.1 自定义算子
自定义算子提供极简C++开发接口,天然内置多级流水,用户Kernel一经编译即可无缝嵌入 昇思MindSpore执行图,自动享受内存复用、异步调度等框架级优化;通过CustomOpBuilder工具,编译加载一步完成,像普通算子一样直接调用。同时提供专为ACLNN、ATB、ASDSIP三大加速库量身定制的AclnnOpRunner、AtbOpRunner、AsdSipFFTOpRunner运行器,零成本对接高性能算子,用户亦可继承PyboostRunner快速封装私有Kernel,科研与产线的创新算子快速上线、性能即刻释放。
参考链接:https://www.mindspore.cn/tutorials/zh-CN/master/custom_program/operation/op_customopbuilder.html
4.2 自定义PASS
昇思MindSpore开放了框架pass编写及注册接口,用户可通过编写并注册自定义PASS插入自定义图优化逻辑,在编译期对计算图进行变换:
参考链接:https://www.mindspore.cn/tutorials/zh-CN/master/custom_program/custom_pass.html
4.3 自定义后端
昇思MindSpore开放了后端编译执行扩展接口,允许用户适配第三方后端:
参考链接:https://www.mindspore.cn/tutorials/zh-CN/master/custom_program/custom_backend.html
昇思MindSpore通过增强三大自定义能力,显著提升了框架的开放性与可扩展性。用户能够针对特定算法、硬件或场景,灵活定制计算逻辑、优化策略与运行时支持,从而在保持框架统一性的同时,充分发挥软硬件协同潜力,加速AI应用创新与落地。
5.支持SGLang,升级适配vLLM v0.11.0最新版本
作为一款专为生产级部署设计的推理服务框架,SGLang因其低延迟、高吞吐的出色性能表现,以及对DeepSeek-V3.2 Exp、Qwen3-Next等SOTA模型的快速适配,已成为继vLLM后的又一主流大模型推理引擎。2025年11月,经历多轮方案讨论和技术验证,SGLang社区已合入了昇思MindSpore推理后端代码,支持以昇腾+昇思为底座的大模型推理加速。
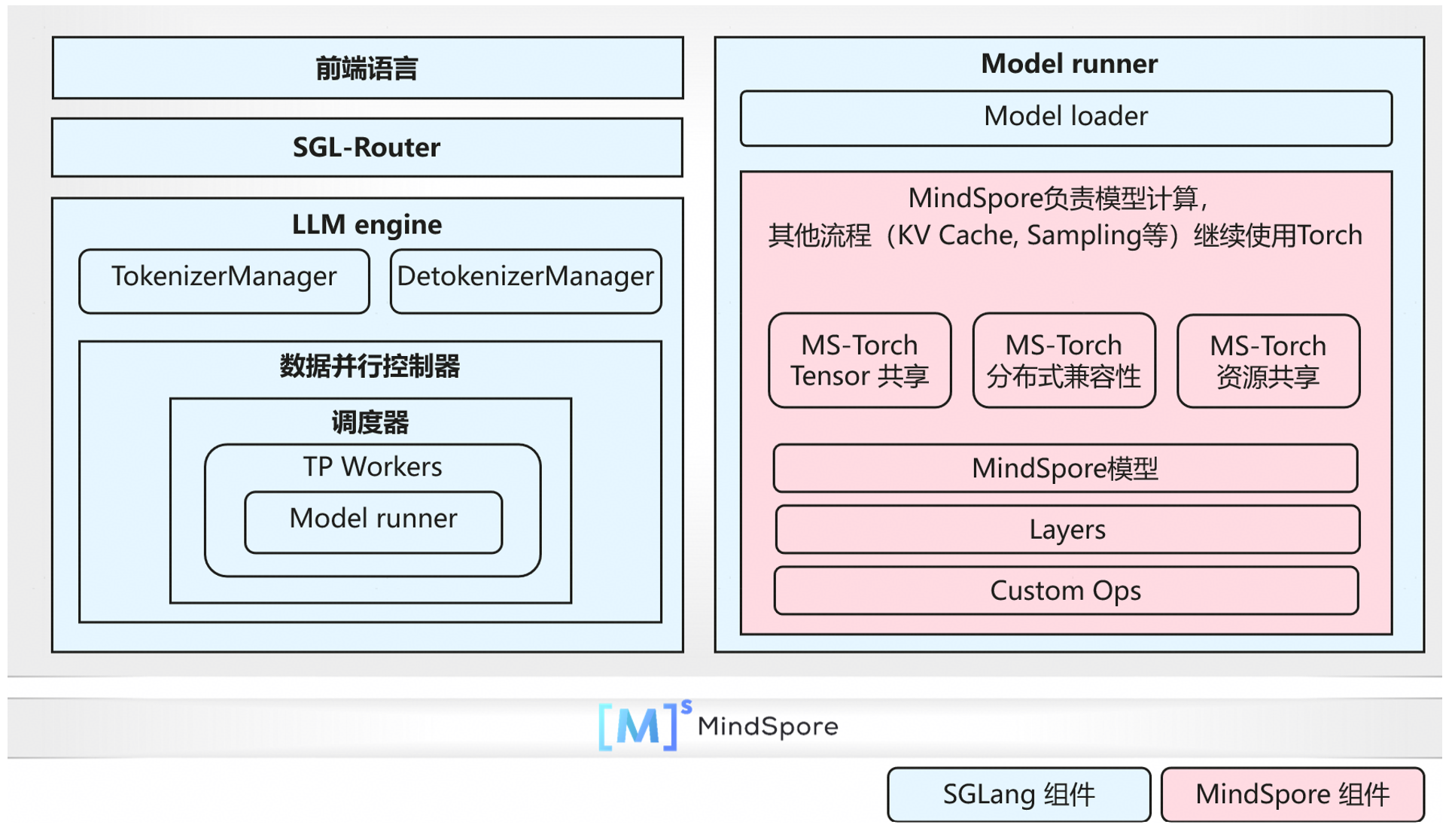 SGLang支持MindSpore推理后端系统架构图
SGLang支持MindSpore推理后端系统架构图
如上图所示,SGLang采用后端组件化接入的方案,实现对MindSpore大模型推理的支持。该方案完整复用了SGLang的前端语言、路由器、数据并行控制器等服务模块,仅在模型执行模块中,将MindSpore推理模型统一封装为MindSporeForCausalLM类,以替换SGLang的模型类。
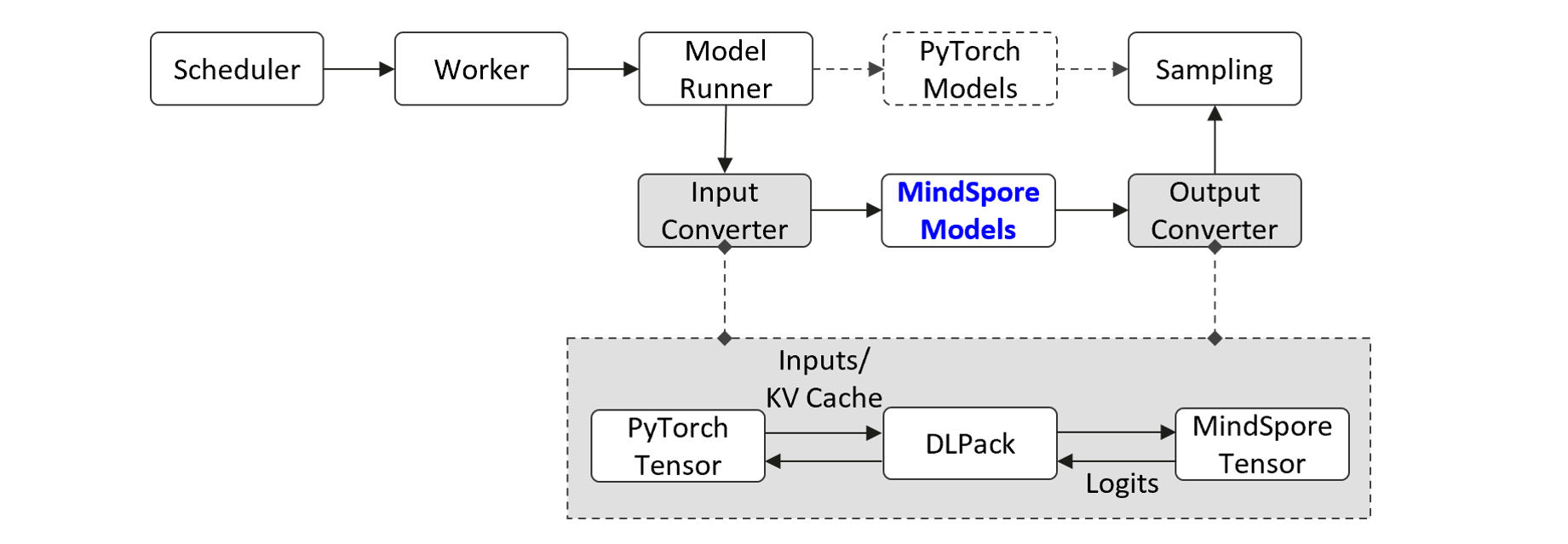 昇思MindSpore-PyTorch协同实现SGLang推理流程图
