



问题现象描述
在训练和推理的过程中,往往第一个epoch的耗时会比其他epoch大得多,因为第一个epoch存在大量的算子编译耗时。
在PyTorch中,可以通过二进制使能的方式,在第一个epoch时跳过编译,复用之前已经编译的二进制文件,从而节省大量编译时间。
- PyTorch算子二进制复用步骤。
在导入torch_npu后或者在main入口函数添加“torch.npu.set_compile_mode(jit_compile=False)”。
该语句会在需要编译算子时,判断是否可复用的二进制文件,其整体判断流程如下:
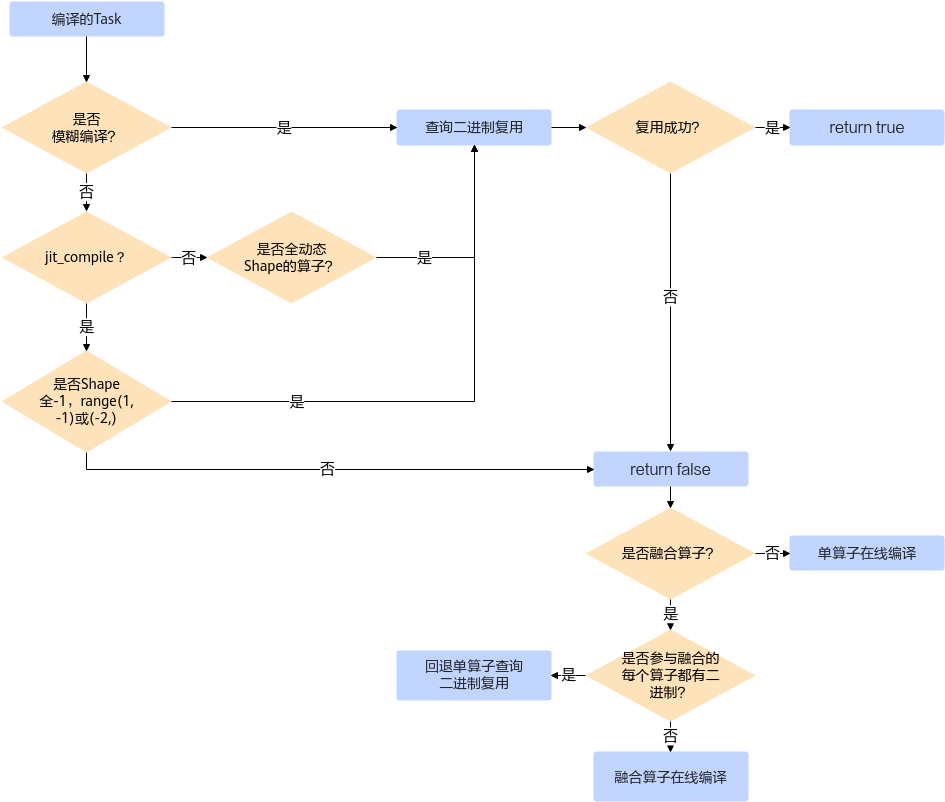
- 日志查询。
如果出现“No need to compile”,则代表复用成功。
出现“need to compile”,则代表复用失败。
- 复用失败案例。
在某个ACL应用中,已加入“torch.npu.set_compile_mode(jit_compile=False)”代码。
但是在对同一份数据运行多次推理程序,都无法正常复用二进制文件,每次都需要重新花大量时间进行编译。
原因分析及排查方法
- 排查原因。
经过排查,发现日志中出现“Node(%s) version does not match with opc version. Need to compile.”。
其对应原因是二进制和在线编译version版本不匹配。
- 可能原因。
虽然报错显示是版本不匹配问题,但是该问题下程序每次运行编译的算子应该是一致的,不应该会出现不能复用的情况。
所以猜测有可能是虽然程序在重复执行,但程序没有搜索到上一次执行时编译算子所生成的二进制文件。
解决措施
发现ACL应用中的配置文件中指定了代码运行环境的路径,该路径以系统的当前时间命名,每次运行编译的算子二进制文件缓存都会存放在该目录下。

由于每次运行的时间不一样,程序每次推理时,都会在新的目录下搜索是否存在可复用的二进制文件,而之前的二进制存在上一个时间的目录中,导致无法找到之前的编译的二进制文件。
将程序的运行环境路径修改为一个固定路径后,成功解决了算子二进制复用失败问题。
