纯搬运类算子VECIN和VECOUT建议复用
【优先级】高
【描述】纯搬运类算子在执行时并不涉及实际vector计算,若存在冗余的vector计算,会导致算子整体执行时间变长。这种场景可以使用Ascend C针对纯搬运类算子提供的TQueBind接口,该接口可以将VECIN和VECOUT之间绑定,省略将数据从VECIN拷贝到VECOUT的步骤,从而避免vector的无谓消耗。
【反例】
此代码片段中存在LocalTensor -> LocalTensor的DataCopy指令,目的是为了保证搬入和搬出之间的流水同步。
template <typename ComputeT> class KernelExample {
public:
...
__aicore__ inline void Process(...)
{
for (int i = 0; i < iLen; ++i) {
...
auto iLocal = QueI.AllocTensor<ComputeT>();
DataCopy(iLocal, inGm[i * 32], size);
QueI.EnQue(iLocal);
auto iLocal = QueI.DeQue<ComputeT>();
for (int j = 0; j < jLen; ++j) {
...
auto oLocal = QueO.AllocTensor<ComputeT>();
DataCopy(oLocal, iLocal, size); // LocalTensor -> LocalTensor的DataCopy指令,以实现数据从VECIN到VECOUT的搬移
QueO.EnQue(oLocal);
auto oLocal = QueO.DeQue<ComputeT>();
DataCopyPad(outGm[j], oLocal, ...);
QueO.FreeTensor(oLocal);
}
QueI.FreeTensor(iLocal);
}
}
private:
...
TQue<QuePosition::VECIN, BUFFER_NUM> QueI;
TQue<QuePosition::VECOUT, BUFFER_NUM> QueO;
...
};
extern "C" __global__ __aicore__ void example_kernel(...)
{
...
op.Process(...);
}
【正例】
将LocalTensor -> LocalTensor的DataCopy指令替换为TQueBind接口,避免将VECIN拷贝到VECOUT的步骤,从而避免了冗余vector计算。
template <typename ComputeT> class KernelExample {
public:
...
__aicore__ inline void Process(...)
{
for (int i = 0; i < iLen; ++i) {
...
auto bindLocal = queBind.AllocTensor<ComputeT>();
DataCopy(bindLocal, inGm[i * 32], size);
queBind.EnQue(bindLocal);
auto bindLocal = queBind.DeQue<ComputeT>();
for (int j = 0; j < len; ++j) {
...
DataCopyPad(outGm[j], bindLocal, ...);
}
queBind.FreeTensor(bindLocal);
}
}
private:
...
TQueBind<QuePosition::VECIN, QuePosition::VECOUT, BUFFER_NUM> queBind; // 使用TQueBind替换原来QueI,QueO
...
};
extern "C" __global__ __aicore__ void example_kernel(...)
{
...
op.Process(...);
}
【性能对比】
图1 aiv_vec_time优化前后对比
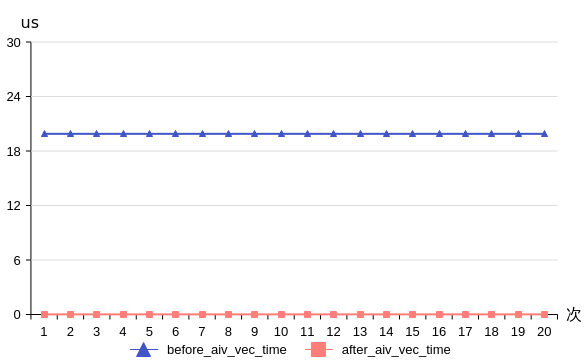
如上图所示,将反例中DataCopy指令替换为TQueBind之后有明显优化。由于省略了数据从VECIN拷贝到VECOUT的步骤,aiv_vec_time几乎缩减为0。
父主题: API使用优化