浮点异常检测
使用场景
训练网络执行过程中,可能发生频繁的浮点异常情况,即loss scale值下降次数较多或者直接下降为1,此时需要通过分析溢出数据,对频繁的浮点异常问题进行定界定位。
但在训练多个step的场景下,如果只是某个step出现了溢出,则可能是正常的偶发溢出,一般在开启loss scale的情况下,会自动跳过该step的训练结果,梯度不更新。对于这种偶发溢出场景一般可以不用关注。
溢出数据检测的主要过程如下所示。
图1 溢出数据检测流程

Dump溢出数据
以下操作在NPU训练环境执行。
- 修改训练脚本,使能算子溢出数据采集。
1 2
import precision_tool.tf_config as npu_tf_config npu_tf_config.npu_device_dump_config(npu_device, action='overflow')
注意:仅支持采集AI Core算子的溢出数据。
- 执行训练,如果网络存在溢出,则在precision_data/overflow/dump下会生成溢出信息文件。
溢出数据分析
溢出数据分析依赖CANN Toolkit软件包中的atc工具和msaccucmp.py工具,以下操作需要在CANN开发环境,即Toolkit安装环境进行。
- 将precision_tool和precision_data文件夹上传到Toolkit安装环境的任意目录下,目录结构示例:
├── precision_tool │ ├── cli.py │ ├── ... ├── precision_data │ ├── overflow │ │ ├── dump
- 安装Python依赖。
pip3 install rich
- 修改工具precision_tool/lib/config目录下的config.py。
# 依赖Toolkit包中的atc和msaccucmp.py工具,一般在run包安装目录,配置到父目录即可 # 默认Toolkit包安装在/usr/local/Ascend,可以不用修改,指定目录安装则需要修改 CMD_ROOT_PATH = '/usr/local/Ascend'
- 启动PrecisionTool交互命令行。
python3 ./precision_tool/cli.py
进入交互命令行界面:
PrecisionTool >
- 执行如下命令进行溢出数据分析,详细命令说明可参考precision_tool命令参考。
PrecisionTool > ac
根据数据量大小,分析过程需要时间不同,当执行过程中出现算子溢出,则会输出如下结果。
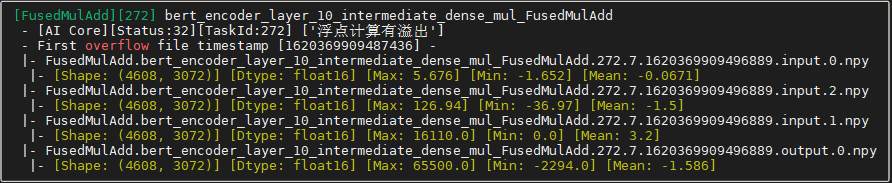
从上图可以看到:
- 算子名为:bert_encoder_layer_10_intermediate_dense_mul_FusedMulAdd
- 算子类型为:FusedMulAdd
- 溢出status信息为:32,表示浮点计算有溢出。
- 溢出类型为:AI Core算子溢出,另外还可能会有其他类型的算子溢出(例如DHA Atomic Add或L2 Atomic Add),建议用户优先考虑并解决AI Core算子溢出问题。
- 算子的输入输出信息,包括shape、dtype、输入输出数据的最大值最小值。

当出现多个算子溢出时,会出现N个溢出算子信息,默认按照算子执行顺序排序,由于后面算子溢出可能是因为前一个算子溢出导致,建议用户优先分析第一个异常算子。
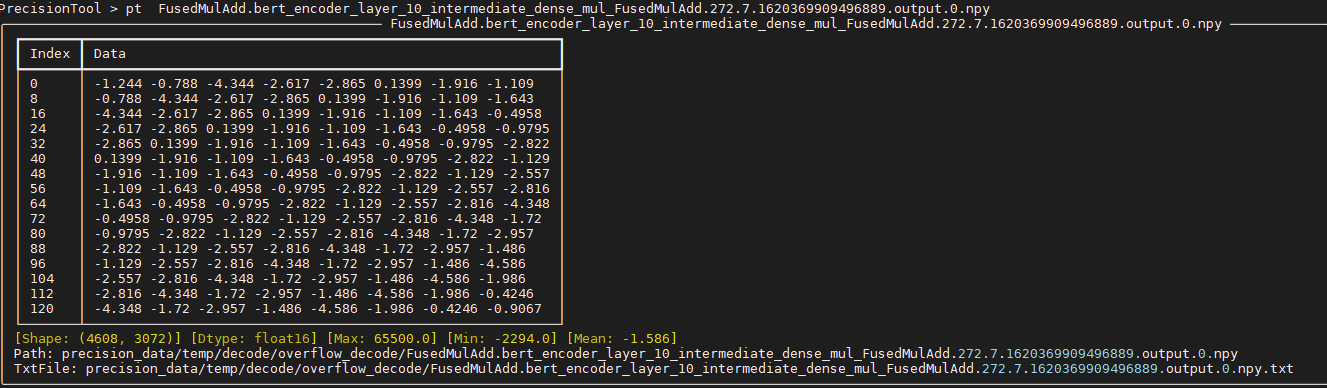
- 执行pt (-n) [*.npy]命令,可以查看对应dump数据块的数据信息。
分析思路参考
进行溢出数据分析前,我们先了解下不同昇腾产品的浮点数据溢出模式:
- Atlas 训练系列产品,浮点计算的溢出模式默认为“饱和模式”,且仅支持“饱和模式”。饱和模式为:计算出现溢出时,饱和为浮点数极值(+-MAX)。
- Atlas A2 训练系列产品,浮点计算支持两种溢出模式:饱和模式与INF/NAN模式,请保持默认值INF/NAN模式。饱和模式仅用于兼容旧版本,后续不再演进,且此模式下计算精度可能存在误差。
进行溢出数据分析的大致思路为:
- 查看输入输出数据值。
- 如果输入值中没有溢出值(饱和模式:65504/Nan;INF/NAN模式:Inf/Nan),输出数据中存在溢出值,则计算存在溢出。
- 如果输入值中存在溢出值,则需要继续分析前向算子或者用户模型的常量输入是否存在异常。
- 否则可能在计算过程中存在溢出。
- 查看溢出算子类型。
- 对于自定义开发的算子,可以尝试自行进行算子溢出分析(结合算子公式和溢出值进行分析),排查自定义算子是否存在问题。
- 对于CANN内置算子,也可以先尝试初步分析,如下为常用的分析方向:
- 如果算子输出类型为float16,解析出的输出数据中出现类似于65504/65500(饱和模式)或者Inf/Nan(INF/NAN模式),则可以切换输出算子类型至float32计算,用户可以尝试以下两种方法:
- 如果输入输出数据中均未出现溢出值,则需要结合算子公式,分析数据计算过程中是否可能出现溢出。例如AvgPool先求和再平均,求和过程可能溢出,但平均后并未溢出。
- 如果依旧无法解决,欢迎到昇腾社区提issue求助。
父主题: 精度调优