



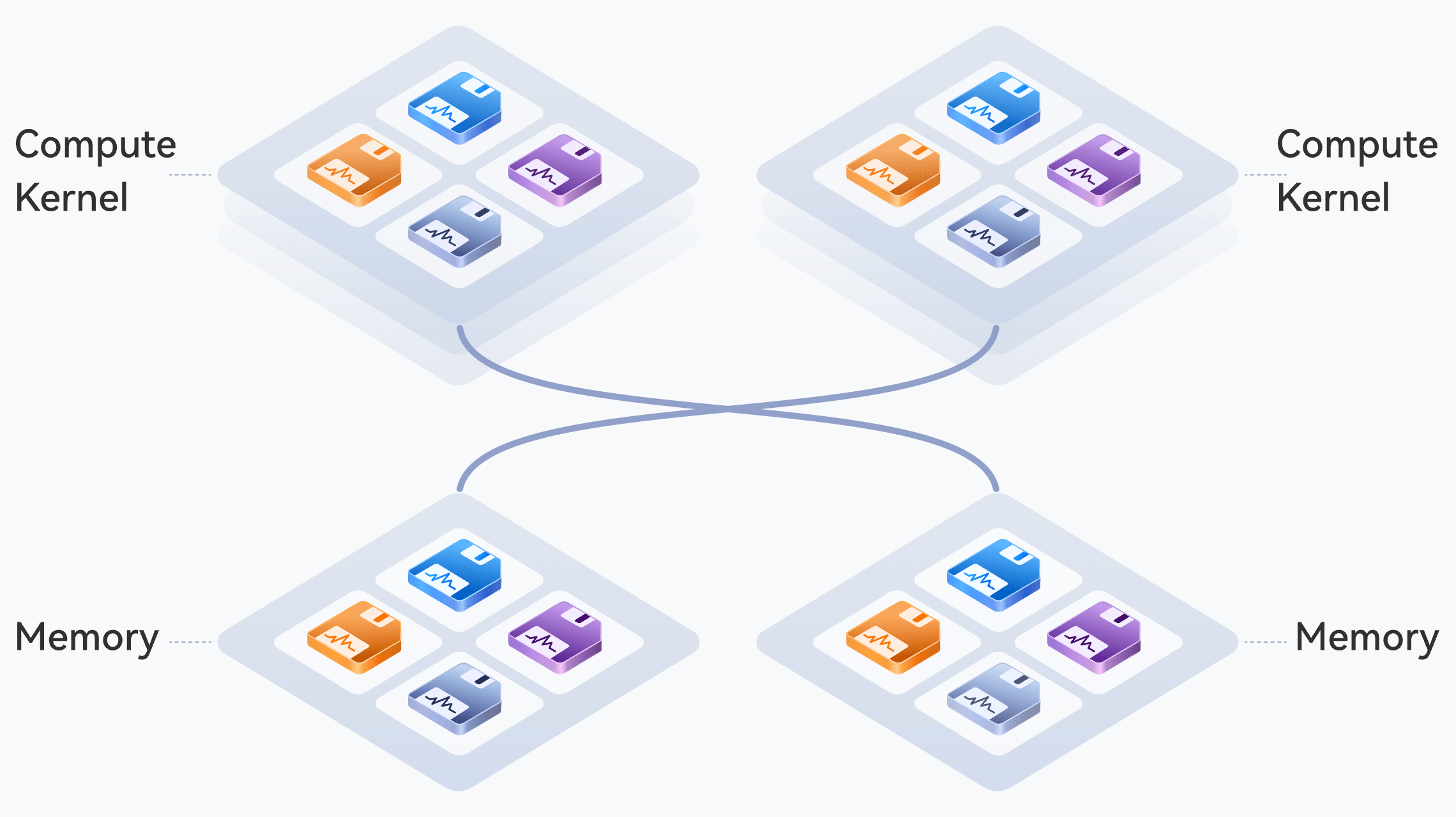
Communication Acceleration
Network-wide Latency:
100+%
Dual-pipeline parallelism for micro-batch processing and weight prefetching, with