分布式训练脚本适配(兼容单卡)
NPU上的分布式部署形态如下图所示,每个Tensorflow进程只管理独享的一张NPU训练卡,多个Tensorflow进程间,通过CANN提供的集合通信接口进行集群同步。单独观察某个worker,可以发现其与NPU上的单卡训练,除额外进行了集群内的集合通信外完全一致。
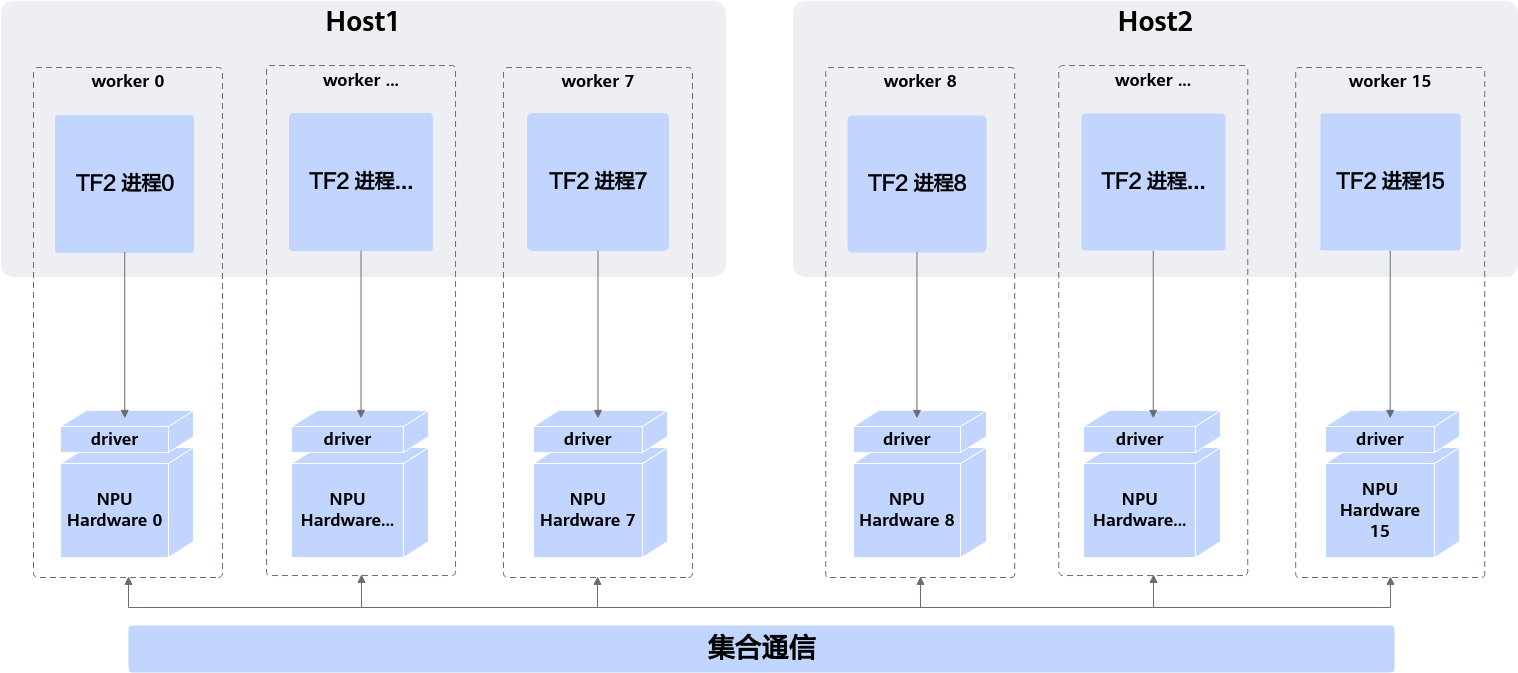
TF Adapter适配时,将单卡NPU视作集群worker数量为1的分布式部署形态,因而NPU的单卡脚本和分布式脚本最终是一致的。
NPU上执行分布式,相较于单卡NPU训练,主要有三部分的额外适配工作:
- worker间变量初值同步
TF2 Eager模式下,变量在模型生成后即完成初始化,此时需要进行变量初值同步操作,使各个worker上的变量初值一致。
在模型构建完成后,您应当调用npu.distribute.broadcast接口完成变量初值同步,该接口要求传入需要进行worker间值同步的变量,通常,您可以通过model.trainable_variables来获取全部需要同步的变量。
- worker间梯度聚合
执行训练时,不同worker上产生不同的梯度信息grads,通过对多个worker上的梯度进行聚合计算,可以更准确地评估当前训练的误差情况。
- 不同worker上的数据集分片
分布式训练时,应当保证每个worker上评估的样本不同,这样才能使得训练结果更符合样本集真实分布,比如您在一个8卡NPU的集群中执行训练,此时一个典型的策略就是第一张NPU卡上训练0-1/8的数据,第二张NPU卡训练1/8-2/8的数据,最后一张卡上训练7/8-8/8的数据。
- 当数据集为tf.data.Dataset格式时,TF Adapter提供了npu.distribute.shard_and_rebatch_dataset接口帮您实现上述切分动作,该接口要求您传入需要进行集群切分的Dataset(Dataset介绍参考链接)以及集群训练时的全局batch大小,例如:
1 2 3 4 5 6 7 8 9 10 11
# 由于需要使用npu.distribue.shard_and_rebatch接口,在脚本开头import npu import npu_device as npu if input_context: logging.info( 'Sharding the dataset: input_pipeline_id=%d num_input_pipelines=%d', input_context.input_pipeline_id, input_context.num_input_pipelines) # 原始的shard逻辑,因为以单机CPU方式启动,所以不会进行实际的shard dataset = dataset.shard(input_context.num_input_pipelines, input_context.input_pipeline_id) # NPU添加的shard逻辑,会根据集群数量,对数据集和全局batch进行切分 dataset, batch_size = npu.distribute.shard_and_rebatch_dataset(dataset, batch_size)
- 当数据集为Numpy数组时,需要调用numpy方法手工对数据集和全局batch进行切分,例如:
1 2 3 4 5 6 7 8 9 10 11 12 13
(x_train, _), (x_test, _) = keras.datasets.mnist.load_data(os.path.join(args.data_path, 'mnist.npz')) # 根据设备数量均分数据集 x_trains = np.split(x_train, args.rank_size) # 按设备编号取对应的数据集分片 x_train = x_trains[args.device_id] x_tests = np.split(x_test, args.rank_size) x_test = x_tests[args.device_id] # 对全局batch进行切片 batch_size = args.batch_size // args.rank_size mnist_digits = np.concatenate([x_train, x_test], axis=0) mnist_digits = np.expand_dims(mnist_digits, -1).astype("float32") / 255
- 当数据集为tf.data.Dataset格式时,TF Adapter提供了npu.distribute.shard_and_rebatch_dataset接口帮您实现上述切分动作,该接口要求您传入需要进行集群切分的Dataset(Dataset介绍参考链接)以及集群训练时的全局batch大小,例如:
父主题: 手工迁移