业务挑战
MoE模型带来的模型推理挑战
MoE模型的专家通信All2All时延更大
在极端场景下,通信时延占整体时延的70%,导致推理的文本输出时延大,对话缓慢。
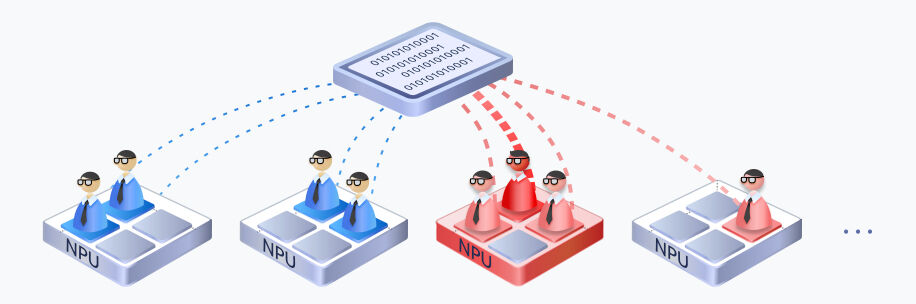
MoE模型专家负载不均衡,推理效率低
由于路由的随机性,部分专家过分热门,其他NPU处于闲置等待,拖慢了整体的推理业务,算力利用率低。

MoE模型内存占用大,导致性能瓶颈
以DeepSeek-R1 671B为例,700GB模型权重常驻内存,且KVCache碎片化分布,空闲内存少,推理性能瓶颈。