昇思MindSpore-PyTorch协同实现SGLang推理流程图
如上图所示,该项目通过适配DLPack等功能库,实现了昇思MindSpore和PyTorch之间,跨AI框架高效复用PyTorch张量、HCCL通信组等数据结构。使得昇思MindSpore推理模型,可以无缝嵌入涉及PyTorch接口调用的功能流程中,仅需简单的接口适配,即可支持SGLang的Radix Cache、数据和张量并行、PD分离、投机推理等特性。
当前,SGLang 0.5.6已搭载昇思MindSpore推理后端,支持DeepSeek-V3/R1、Qwen3模型,以及Radix Cache、混合并行、PD分离等核心服务特性。为提升项目可维护性,昇思MindSpore推理模型脚本在独立仓开发,当前临时托管在MindSpore-Lab组织(https://github.com/mindspore-lab/sgl-mindspore),验证完成后将移至SGLang社区组织(https://github.com/sgl-project)。
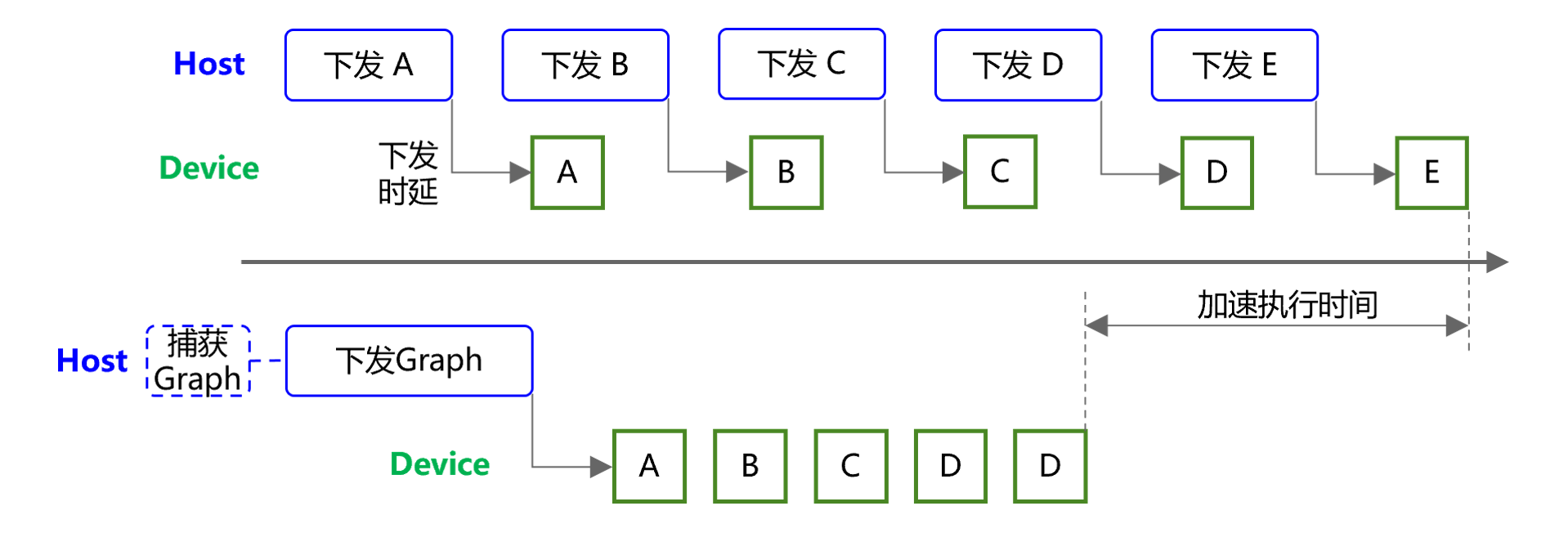 ACLGraph加速原理图
ACLGraph加速原理图
