IterateBatch
功能说明
单次Matmul计算处理的shape比较小时,由于每次计算均涉及到内部的通信,可能会影响性能,该接口提供批量处理Matmul的功能,调用一次IterateBatch,可以计算出多个singleCoreM * singleCoreN大小的C矩阵。
在使用该接口前,需要了解一些必备的数据排布格式:
- 通用数据格式:BMNK的数据排布格式
- BSH/SBH:B:Batch,批处理的大小; S:sequence length,序列长度;H = N * D,其中,N为head的数量,D为head的大小。
- BSNGD:为原始BSH shape做reshape后的shape,S和D为单Batch的矩阵乘的M轴(或N轴)和K轴,一个SD为一个batch的计算数据,Layout格式如下图所示:
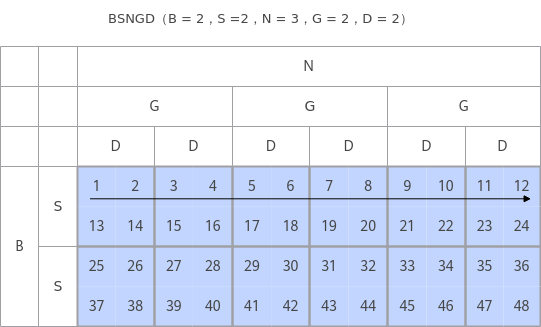
- SBNGD:为原始SBH shape做reshape后shape,S和D为的矩阵乘的M轴(或N轴)和K轴,一个SD为一个Batch的计算数据,Layout格式如下图所示:
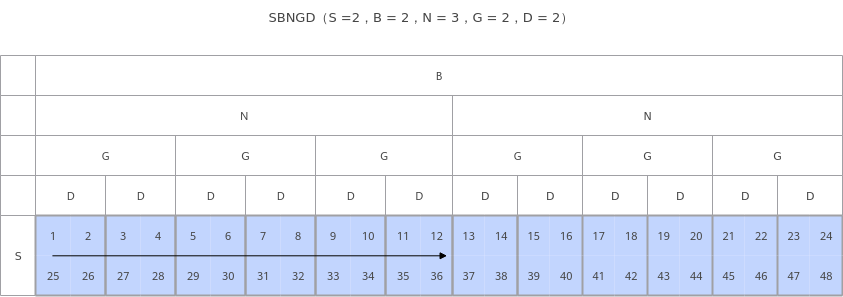
- BNGS1S2:一般为前两种Layout进行矩阵乘的输出,S1S2数据连续存放,一个S1S2为一个Batch的计算数据,Layout格式如下图所示:
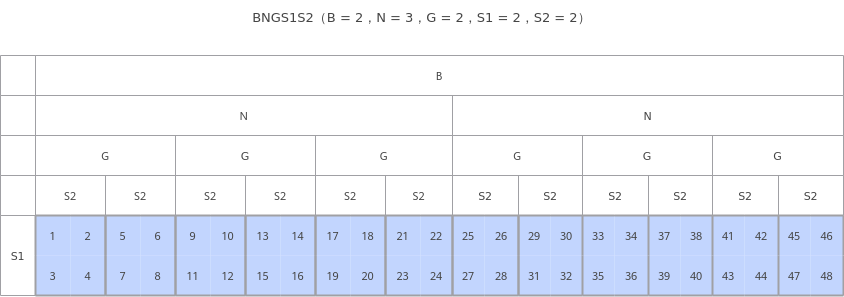
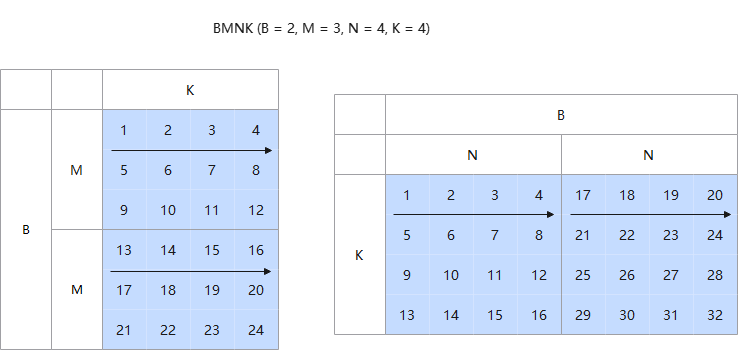
实例化Matmul时,需要通过MatmulType设置输入输出的Layout格式,当前支持4种Layout类型:BSNGD、SBNGD、BNGS1S2、NORMAL(BMNK的数据排布格式使用NORMAL表示)。
对于BSNGD、SBNGD、BNGS1S2 Layout格式,调用该接口之前需要在host Tiling实现中使用SetALayout、SetBLayout、SetCLayout、SetBatchNum设置A/B/C的Layout轴信息和最大BatchNum数;对于NORMAL Layout格式则需使用SetBatchInfoForNormal设置A/B/C的M/N/K轴信息和A/B矩阵的BatchNum数。
单个矩阵乘迭代顺序可通过tiling参数iterateOrder调整。
函数原型
- mix模式
- 输出至GM
1 2
template <bool sync = true, bool waitIterateBatch = false> __aicore__ inline void IterateBatch(const GlobalTensor<DstT>& gm, uint32_t batchA, uint32_t batchB, bool enSequentialWrite, const uint32_t matrixStrideA = 0, const uint32_t matrixStrideB = 0, const uint32_t matrixStrideC = 0, const bool enPartialSum = false, const uint8_t enAtomic = 0)
- 输出至VECIN
1 2
template <bool sync = true> __aicore__ inline void IterateBatch(const LocalTensor<DstT>& ubCmatrix, uint32_t batchA, uint32_t batchB, bool enSequentialWrite, const uint32_t matrixStrideA = 0, const uint32_t matrixStrideB = 0, const uint32_t matrixStrideC = 0, const bool enPartialSum = false, const uint8_t enAtomic = 0)
使用前需先调用SetBatchNum接口设置batchA和batchB的大小。
- 输出至GM
- 纯cube模式
- 输出至GM
1__aicore__ inline void IterateBatch(const GlobalTensor<DstT>& gm, bool enPartialSum, uint8_t enAtomic, bool enSequentialWrite, const uint32_t matrixStrideA = 0, const uint32_t matrixStrideB = 0, const uint32_t matrixStrideC = 0)
- 输出至VECIN
1__aicore__ inline void IterateBatch(const LocalTensor<DstT>& ubCmatrix, bool enPartialSum, uint8_t enAtomic, bool enSequentialWrite, const uint32_t matrixStrideA = 0, const uint32_t matrixStrideB = 0, const uint32_t matrixStrideC = 0)
- 输出至GM
参数说明
|
参数名 |
描述 |
|---|---|
|
sync |
获取C矩阵过程分为同步和异步两种模式:
