




DeePMD工作流程
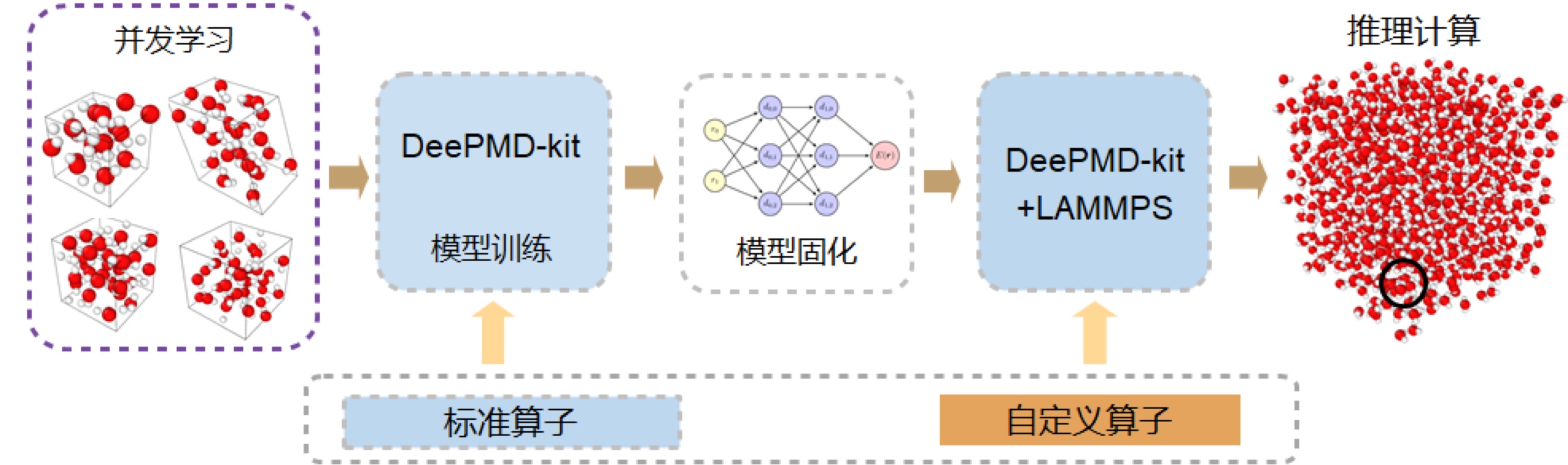
分子运动的模拟跟场景息息相关,每个场景下都需要重新进行模型训练。DeePMD-Kit提供了方便的模型训练手段,将训练好的模型进行固化,然后再执行推理。
自定义高性能算子
开发人员基于CANN的算子编程接口,在DeePMD网络中开发了自定义高性能算子,涉及到数据排序、读取与存储等离线操作,也涉及矩阵、标量的计算,这些自定义算子不但对精度有较高的要求,而且很大程度上决定了模型整体的性能。