与此同时,昇思MindSpore推理升级适配了vLLM v0.11.0版本,跟随上游社区的架构演进,移除了老旧的V0架构代码,并接入了昇腾ACLGraph图下沉功能。如上图所示,ACLGraph支持将待执行的多个算子捕获成图后,一次下发,从而有效消除因Host Bound引入的NPU资源利用率低的问题。经测试验证,采用vLLM+MindSpore部署DeepSeek-V3/R1 W4A8量化推理服务,开启ACLGraph功能后,整网吞吐性能提升约5%,算子下发时延平均由30ms降低至10ms。此外,本次升级适配拓展支持了GLM-4.1V-Thinking、Qwen3-VL、MiniCPM4等SOTA大模型。
6.支持蛋白质结构预测模型Protenix,实现高性能训推
Protenix是AlphaFold3的高性能开源复现模型,采用先进的扩散生成架构,通过完整开源代码与权重,为全球生物医药研究者提供了一个可直接训练、微调且性能媲美顶尖闭源模型的高效工具,而昇思MindSpore2.8版本支持Protenix并在昇腾硬件平台上实现了高性能的训练和推理。
在模型训练方面,针对激活值数量极大的Triangle Attention,Triangle Multiplication和smooth_lddt_loss等计算模块进行重计算处理,此前在64GB显存下仅能训练长度为64的序列,且动态显存峰值约为20152MB,经重计算优化后可支持训练长度最高可提升到768,显存峰值可下降到7025MB。这一优化是Protenix能够在昇腾硬件平台上支持长序列训练的关键技术点之一。