解决方案
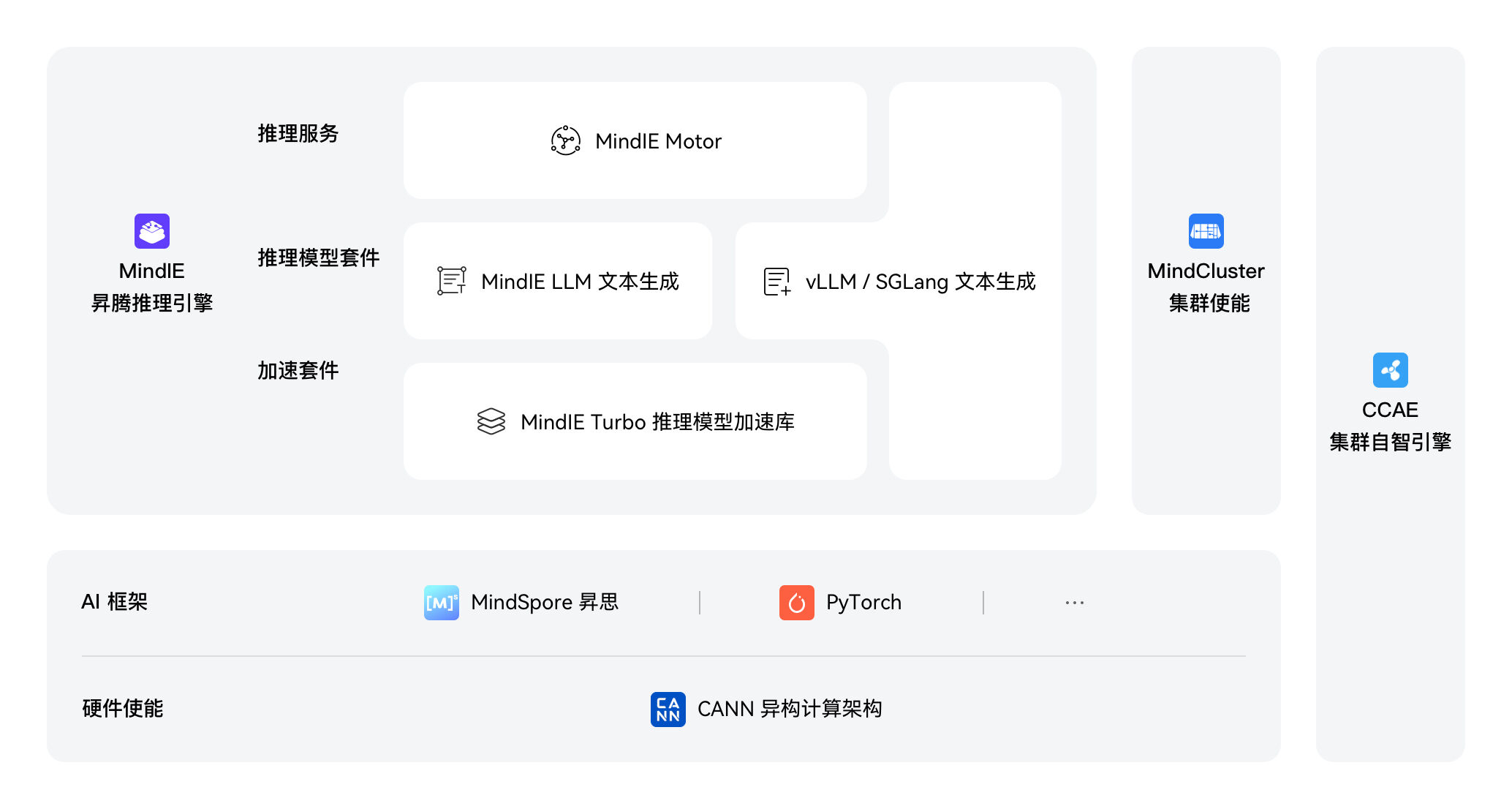
大规模专家并行解决方案
MoE推理最优解,相比常规服务器堆叠,大规模专家并行可实现2到4倍的单卡吞吐提升,降低50%+系统时延,在相同卡数下获得更大的收益,实现“一份投入,多份输出”
64卡大规模专家并行
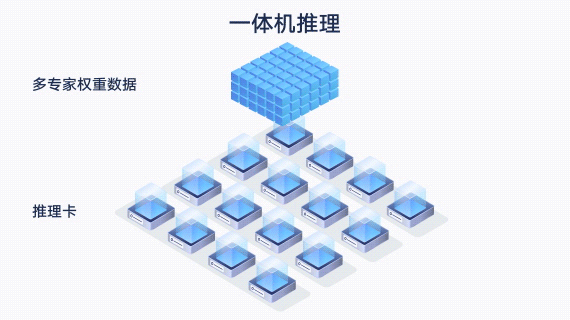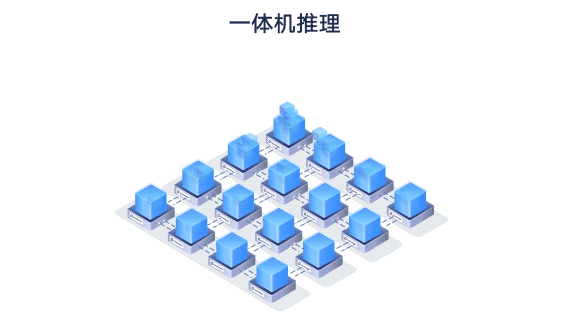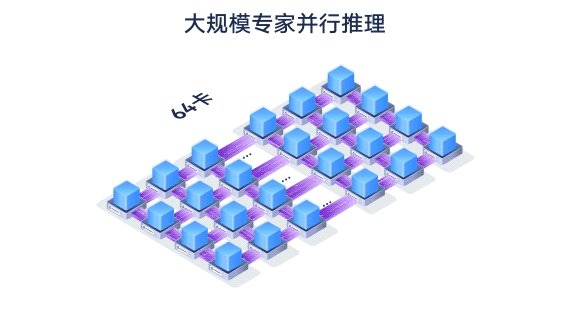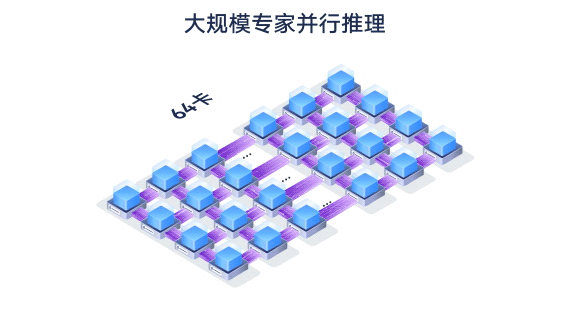
