Challenges
MoE model inference challenges
High MoE All2All Latency
Communication latency can reach up to 70% of total delay, prolonging text output and slowing dialog responses.
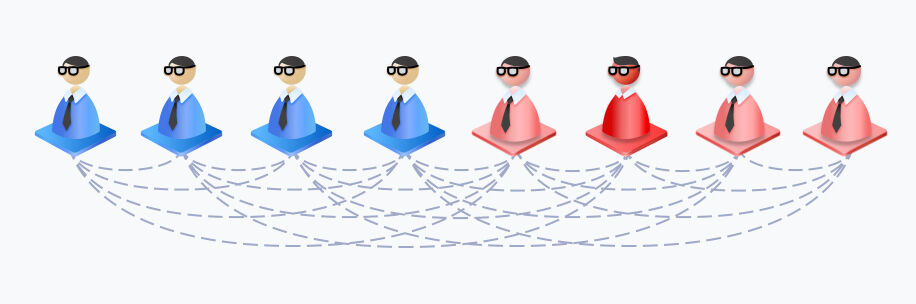
Inefficiency from Unbalanced MoE Load
Random routing causes uneven workloads, making some experts overly busy while others remain idle. This imbalance slows down inference services and lowers computing efficiency.

MoE Memory Constraint and Performance Bottleneck
For example, the DeepSeek-R1 671B model requires 700 GB for its weights, but the fragmented KV cache leaves little free memory, limiting inference speed.
Solutions
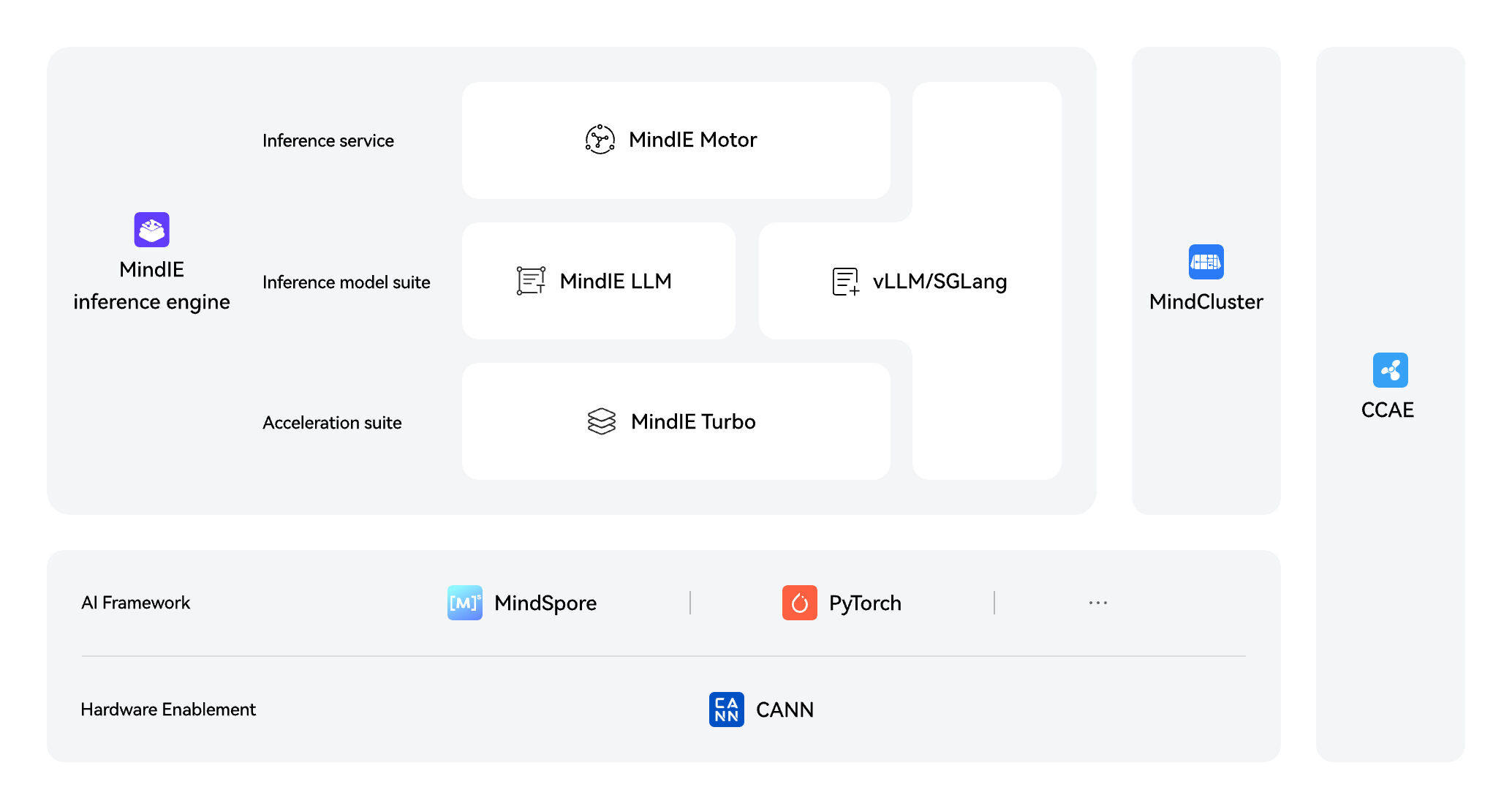
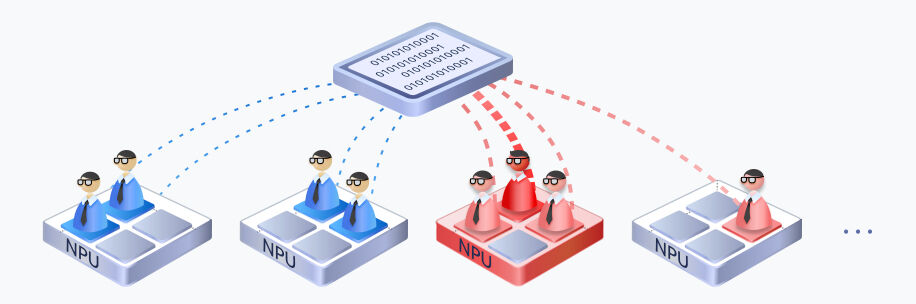
MoE EP Solution