multi-computing software-hardware collaboration communication
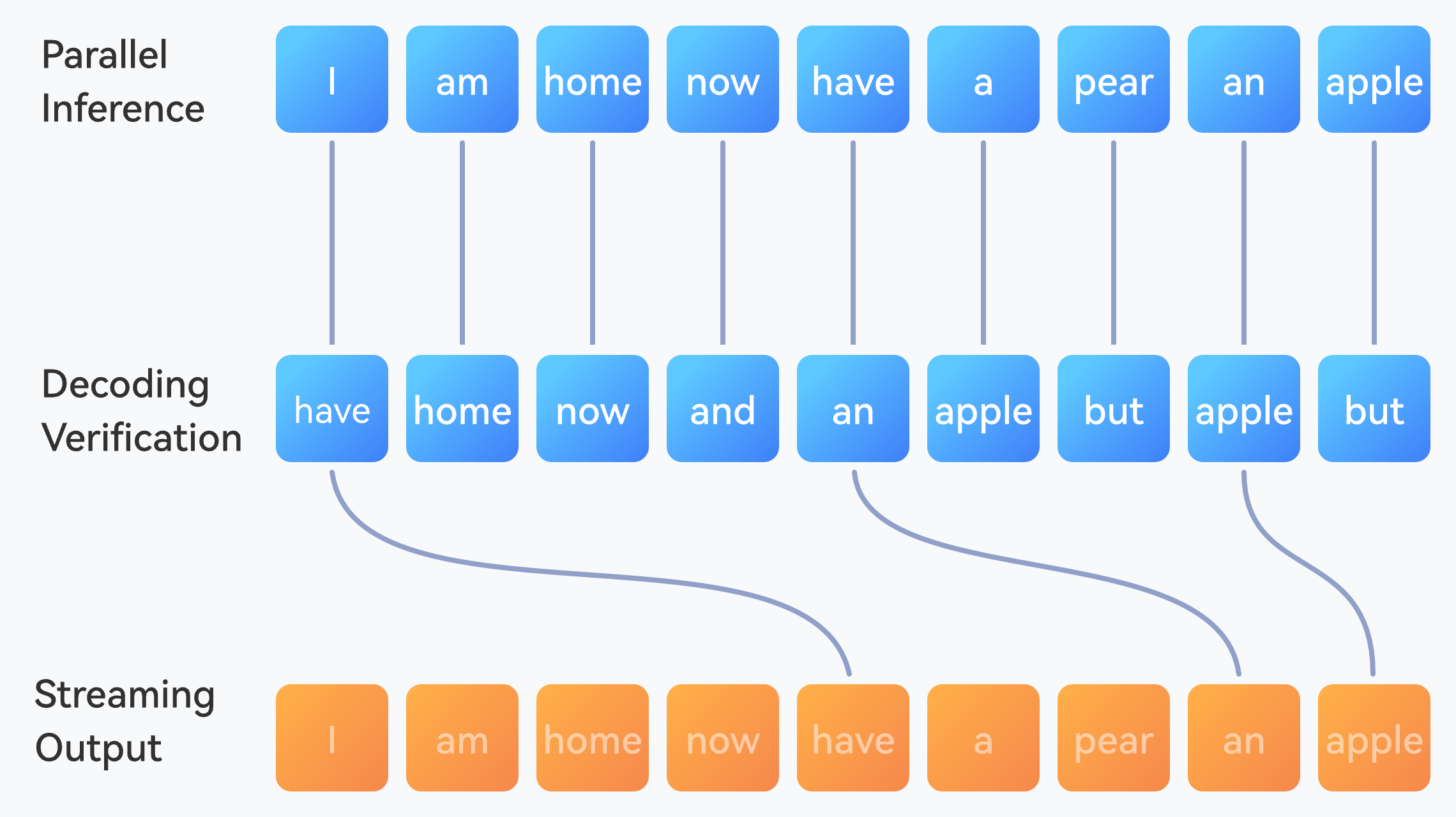
Decoding Optimization
Network-wide Latency:
30~60%
MTP, DraftDecoding