CANN能够高效协同昇腾不同异构单元自定义高性能算子,充分释放AI Core、AI CPU和Vector Core的异构算力。比如将离散的距离计算和排序部署在AI CPU上,将可以并行的矩阵、标量的计算部分部署在AI Core上,以发挥出每个计算单元的能力,充分发挥硬件计算性能。
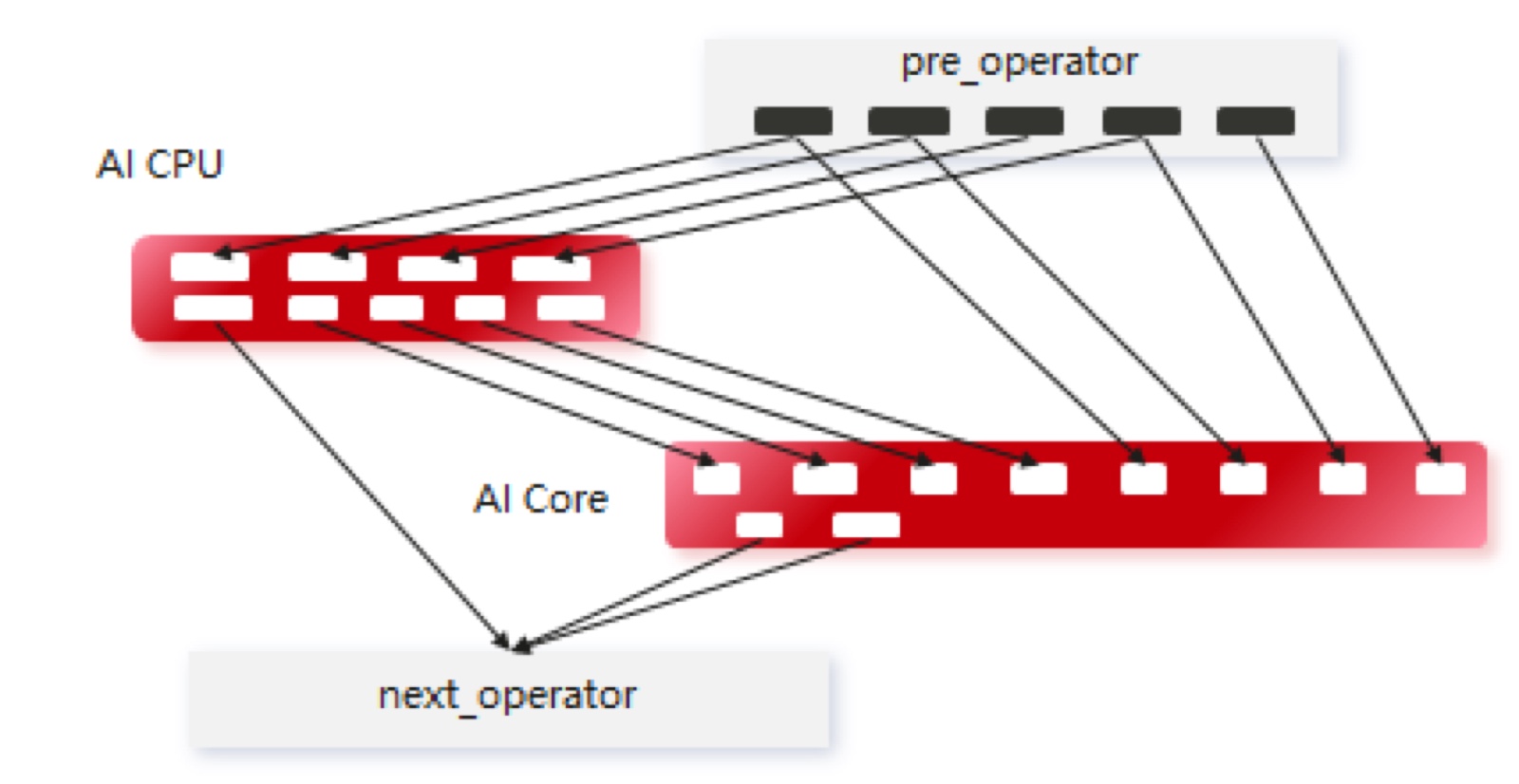
高效协同昇腾不同异构单元自定义高性能算子
网络优化