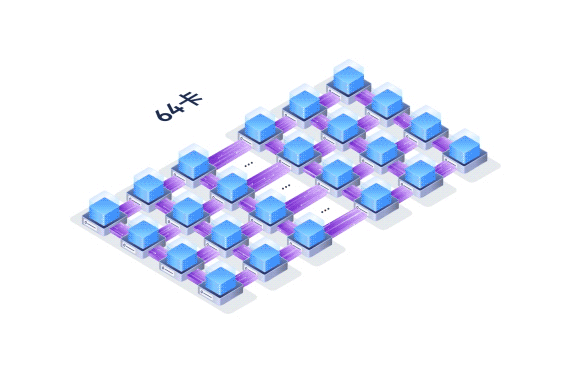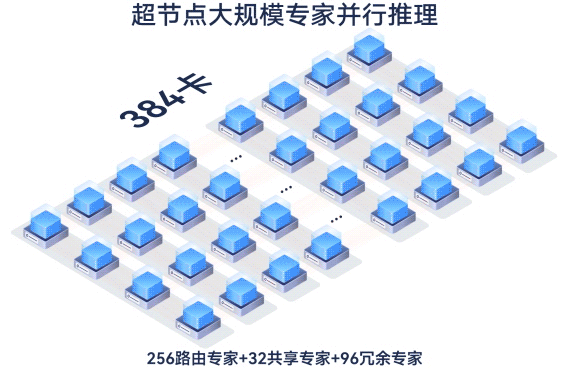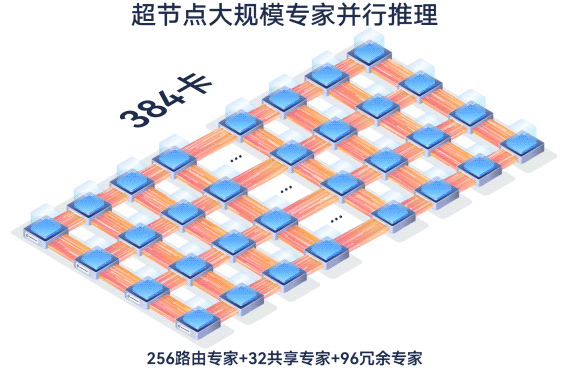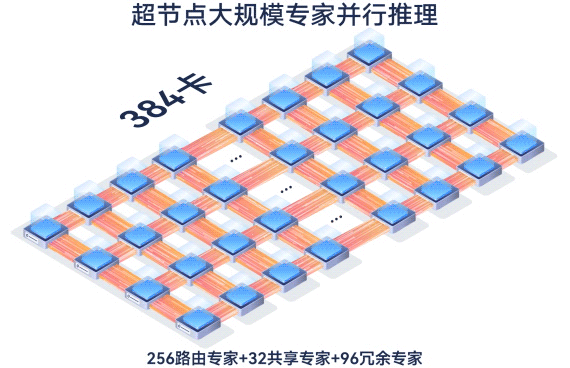
384卡大规模专家并行
方案亮点
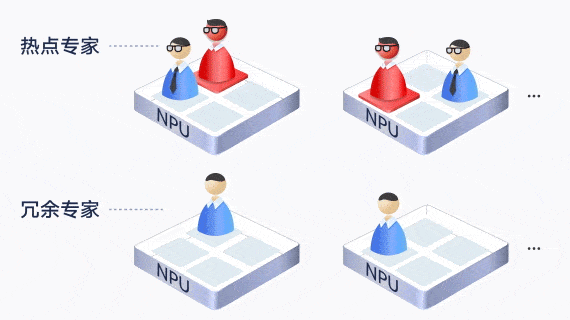