通过该参数设置同步或者异步模式:同步模式设置为true;异步模式设置为false。默认为同步模式。异步场景需要配合WaitIterateBatch接口使用。 |
|
waitIterateBatch |
是否需要通过WaitIterateBatch接口等待IterateBatch执行结束,仅在异步场景下使用。默认为false。 true:需要通过WaitIterateBatch接口等待IterateBatch执行结束。 false:不需要通过WaitIterateBatch接口等待IterateBatch执行结束,开发者自行处理等待IterateBatch执行结束的过程。 |
|
参数名 |
输入/输出 |
描述 |
|---|---|---|
|
gm |
输入 |
C矩阵放置于Global Memory的地址。 Atlas A2训练系列产品/Atlas 800I A2推理产品,支持的数据类型为:half/float/bfloat16_t/int32_t Atlas推理系列产品AI Core,支持的数据类型为:half/float/bfloat16_t/int32_t |
|
ubCmatrix |
输入 |
C矩阵放置于Local Memory的地址。 Atlas A2训练系列产品/Atlas 800I A2推理产品,支持的数据类型为:half/float/bfloat16_t/int32_t Atlas推理系列产品AI Core,支持的数据类型为:half/float/bfloat16_t/int32_t |
|
batchA |
输入 |
左矩阵的batch数。 |
|
batchB |
输入 |
右矩阵的batch数。在batchA/batchB不相同的情况下,默认做broadcast操作。 多batch计算支持在G轴上做输入broadcast和输出reduce,左矩阵、右矩阵G轴维度必须是整数倍的关系。 |
|
enSequentialWrite |
输入 |
输出是否连续存放数据。
|
|
matrixStrideA |
输入 |
A矩阵源操作数相邻nd矩阵起始地址间的偏移,单位是元素。 |
|
matrixStrideB |
输入 |
B矩阵源操作数相邻nd矩阵起始地址间的偏移,单位是元素。 |
|
matrixStrideC |
输入 |
C矩阵目的操作数相邻nd矩阵起始地址间的偏移,单位是元素。 |
|
enPartialSum |
输入 |
是否将矩阵乘的结果累加于现有的CO1数据,默认值false。在L0C累加时,只支持A矩阵和B矩阵相乘的输出C矩阵规格为singleM==baseM &&singleN==baseN。 |
|
enAtomic |
输入 |
是否开启Atomic操作,默认值为0。 参数取值: 0:不开启Atomic操作 1:开启AtomicAdd累加操作 2:开启AtomicMax求最大值操作 3:开启AtomicMin求最小值操作 |
返回值
无
支持的型号
Atlas A2训练系列产品/Atlas 800I A2推理产品
Atlas推理系列产品AI Core
约束说明
- 对于BSNGD、SBNGD、BNGS1S2 Layout格式,输入A、B矩阵按分形对齐后的多Batch数据总和应小于L1 Buffer的大小;对于NORMAL Layout格式没有这种限制,但需通过MatmulConfig配置输入A、B矩阵多Batch数据大小与L1 Buffer的大小关系。
- 如果接口输出到Unified Buffer上,输出C矩阵大小BaseM*BaseN应小于分配的Unified Buffer内存大小。
- 对于BSNGD、SBNGD、BNGS1S2 Layout格式,输入输出只支持ND格式数据。对于NORMAL Layout格式, 输入支持ND/NZ格式数据。
- 该接口不支持量化模式,即不支持SetQuantScalar、SetQuantVector接口。
- BSNGD场景,不支持一次计算多行SD,需要算子程序中循环计算。
- 异步模式不支持IterateBatch搬运到UB上。
- BatchMatmul只支持Norm模板。
- Atlas推理系列产品AI Core,只支持NORMAL Layout格式。
- 在Atlas推理系列产品AI Core上,不支持A、B矩阵内存逻辑位置为TPosition::TSCM的输入。
- Atlas推理系列产品AI Core上,Bias不支持复用,Bias的shape大小必须为Batch * N。
调用示例
- 该示例完成aGM、bGM矩阵乘,结果保存到cGm上,其中aGM、bGM、cGM数据的layout格式均为NORMAL,左矩阵每次计算batchA个MK数据,右矩阵每次计算batchB个KN数据。
