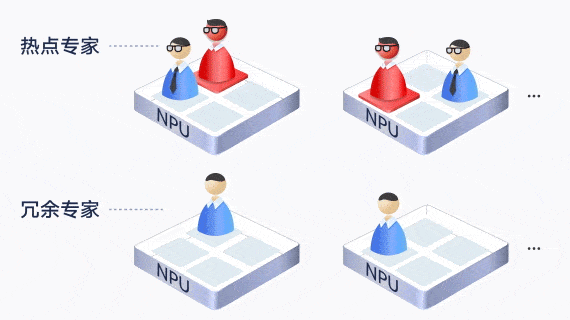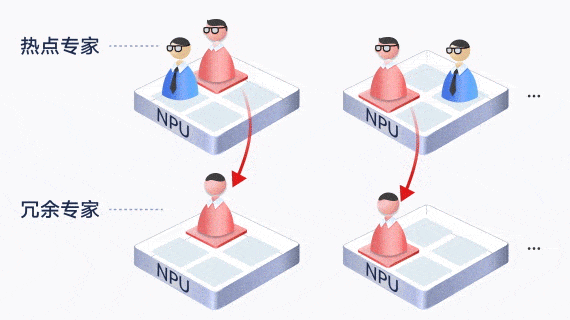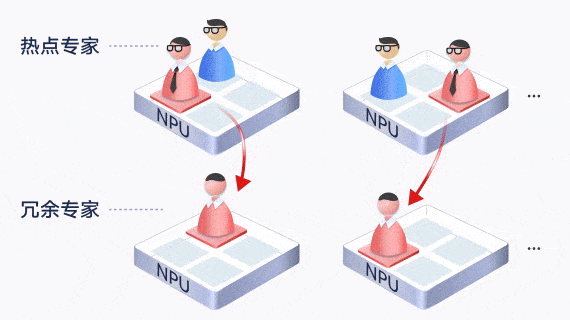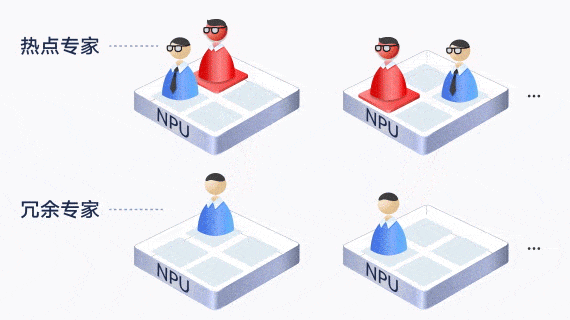
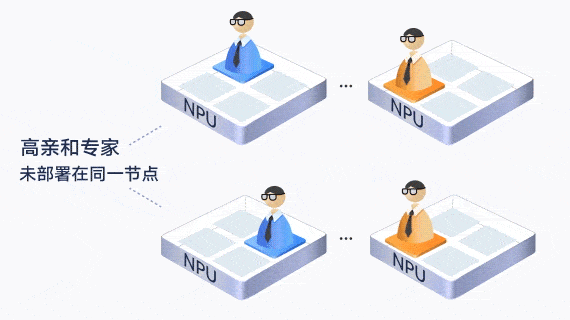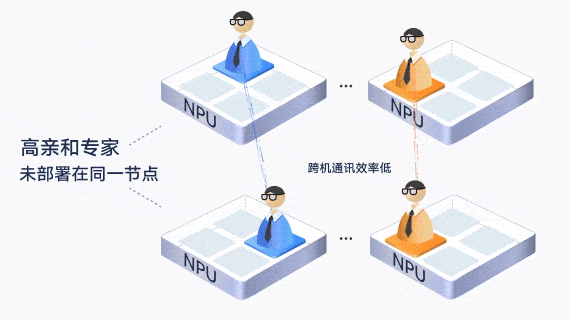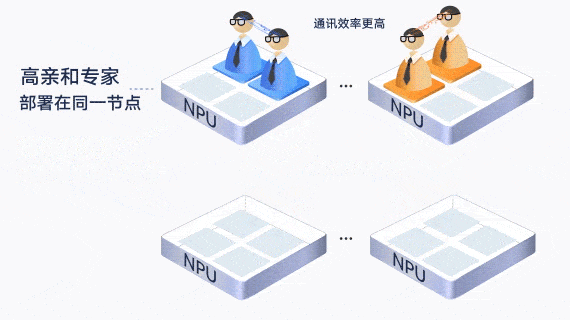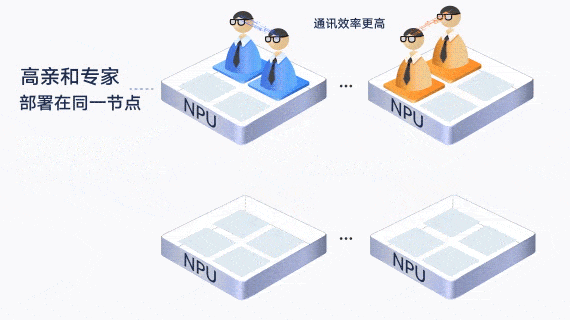