在DeePMD原生实现中,算子融合是网络性能优化的另一重要手段。算子开发人员结合网络特点,借助CANN设计新的融合规则,包括PAD算子支持动静合一、Mul支持NZ+ND和ND+NZ、MatMul + Add + TanhGrad支持Buffer融合等,这些融合在整网性能提升中起到了关键作用。同时借助CANN的智能调优工具AOE,自动化完成子图调优、算子调优,以及TransData消除等一系列优化,极大提升了模型调优效率。
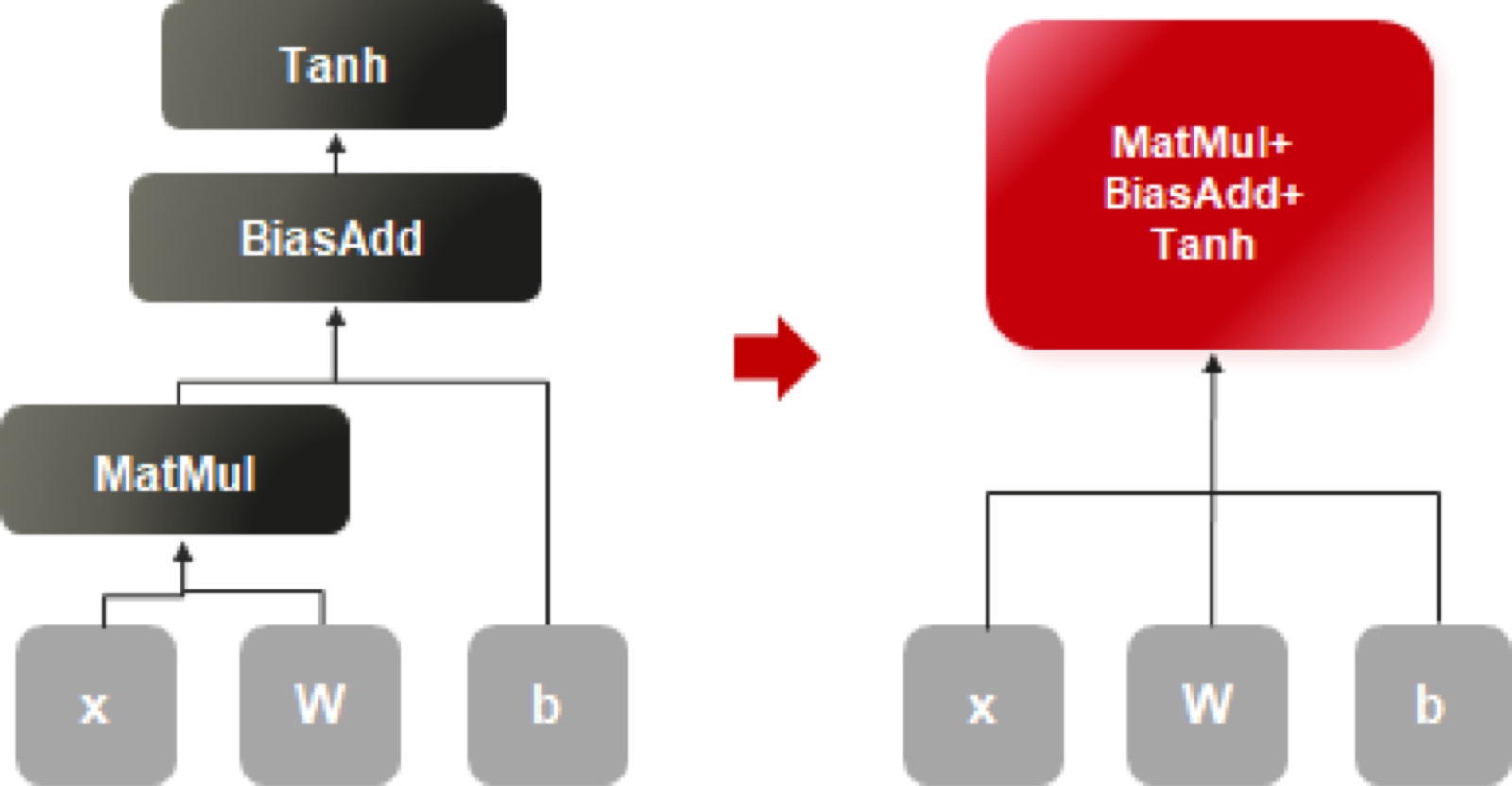
