



开源即支持!昇腾极速适配Qwen3.6,高效训练复现及推理部署
产业
发表于 2026/04/17
产业
发表于 2026/04/17
2026年4月16日,阿里通义千问团队正式发布了Qwen3.6系列模型。作为Qwen系列的最新旗舰版本,Qwen3.6-35B-A3B在Agentic Coding(智能编码代理)和Thinking Preservation(推理上下文保留)两大核心方向上实现了显著突破,面向开发者提供了更直观、更高效的大模型体验。
此前昇腾系列产品一直同步支持Qwen系列模型,此次Qwen3.6模型一经开源发布,昇腾就基于Atlas 900 A3 SuperPoD液冷超节点、Atlas 800 A3风冷超节点等全系列产品实现微调训练及强化学习复现,同时也支持基于vLLM在昇腾全系列产品上高效推理部署。
2.1 模型亮点
Qwen3.6是继2026年2月发布的Qwen3.5系列之后,Qwen系列的首个3.6版本开源模型。Qwen3.6 侧重于稳定性和实用性,为开发者带来以下核心升级:
• Agentic Coding(智能编码代理):模型在前端工作流和仓库级推理方面具有更强的流畅性和精确性,可处理更复杂的编码任务。
• Thinking Preservation(推理上下文保留):引入了保留历史消息推理上下文的新选项,可有效减少迭代开发中的冗余推理开销,降低 Token 消耗。
• 原生多模态:内置 Vision Encoder,原生支持文本、图像、视频的多模态输入,无需额外插件。
2.2 模型架构
Qwen3.6-35B-A3B采用 MoE (Mixture of Experts) 混合专家架构,在保持强大模型能力的同时大幅降低推理成本。模型总参数量为350亿,但每次推理仅激活约30亿参数(A3B),是极具性价比的大模型方案。
架构创新点说明:
•混合注意力机制:交替使用Gated DeltaNet(线性注意力)与标准Gated Attention,在计算效率和表达能力之间取得最佳平衡。
•高效 MoE 路由:256个细粒度专家中每次仅激活9个(8路由 + 1共享),推理FLOPs仅为稠密模型的约 1/10。
•多步Token预测(MTP):训练时采用多步预测分支,配合推测解码可进一步提升推理速度。
3.1 支持特性(vLLM Ascend)
当前Qwen3.6-35B-A3B在昇腾AI基础软硬件平台上的支持特性矩阵如下:
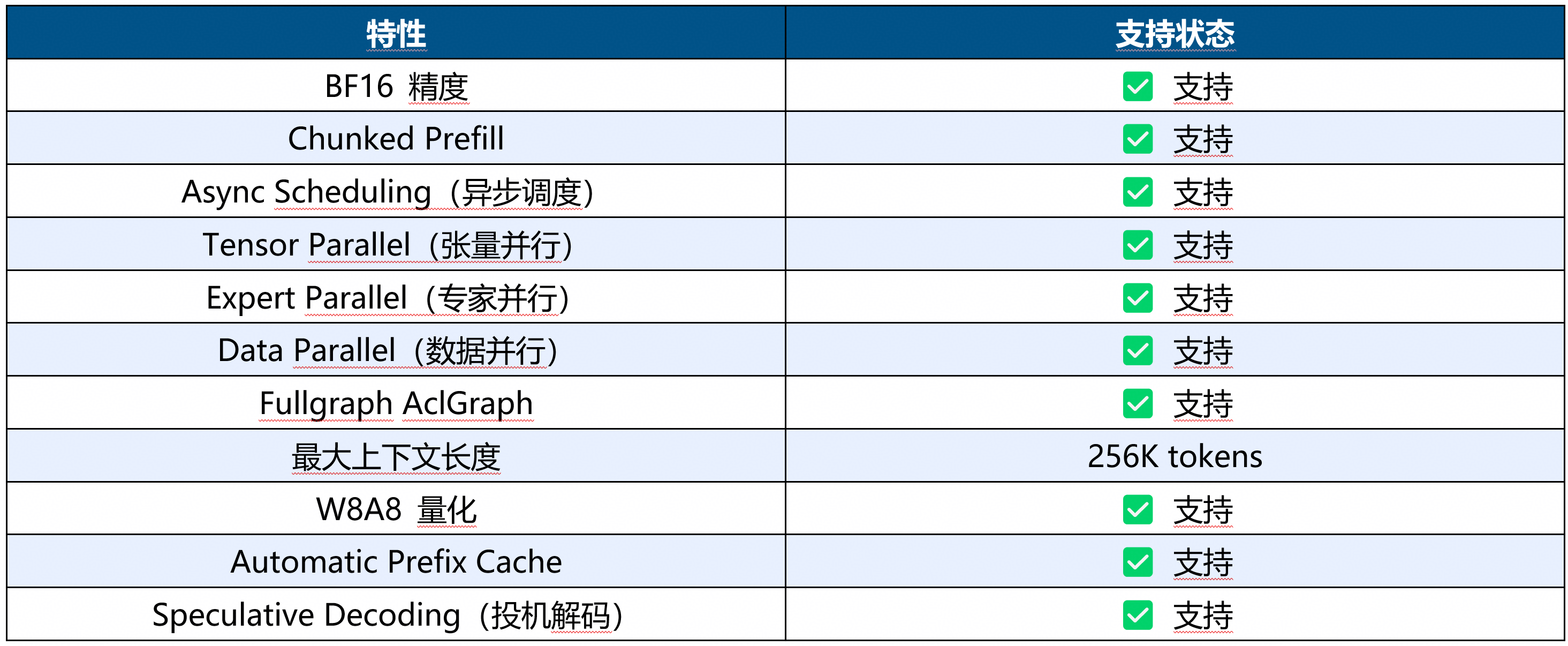
3.2 支持硬件
•昇腾A3、A2全系列产品