largeModelSolution.text7
largeModelSolution.text8
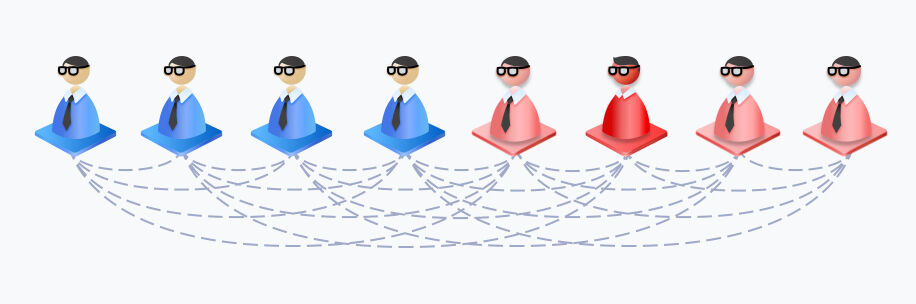
largeModelSolution.text9
largeModelSolution.text10
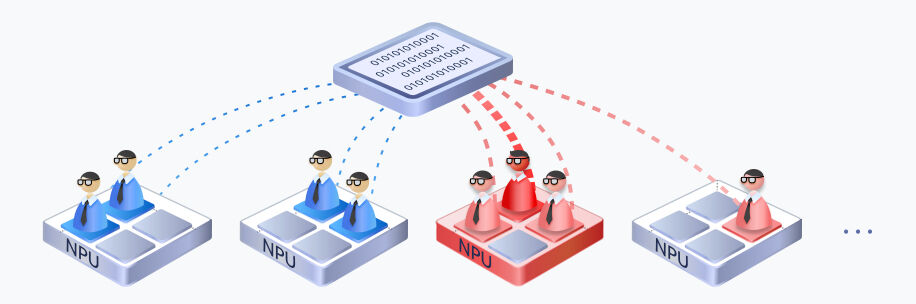
largeModelSolution.text11
largeModelSolution.text12

largeModelSolution.text13
largeModelSolution.text14