DeePMD网络融合示例
模拟结果
在不同场景对分子模拟的物理性质与仿真结果对比测试中,以铜拉伸应力应变模拟实验为例可以看到,昇腾AI基础软硬件平台的实验结果已经非常近似实际数据。
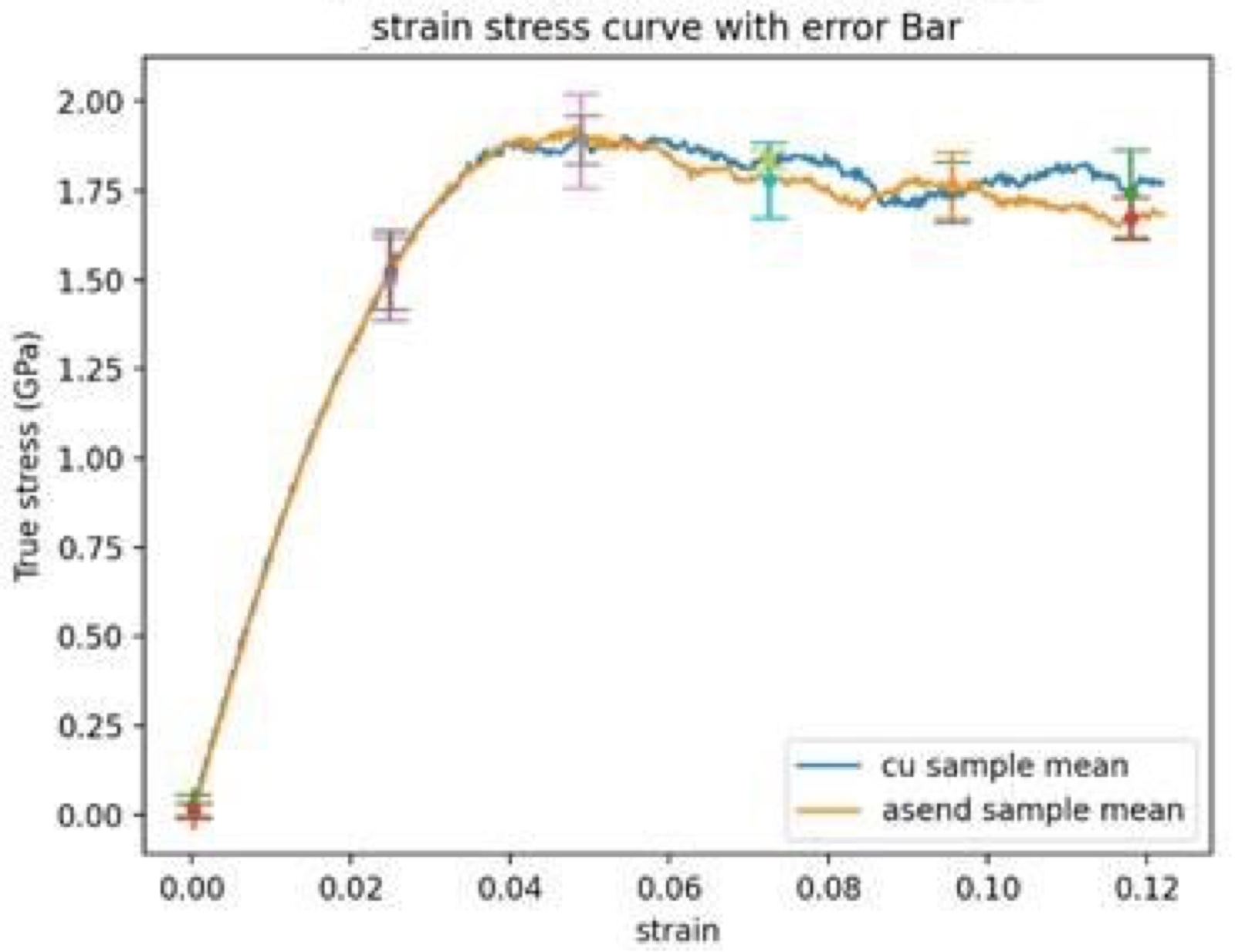
昇腾AI基础软硬件平台上铜的拉伸应力应变模拟结果
昇腾AI的整体优化解决方案使DeePMD-kit工具在分子动力学模拟计算上取得较现有产品1.5倍以上的性能提升成果,助力了分子动力学服务成功商用。