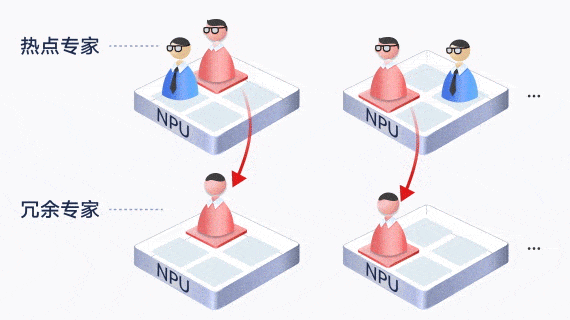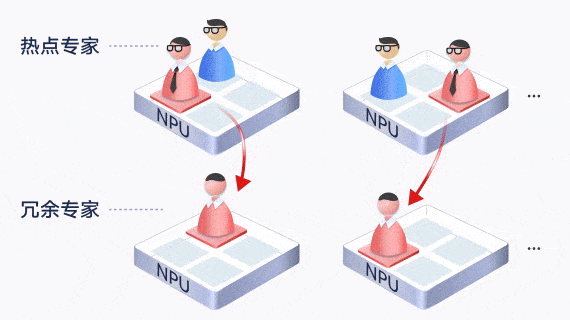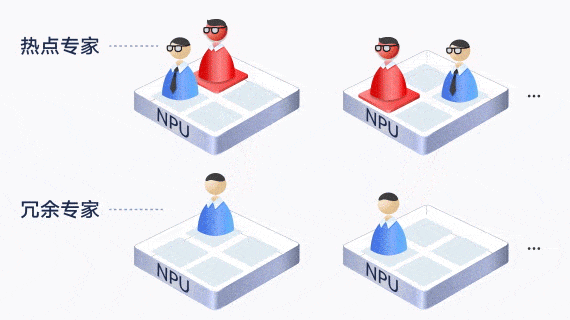
动态专家负载均衡
MoE中专家负载容易不均,导致某个专家负载过高,阻塞整体的推理进度。昇腾通过EPLB动态专家负载均衡,在线统计和分析热点专家,实时分配和调节冗余专家分担负载,有效降低了热点专家的阻塞。
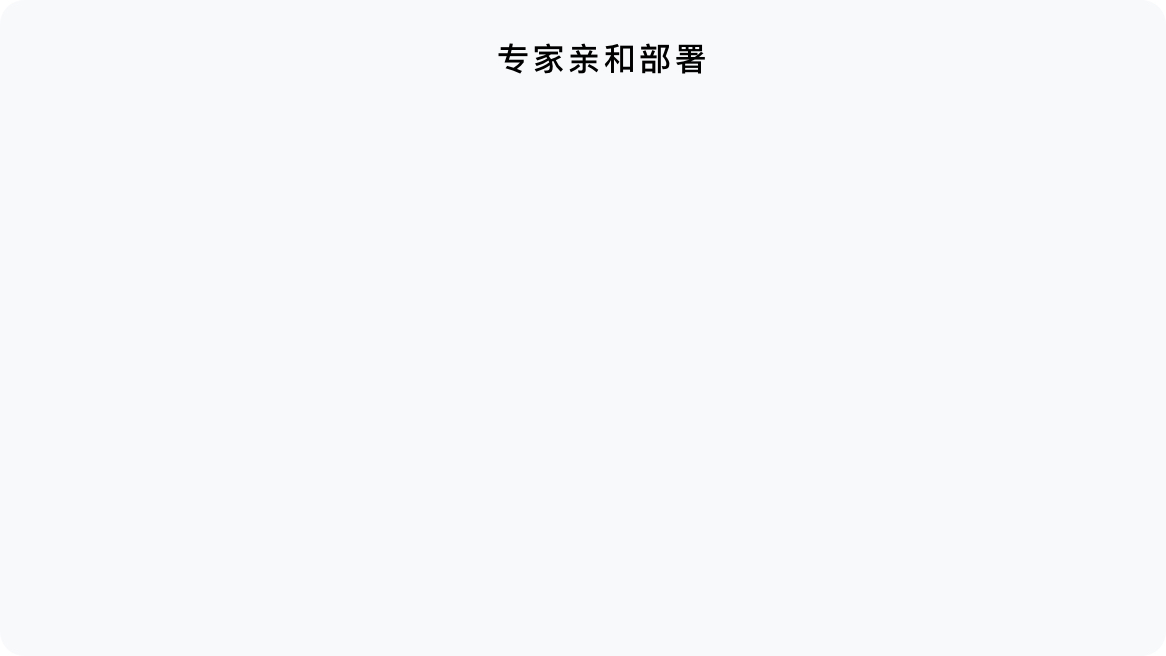
