全新开发
场景描述
全新开发,指CANN算子库中不包含相应的算子,需要先完成自定义算子的开发,再进行第三方框架的适配。可以查看《AOL算子加速库接口参考》,判断算子库是否包含对应算子。
若用户开发的自定义算子仅用于构造Ascend Graph或者通过AscendCL进行单算子调用,则无需进行第三方框架的适配(即如下开发流程中的“算子适配插件开发”)。
开发流程
通过MindStudio工具进行自定义算子开发的流程,与命令行方式进行自定义算子开发的流程相同。
全新开发场景下,开发的流程如下所示:
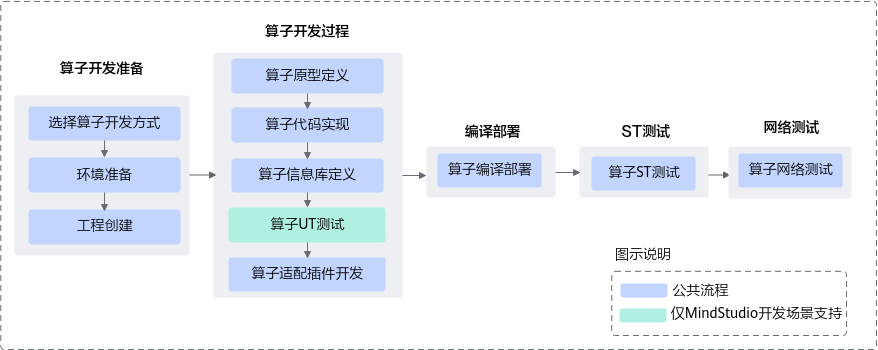
序号 |
步骤 |
描述 |
参考 |
|---|---|---|---|
1 |
选择算子开发方式 |
进行算子分析,选择通过什么方式进行算子开发,例如TBE DSL、TBE TIK还是AI CPU。 |
|
2 |
环境准备 |
准备算子开发及运行验证所依赖的开发环境与运行环境。 |
|
3 |
工程创建 |
创建算子开发工程,有以下几种实现方式:
|
|
4 |
算子原型定义 |
算子原型定义规定了在昇腾AI处理器上可运行算子的约束,主要体现算子的数学含义,包含定义算子输入、输出、属性和取值范围,基本参数的校验和shape的推导,原型定义的信息会被注册到Graph Engine的算子原型库中。离线模型转换时,GE会调用算子原型库的校验接口进行基本参数的校验,校验通过后,会根据原型库中的推导函数推导每个节点的输出shape与dtype,进行输出tensor的静态内存的分配。 |
|
5 |
算子代码实现 |
||
6 |
算子信息库定义 |
算子信息库文件用于将算子的相关信息注册到算子信息库中,包括算子的输入输出dtype、format以及输入shape信息。离线模型转换时,FE会根据算子信息库中的算子信息做基本校验,判断是否需要为算子插入合适的转换节点,并根据算子信息库中信息找到对应的算子实现文件进行编译,生成算子二进制文件进行执行。 |
|
7 |
算子UT测试 |
仿真场景下验证算子实现代码、算子原型定义的功能及逻辑正确性。 UT测试当前仅支持基于MindStudio进行算子开发的场景。 |
|
8 |
算子适配插件开发 |
基于第三方框架(TensorFlow/Caffe)进行自定义算子开发的场景,开发人员需要进行插件的开发,将基于第三方框架的算子映射成适配昇腾AI处理器的算子。 |
|
9 |
算子编译部署 |
编译自定义算子工程,生成自定义算子安装包并进行自定义算子包的安装,将自定义算子部署到算子库。 |
|
10 |
算子ST测试 |
系统测试(System Test),在真实的硬件环境中,验证算子的正确性。 |
|
11 |
算子网络测试 |
将自定义算子加载到网络模型中进行运行验证。 |