#include "kernel_operator.h" #include "lib/matmul_intf.h" extern "C" __global__ __aicore__ void kernel_matmul_rpc_batch(GM_ADDR aGM, GM_ADDR bGM, GM_ADDR cGM, GM_ADDR biasGM, GM_ADDR tilingGM, GM_ADDR workspaceGM, uint32_t isTransposeAIn, uint32_t isTransposeBIn, int32_t batchA, int32_t batchB) { // 定义matmul type typedef matmul::MatmulType <AscendC::TPosition::GM, CubeFormat::ND, half, false, LayoutMode::NORMAL> aType; typedef matmul::MatmulType <AscendC::TPosition::GM, CubeFormat::ND, half, true, LayoutMode::NORMAL> bType; typedef matmul::MatmulType <AscendC::TPosition::GM, CubeFormat::ND, float, false, LayoutMode::NORMAL> cType; typedef matmul::MatmulType <AscendC::TPosition::GM, CubeFormat::ND, float> biasType; // 初始化tiling数据 TCubeTiling tiling; auto tempTilingGM = (__gm__ uint32_t*)tilingGM; auto tempTiling = (uint32_t*)&tiling; for (int i = 0; i < sizeof(TCubeTiling) / sizeof(int32_t); ++i, ++tempTilingGM, ++tempTiling) { *tempTiling = *tempTilingGM; } // 初始化gm数据 AscendC::GlobalTensor<half> aGlobal; AscendC::GlobalTensor<half> bGlobal; AscendC::GlobalTensor<float> cGlobal; AscendC::GlobalTensor<float> biasGlobal; int32_t sizeA = tiling.ALayoutInfoB * tiling.singleCoreM * tiling.singleCoreK * sizeof(A_T); int32_t sizeB = tiling.BLayoutInfoB * tiling.singleCoreK * tiling.singleCoreN * sizeof(B_T); int32_t sizeC = tiling.CLayoutInfoB * tiling.singleCoreM * tiling.singleCoreN * sizeof(C_T); int32_t sizebias = tiling.CLayoutInfoB * tiling.singleCoreN * sizeof(C_T); aGlobal.SetGlobalBuffer(reinterpret_cast<__gm__ half*>(aGM), sizeA); bGlobal.SetGlobalBuffer(reinterpret_cast<__gm__ half*>(bGM), sizeB); cGlobal.SetGlobalBuffer(reinterpret_cast<__gm__ float*>(cGM), sizeC); biasGlobal.SetGlobalBuffer(reinterpret_cast<__gm__ float*>(biasGM), sizebias); tiling.shareMode = 0; tiling.shareL1Size = 512 * 1024; tiling.shareL0CSize = 128 * 1024; tiling.shareUbSize = 0; int offset_a=0, offset_b=0, offset_c=0, offset_bias=0; AscendC::GlobalTensor<A_T> gm_a; gm_a.SetGlobalBuffer(const_cast<__gm__ A_T*>(aGlobal[offset_a].GetPhyAddr()), tiling.singleCoreM * tiling.singleCoreK); AscendC::GlobalTensor<B_T> gm_b; gm_b.SetGlobalBuffer(const_cast<__gm__ B_T*>(bGlobal[offset_b].GetPhyAddr()), tiling.singleCoreK * tiling.singleCoreN); AscendC::GlobalTensor<C_T> gm_c; gm_c.SetGlobalBuffer(const_cast<__gm__ C_T*>(cGlobal[offset_c].GetPhyAddr()), tiling.singleCoreM * tiling.singleCoreN) ; AscendC::GlobalTensor<BiasT> gm_bias; gm_bias.SetGlobalBuffer(const_cast<__gm__ BiasT*>(biasGlobal[offset_bias].GetPhyAddr()), tiling.singleCoreN); // 创建Matmul实例 constexpr static MatmulConfig MM_CFG = GetNormalConfig(false, false, false, BatchMode::BATCH_LESS_THAN_L1); matmul::Matmul<aType, bType, cType, biasType, MM_CFG> mm1; TPipe