3.3基于vLLM Ascend部署指南
vLLM社区维护的昇腾硬件插件,遵循vLLM的硬件可插拔架构设计,使得Transformer、MoE、多模态等主流开源模型可以无缝运行在昇腾NPU上。
vLLM部署指南可参见魔乐社区链接:https://modelers.cn/models/vLLM_Ascend/Qwen3.6-35B-A3B
重要说明:
•当前为0Day尝鲜适配版本,性能持续优化中。
•Qwen3.6 默认启用Thinking 模式(思考模式),在响应前会生成 <think>...</think> 推理内容。如需直接响应,可通过 API 参数 enable_thinking: False 关闭。
•本文档提到的数据集和模型仅作为示例,这些数据集和模型仅供您用于非商业目的。
Qwen3.6原生支持多模态,具备强大的多模态感知与推理能力, 昇腾支持基于Qwen3.6模型做微调训练和强化学习训练,助力客户打造行业专属模型。
4.1 支持特性
1、微调特性(MindSpeed MM)
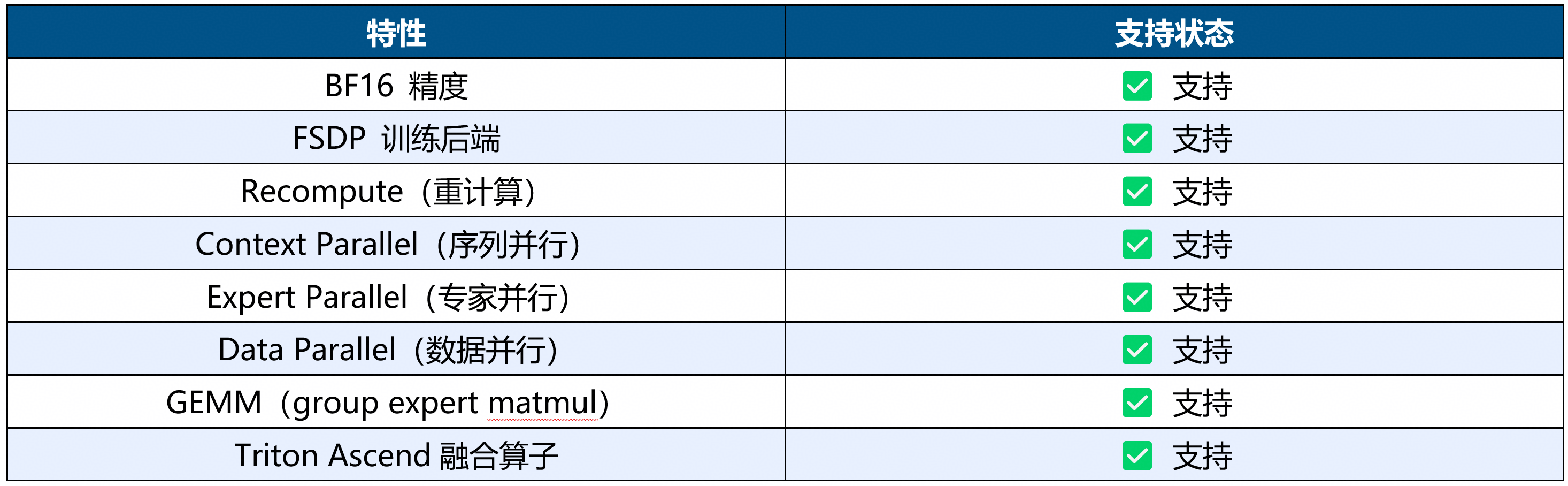
2、RL特性(verl)
昇腾原生合入verl社区,支持verl FSDP2原生后端,同时,为了显著提升昇腾硬件上的训练效率,我们为verl新增支持NPU加速设计的 MindSpeed MM后端,为用户提供灵活高效的训练后端选择。
1)支持verl FSDP2原生后端,参数级分配的分布式训练能力
verl FSDP2是verl框架内置的分布式训练后端,基于PyTorch原生的torch.distributed.fsdp API实现,其核心特点包括:
参数分片:将模型参数、梯度和优化器状态分片到多个NPU,显著降低单卡显存占用;
与vLLM无缝协同:作为verl原生后端,FSDP2与vLLM推理引擎天然兼容,支持训练与推理混合流水线;
易用性:无需额外安装,开箱即用。
针对Qwen3.6-35B-A3B模型,我们基于FSDP2后端完整适配与GRPO训练验证,打通从模型加载、分布式初始化到GRPO组采样与优势函数计算的完整链路,为后续后端优化提供了功能正确的基线。
2)verl支持MindSpeed MM后端,昇腾亲和加速特性开箱即用
MindSpeed MM是昇腾团队自研专为NPU设计的高性能多模态训练套件,其通过解耦并行策略与模型架构,实现FSDP、EP和CP三维并行能力的自由组合,降低大模型训练的工程复杂度与配置门槛。同时深度融合昇腾亲和融合算子(GEMM、Triton Ascend等)与显存管理技术(如Async Offload异步卸载),显著提升强化学习训练吞吐量与资源利用率。我们为verl框架新增支持MindSpeed MM后端,充分挖掘昇腾硬件潜能,为强化学习训练性能再上一个台阶。