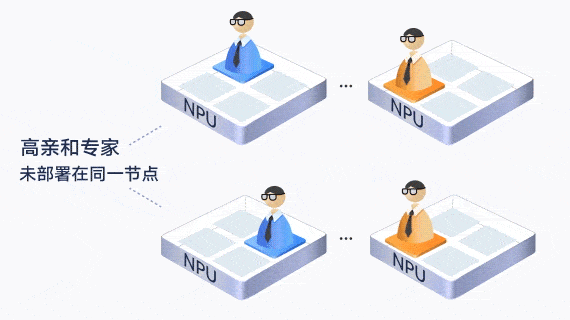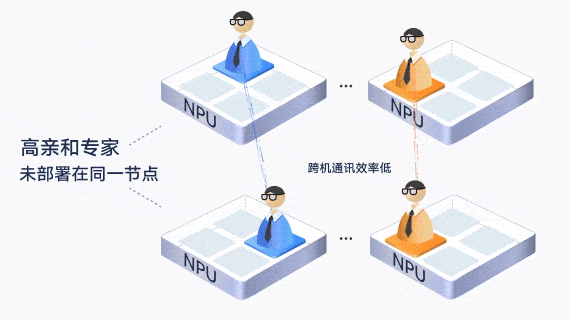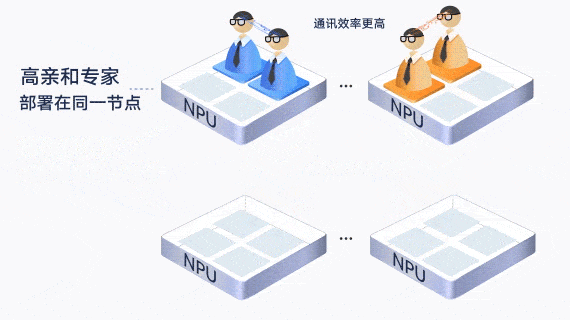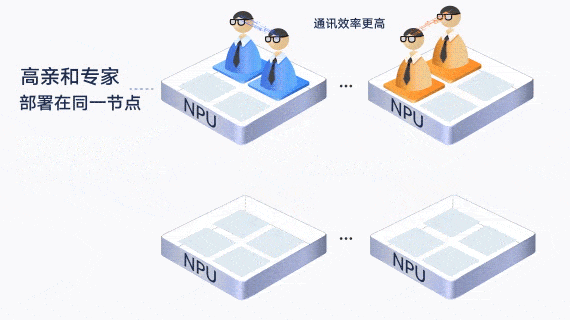
此外,通过让通信较为频繁的“亲和”专家部署在一张卡内或一个服务器内,减少了跨卡和跨机的通信。
通过这些专家调节技术,均衡了每个专家的计算量,负载峰均比从最大8降低到1.4,同时减少了30%的通信数量,提升了硬件资源利用率,使得集群的推理时延更低,支持更大的吞吐性能。