largeModelSolution.text34
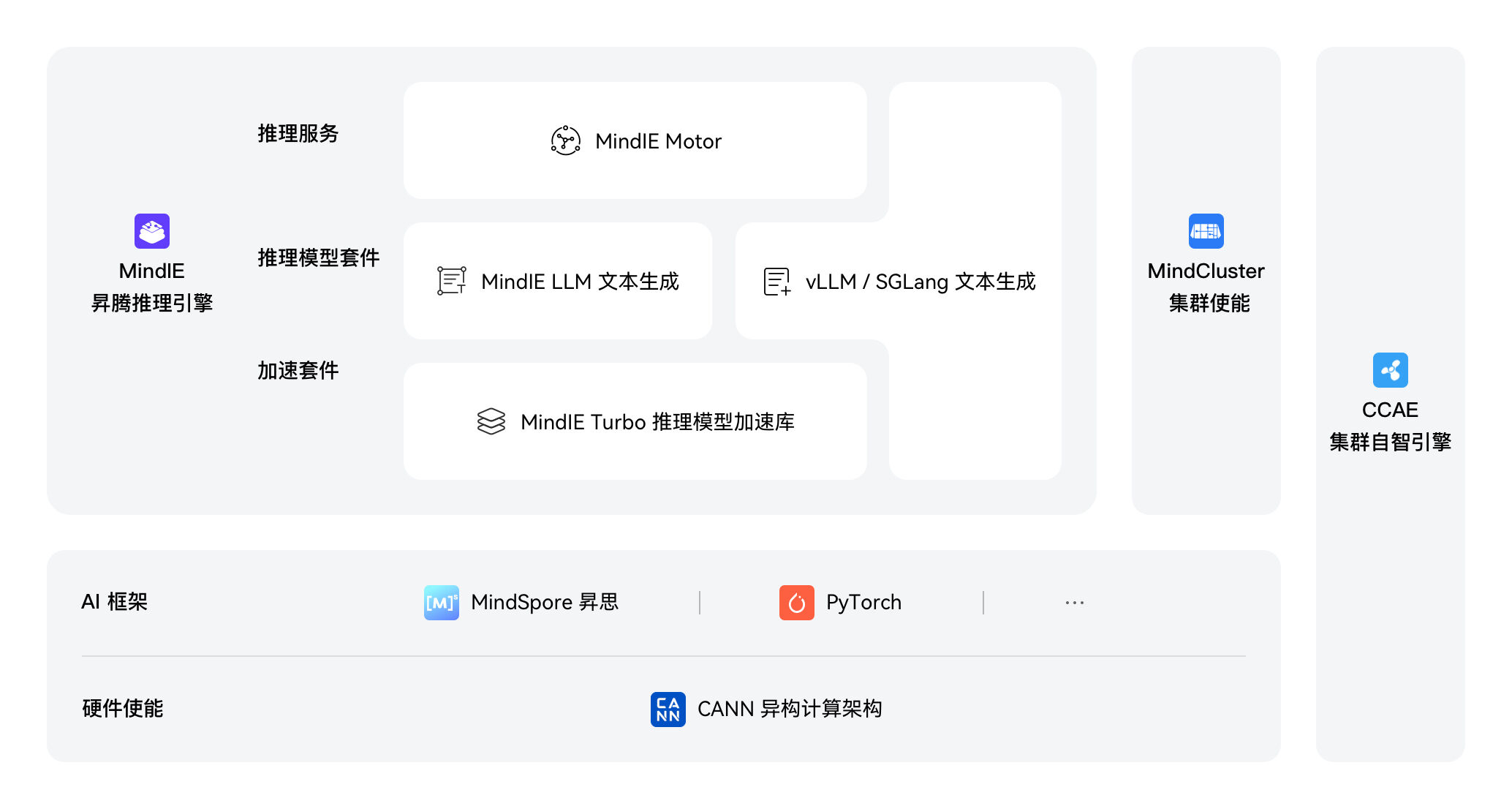
largeModelSolution.text1
largeModelSolution.text35
largeModelSolution.text36
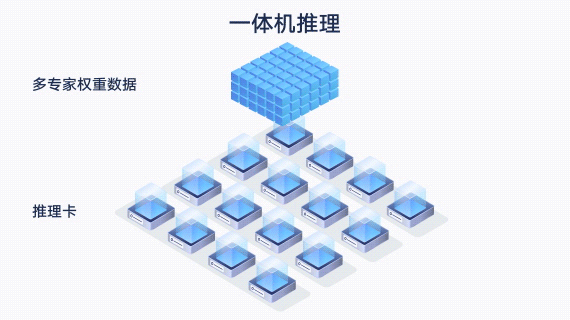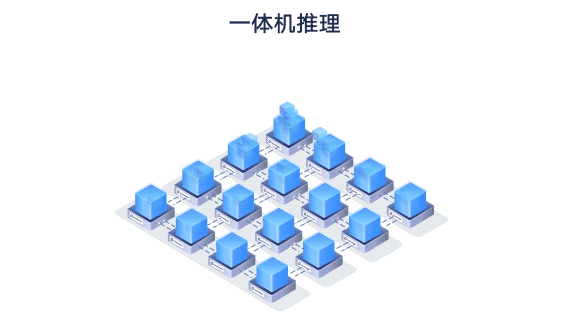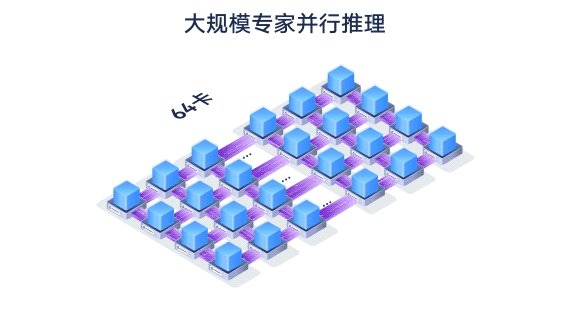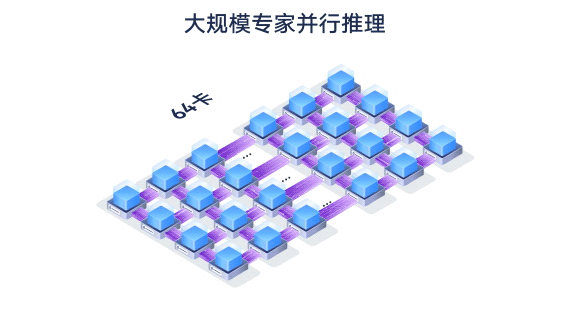
