



问题现象描述
下发vcjob任务后,训练任务一直未运行。
- 执行kubectl get pod --all-namespaces命令,查看该训练任务所属的Pod处于pending状态,如下图所示。
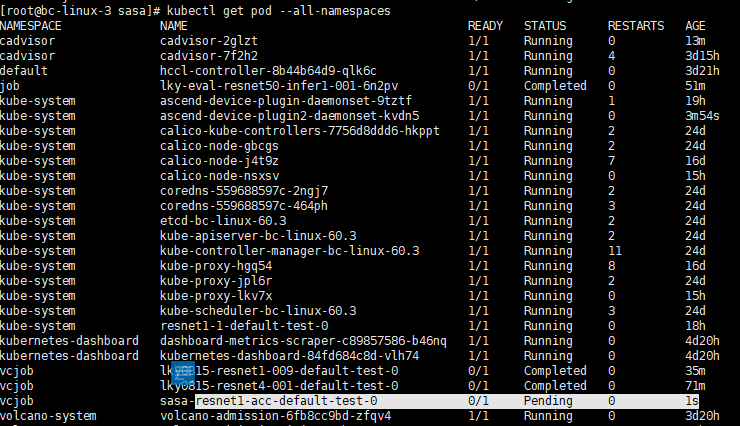
- 执行kubectl describe pod sasa-resnet1-acc-default-test-0 -n vcjob命令,查看Pod的详情。在event字段中报:all nodes are unavailable: 1 node annotations(7) not same node idle(8)。

原因分析
该节点的未使用NPU数目与configmap中展示的未使用NPU数目不一致。Volcano认为系统处于不稳定阶段,不能进行本次NPU资源的分配。
执行kubectl describe nodes命令,查看节点的Allocated resources的huawei.com/Ascend910:字段。
Allocated resources: (Total limits may be over 100 percent, i.e., overcommitted.) Resource Requests Limits -------- -------- ------ cpu 2500m (1%) 1500m (1%) memory 4012Mi (0%) 4212Mi (0%) ephemeral-storage 0 (0%) 0 (0%) huawei.com/Ascend910 1 1 huawei.com/davinci-mini 0 0
执行kubectl describe cm mindx-dl-deviceinfo-<NODE_NAME> -n kube-system命令,查看节点的huawei.com/Ascend910:字段
Name: mindx-dl-deviceinfo-ubuntu
Namespace: kube-system
Labels: <none>
Annotations: <none>
Data
====
DeviceInfoCfg:
----
{"DeviceInfo":{"DeviceList":{"huawei.com/Ascend910":"Ascend910-1,Ascend910-2,Ascend910-3,Ascend910-4,Ascend910-5,Ascend910-6,Ascend910-7","huawei.com/Ascend910-NetworkUnhealthy":"","huawei.com/Ascend910-Unhealthy":""},"UpdateTime":1661419757}
,"CheckCode":"e8a03644d1f5033902c210accc303d0e37362a0d1575a71dec1fdf02378280e3"}造成该问题的原因除了任务量特别多时(K8s运行缓慢),主要原因为Ascend Device Plugin启动方式存在问题。
解决措施
重新安装Ascend Device Plugin,请参见《MindCluser 集群调度安装指南》的“安装部署 > 手动安装 > Ascend Device Plugin”章节。