4.2 支持硬件
•Atlas 800T A3风冷超节点
•Atlas 900 A3 SuperPoD液冷超节点
4.3部署指导
1、基于MindSpeed MM的微调训练部署指南:
MindSpeed MM多模态模型套件提供全新升级的一键快捷安装功能,无需复杂配置,git clone拉取代码后执行一行bash命令,即可完成CANN及运行依赖库的安装,在安装过程中支持交互式自定义安装。同时该套件将训练中用到的并行配置、训练配置、模型配置、数据配置进行集中整合。无须侵入式修改代码就能轻松使能优化特性(gemm、triton-ascend、chunk loss)、并行配置(FSDP、cp、recompute)、以及工具特性(profile、mem snapshot),轻松开启Qwen3.6系列模型训练创新。
欢迎根据部署指导链接体验:https://gitcode.com/Ascend/MindSpeed-MM/blob/master/examples/qwen3_6/README.md
2、基于verl框架的强化学习训练部署指南:
用户可基于自身需求通过以下两种训练后端方式,在昇腾NPU上快速体验Qwen3.6-35B-A3B模型的GRPO强化学习训练。
FSDP2后端方式:
环境安装指导:
https://modelers.cn/models/MindSpeed/qwen3.6/blob/main/README.md
一键启动脚本参考:
仓上qwen3.5模型脚本中的MODEL_PATH修改为qwen3.6的权重路径 https://github.com/verl-project/verl/blob/main/examples/grpo_trainer/run_qwen3_5_35b_vllm_fsdp_npu.sh
MindSpeed MM后端方式:
环境安装指导:
https://github.com/verl-project/verl-recipe/tree/main/grpo_mindspeed_mm
一键启动脚本参考:
仓上qwen3.5模型脚本中的MODEL_PATH修改为qwen3.6的权重路径 https://github.com/verl-project/verl-recipe/blob/main/grpo_mindspeed_mm/run_qwen3_5-35b_npu.sh
上一篇
下一篇