largeModelSolution.text37
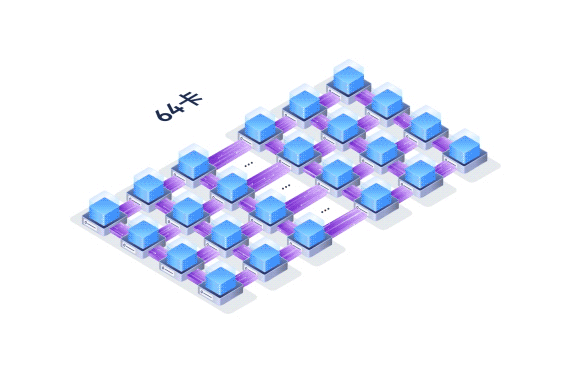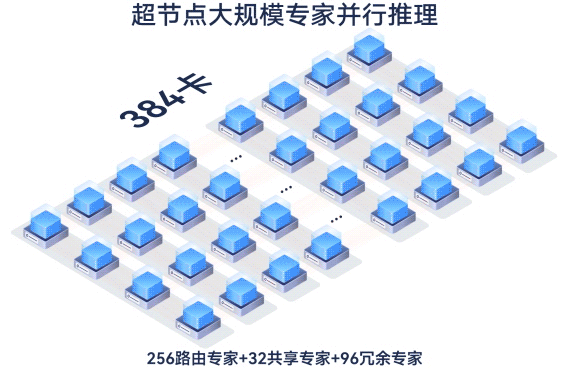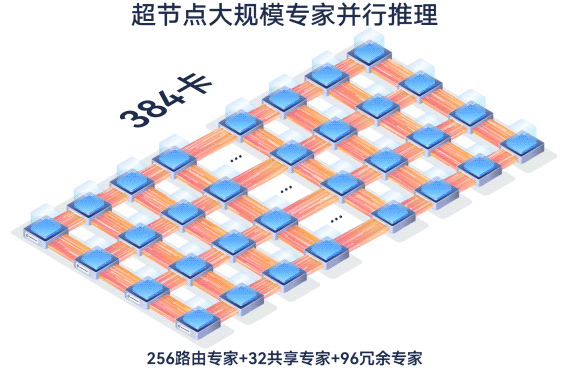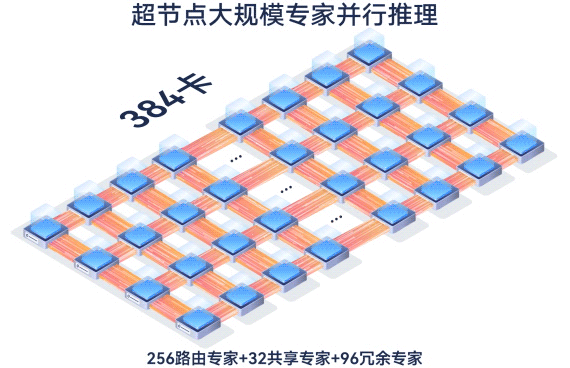
largeModelSolution.text15
largeModelSolution.text16
largeModelSolution.text17
largeModelSolution.text18
largeModelSolution.text19