Job级别重调度
Job级别重调度即每次故障停止所有Pod,重新创建并重调度所有Pod后,重启训练任务。重调度模式默认为Job级别重调度。
了解Job级别重调度的关键配置步骤,请参见配置Job级别重调度。
使用约束
- 本功能仅支持在6.0.RC2及以上版本中使用。
- 请勿使用ConfigMap挂载RankTable文件,否则可能会导致任务重调度失败。
支持的产品型号和AI框架
产品类型 |
硬件形态 |
训练框架 |
|---|---|---|
Atlas 训练系列产品 |
|
|
Atlas A2 训练系列产品 |
|
|
Atlas A3 训练系列产品 |
|
|
A200T A3 Box8 超节点服务器 |
A200T A3 Box8 超节点服务器 |
|
重调度原理
训练过程中如果出现了软硬件故障,将导致训练状态异常。Job级别重调度首先销毁所有的训练容器,然后隔离故障设备,再重新将训练容器调度启动。训练容器重新启动后重新拉起训练,该行为类似训练首次拉起过程。
图1 原理图
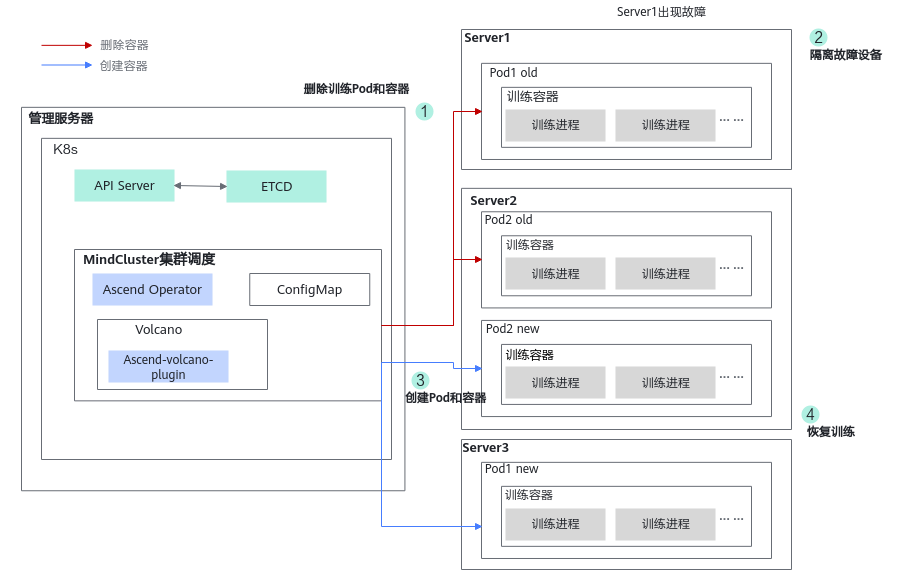
在以上原理图中,各个步骤的说明如下。
- 检测到故障后,首先删除当前任务所有的Pod和容器。
- 隔离故障所在的设备,防止再次使用该设备。
- 重新创建和调度训练Pod和容器。
- 容器启动后,拉起训练进程恢复训练任务。
父主题: 故障处理