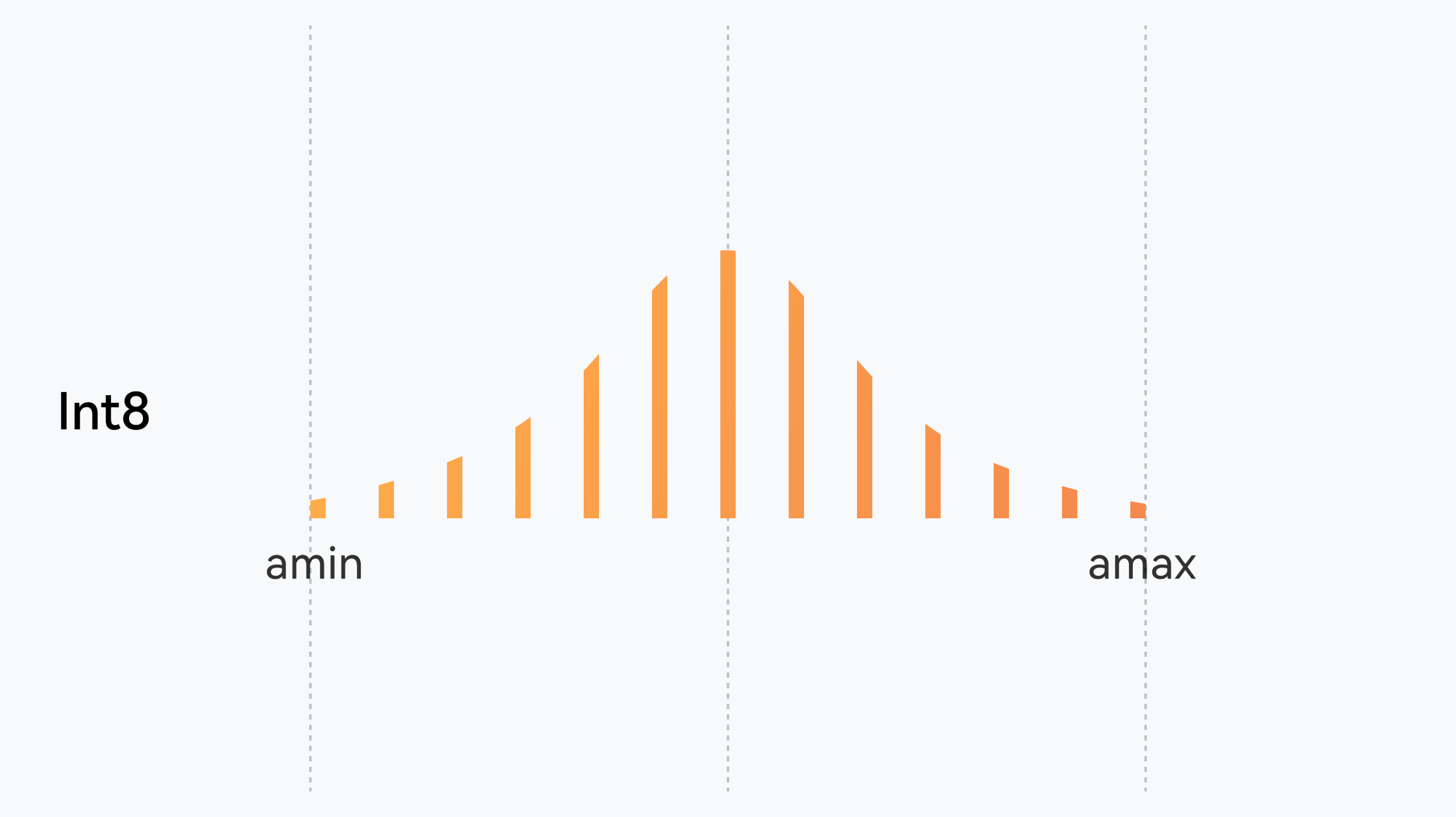
Quantization and Compression
Throughput:
30%
INT8 hybrid quantization, adaptive accuracy retention
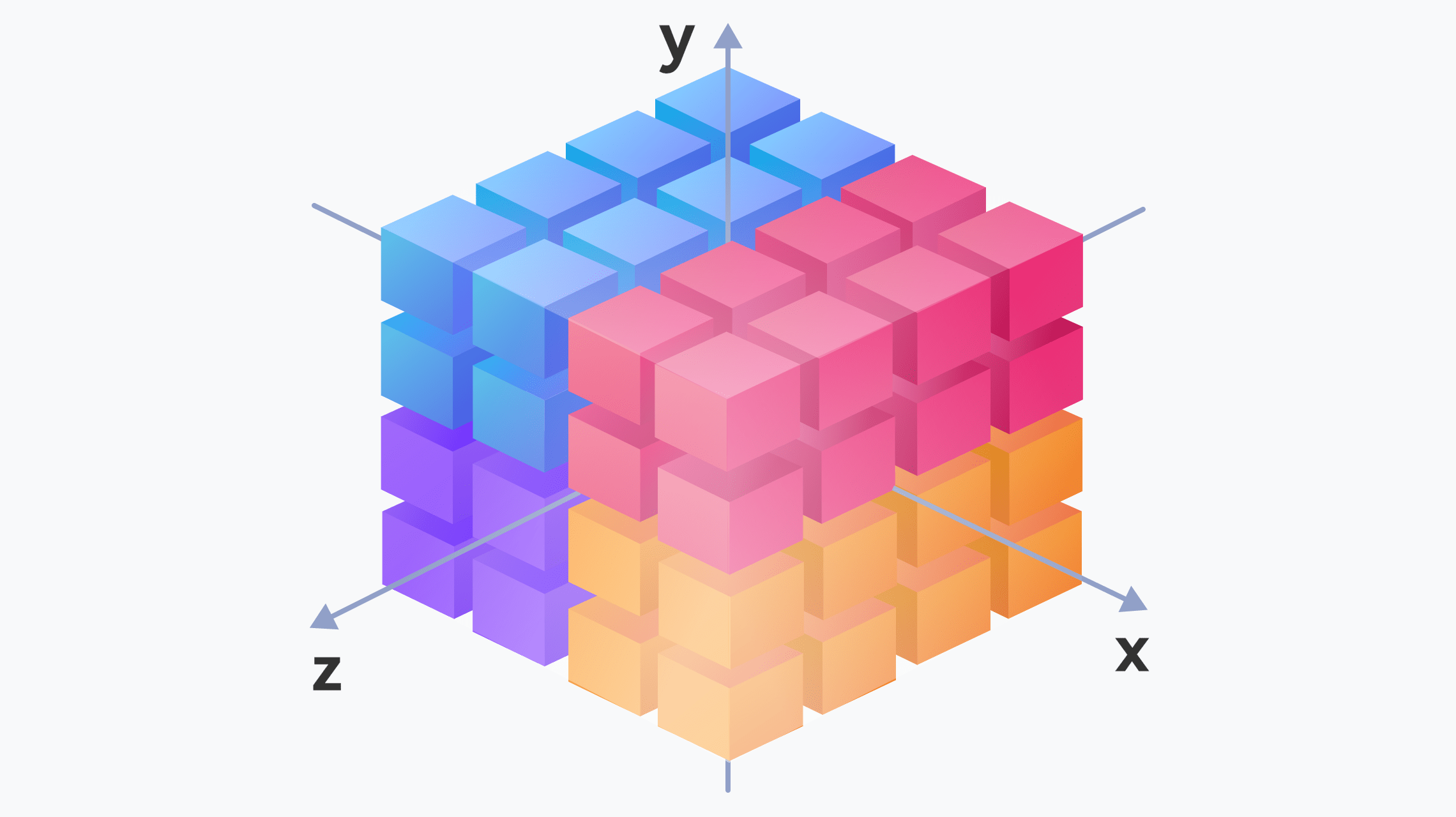
Optimal Parallelism
Throughput:
3x
SPDTE hybrid parallelism, optimal parallel search
Scheduling Optimization
Throughput:
50%
Prefill-decode disaggregation, multi-node inference scheduling