pipe; REGIST_MATMUL_OBJ(&pipe, GetSysWorkSpacePtr(), mm1); mm1.Init(&tiling); mm1.SetTensorA(gm_a, isTransposeAIn); mm1.SetTensorB(gm_b, isTransposeBIn); mm1.SetWorkspace(workspaceGM, 0); if(tiling.isBias) { mm1.SetBias(gm_bias); } // 多batch Matmul计算 mm1.IterateBatch(gm_c, batchA, batchB, false); } - 该示例完成aGM、bGM矩阵乘,结果保存到cGm上,其中aGM数据的layout格式为BSNGD,bGM数据的layout格式为BSNGD,cGM的layout格式为BNGS1S2,左矩阵每次计算batchA个SD数据,右矩阵每次计算batchB个SD数据。
#include "kernel_operator.h" #include "lib/matmul_intf.h" extern "C" __global__ __aicore__ void kernel_matmul_rpc_batch(GM_ADDR aGM, GM_ADDR bGM, GM_ADDR cGM, GM_ADDR biasGM, GM_ADDR tilingGM, GM_ADDR workspaceGM, uint32_t isTransposeAIn, uint32_t isTransposeBIn, int32_t batchA, int32_t batchB) { // 定义matmul type typedef matmul::MatmulType <AscendC::TPosition::GM, CubeFormat::ND, half, false, LayoutMode::BSNGD> aType; typedef matmul::MatmulType <AscendC::TPosition::GM, CubeFormat::ND, half, true, LayoutMode::BSNGD> bType; typedef matmul::MatmulType <AscendC::TPosition::GM, CubeFormat::ND, float, false, LayoutMode::BNGS1S2> cType; typedef matmul::MatmulType <AscendC::TPosition::GM, CubeFormat::ND, float> biasType; // 初始化tiling数据 TCubeTiling tiling; auto tempTilingGM = (__gm__ uint32_t*)tilingGM; auto tempTiling = (uint32_t*)&tiling; for (int i = 0; i < sizeof(TCubeTiling) / sizeof(int32_t); ++i, ++tempTilingGM, ++tempTiling) { *tempTiling = *tempTilingGM; } // 初始化gm数据 AscendC::GlobalTensor<half> aGlobal; AscendC::GlobalTensor<half> bGlobal; AscendC::GlobalTensor<float> cGlobal; AscendC::GlobalTensor<float> biasGlobal; int32_t sizeA = tiling.ALayoutInfoB * tiling.ALayoutInfoS * tiling.ALayoutInfoN * tiling.ALayoutInfoG * tiling.ALayoutInfoD * sizeof(half); int32_t sizeB = tiling.BLayoutInfoB * tiling.BLayoutInfoS * tiling.BLayoutInfoN * tiling.BLayoutInfoG * tiling.BLayoutInfoD * sizeof(half); int32_t sizeC = tiling.CLayoutInfoB * tiling.CLayoutInfoS1 * tiling.CLayoutInfoN * tiling.CLayoutInfoG * tiling.CLayoutInfoS2 * sizeof(float); int32_t sizebias = tiling.CLayoutInfoB * tiling.CLayoutInfoN * tiling.CLayoutInfoG * tiling.CLayoutInfoS2 * sizeof(float); aGlobal.SetGlobalBuffer(reinterpret_cast<__gm__ half*>(aGM), sizeA); bGlobal.SetGlobalBuffer(reinterpret_cast<__gm__ half*>(bGM), sizeB); cGlobal.SetGlobalBuffer(reinterpret_cast<__gm__ float*>(cGM), sizeC); biasGlobal.SetGlobalBuffer(reinterpret_cast<__gm__ float*>(biasGM), sizebias); tiling.shareMode = 0; tiling.shareL1Size = 512 * 1024; tiling.shareL0CSize = 128 * 1024; tiling.shareUbSize = 0; int offset_a=0, offset_b=0, offset_c=0, offset_bias=0; AscendC::GlobalTensor<A_T> gm_a; gm_a.SetGlobalBuffer(const_cast<__gm__ half*>(aGlobal[offset_a].GetPhyAddr()), tiling.ALayoutInfoS * tiling.ALayoutInfoN * tiling.ALayoutInfoG * tiling.ALayoutInfoD); AscendC::GlobalTensor<B_T> gm_b; gm_b.SetGlobalBuffer(const_cast<__gm__ half*>(bGlobal[offset_b].GetPhyAddr()), tiling.BLayoutInfoS * tiling.BLayoutInfoN * tiling.BLayoutInfoG * tiling.BLayoutInfoD); AscendC::GlobalTensor<C_T> gm_c; gm_c.SetGlobalBuffer(const_cast<__gm__ float*>(cGlobal[offset_c].GetPhyAddr()), tiling.CLayoutInfoS1 * tiling.CLayoutInfoN * tiling.CLayoutInfoG * tiling.CLayoutInfoS2) ; AscendC::GlobalTensor<BiasT> gm_bias; gm_bias.SetGlobalBuffer(const_cast<__gm__ float*>(biasGlobal[offset_bias].GetPhyAddr()), tiling.CLayoutInfoN * tiling.CLayoutInfoG * tiling.CLayoutInfoS2); // 创建Matmul实例 matmul::Matmul<aType, bType, cType, biasType> mm1; AscendC::TPipe pipe; REGIST_MATMUL_OBJ(&pipe, GetSysWorkSpacePtr(), mm1); mm1.Init(&tiling); mm1.SetWorkspace(workspaceGM, 0); int batchC = batchA > batchB ? batchA : batchB; int g_lay = tiling.ALayoutInfoG > tiling.BLayoutInfoG ? tiling.ALayoutInfoG : tiling.BLayoutInfoG; // 计算需要多Batch计算循环次数 int for_exent = tiling.ALayoutInfoB * tiling.ALayoutInfoN * g_lay / tiling.BatchNum; for(int i=0; i<for_exent; ++i) { // 计算每次多batch计算A/B矩阵的起始地址 int batchOffsetA = i * tiling.ALayoutInfoD * batchA; int batchOffsetB = i * tiling.BLayoutInfoD * batchB; mm1.SetTensorA(gm_a[batchOffsetA], isTransposeAIn); mm1.SetTensorB(gm_b[batchOffsetB], isTransposeBIn); int idx_c = i * batchC; if (tiling.CLayoutInfoG == 1 && (tiling.BLayoutInfoG != 1 || tiling.ALayoutInfoG != 1)) { idx_c = idx_c / (tiling.BLayoutInfoG > tiling.ALayoutInfoG ? tiling.BLayoutInfoG : tiling.ALayoutInfoG); } if(tiling.isBias) { int batchOffsetBias = idx_c * tiling.CLayoutInfoS2; mm1.SetBias(gm_bias[batchOffsetBias]); } int batchOffsetC = idx_c * tiling.CLayoutInfoS2; if (C_TYPE::layout == LayoutMode::BNGS1S2) { batchOffsetC = idx_c * tiling.CLayoutInfoS2 * tiling.CLayoutInfoS1; } // 多batch Matmul计算 mm1.IterateBatch(gm_c[batchOffsetC], batchA, batchB, false); } }