MoE EP is the best choice for MoE inference. It boosts single-card performance by 2 to 4 times, cuts system delay by over 50%, and delivers better results using the same number of cards. This enables one input to produce multiple outputs efficiently.
64-card MoE EP
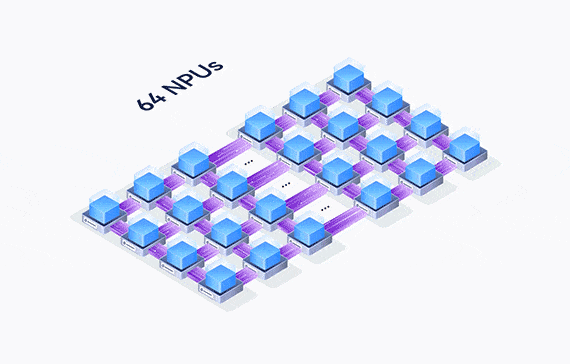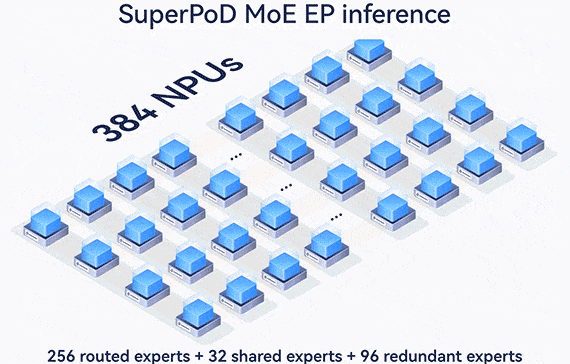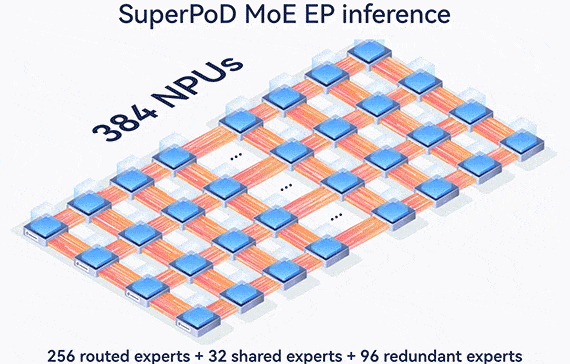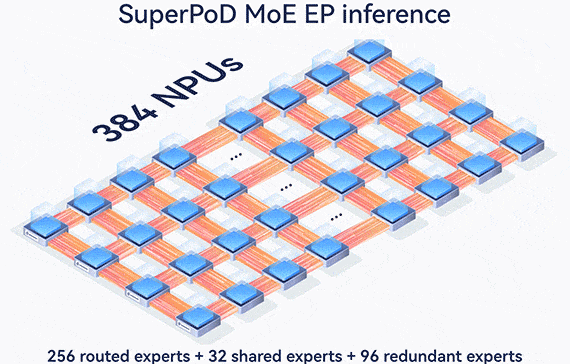
384-card MoE EP
Solution Highlights
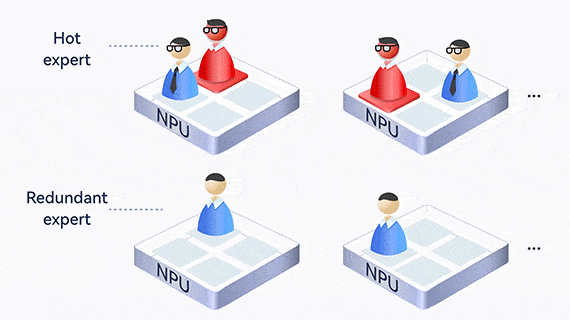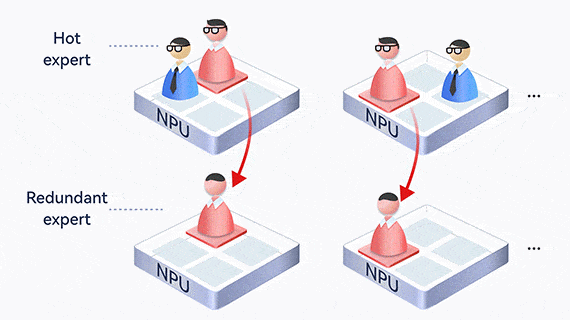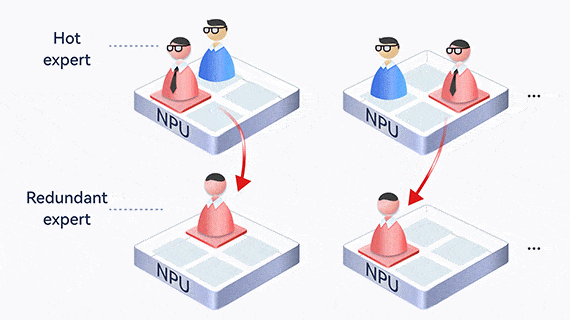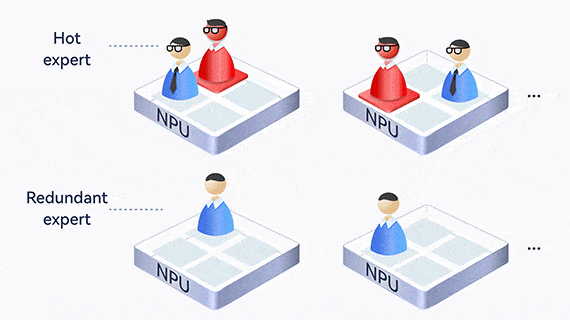
Dynamic expert load balancing
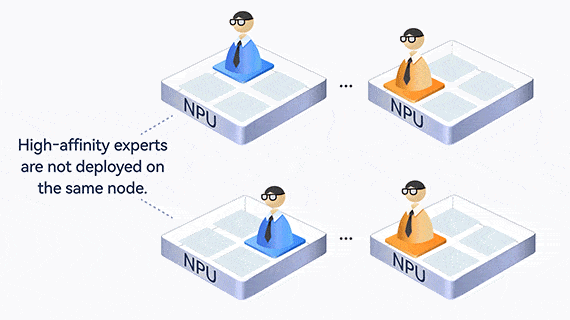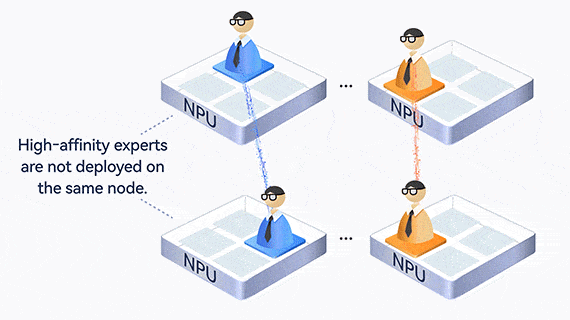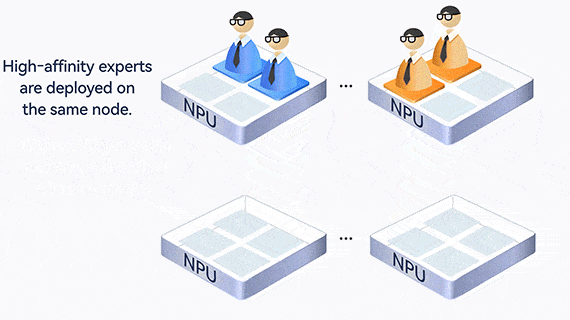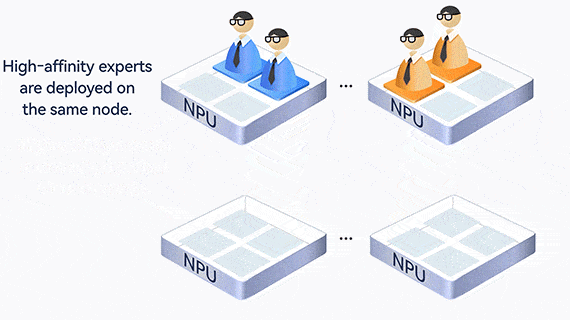
MoE creates an uneven workload among experts, where one expert may become overloaded and slow down the entire process. Atlas uses EPLB to dynamically balance expert loads, collect statistics and analyze hot experts online, and adjust redundant experts to share loads in real time.
In addition, experts who communicate frequently are deployed on the same card or server, reducing communication across cards and servers.
These optimization techniques effectively distribute compute tasks among experts, lowering the peak-to-average load ratio from 8 to 1.4. They also reduce communication data volume by 30%, enhance hardware utilization, decrease cluster inference delays, and boost overall system throughput.