在模型推理方面,针对Unfold算子带来的明显性能瓶颈,进行了算子重构;其次在融合算子的开发与调优方面,实现了EvoformerAttention算子的开发与Einsum算子的逻辑优化,两者联合使用后的单卡推理性能提升最大可超100%;针对长序列推理场景,昇思MindSpore解决了存在于msa_attention,triangle_multiplication,transition_block等模块中的内存瓶颈,对其采用分块计算的模式并避开了LayerNorm、Softmax等非线性操作所涉及维度,在不改变推理精度的前提下成功将昇腾硬件单卡推理Token长度极限提升到3000以上;最后,对 Transformer核心模块进行了JIT编译优化,提前编译为静态图,在执行时以大算子形式一次性下发从而极大减少算子调度成本,最终实现了57%的端到端加速比。
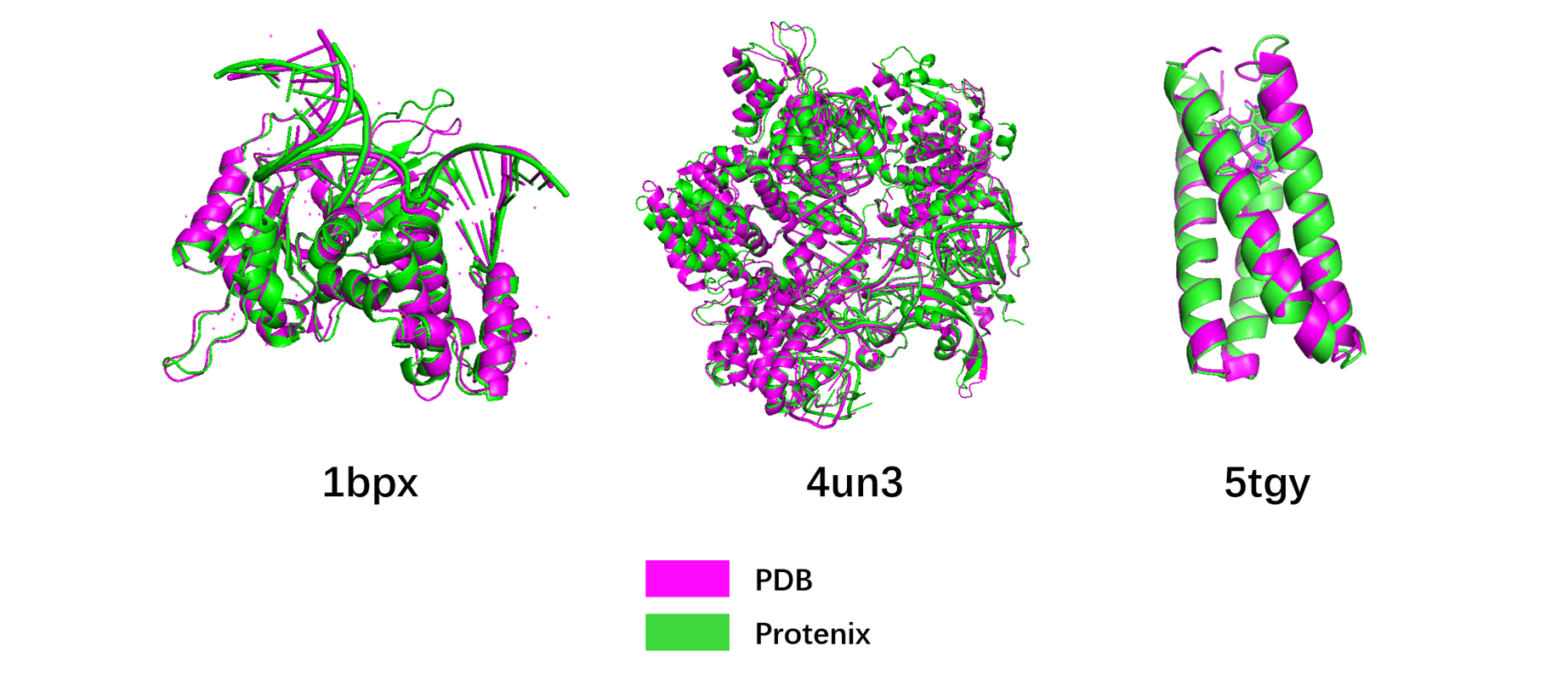
在上述调优策略下,Protenix模型在昇腾硬件64G单卡上可达到768的最大训练长度,并且最大单卡推理长度超过3000。如上图所示,基于昇腾硬件的Protenix模型的推理结果与实际蛋白质数据(PDB)的空间结构吻合。详细技术解读见《MindSpore Protenix 蛋白质结构预测模型的性能优化技术,助力训推性能提升50%+》
了解和体验新版本,请关注昇思社区官网。
昇思MindSpore官网:https://www.mindspore.cn/
昇思MindSpore2.8版本下载链接:https://www.mindspore.cn/install
上一篇
下一篇