Pipeline并行内存优化
基本原理
流水线并行会引起内存消耗头重脚轻的问题,导致卡间内存分布不均,训练模型尺寸受限于PP-Stage 0的显存,为了增大模型规模则需要采取重计算,导致单步训练时间大幅增长。
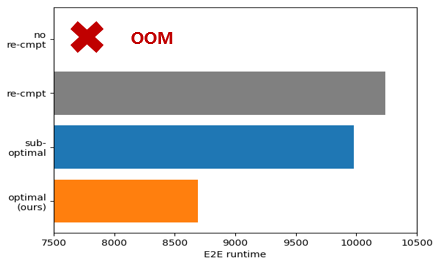
本算法通过合理利用剩余卡上的显存,构建最优内存排布,解决PP引入的内存不均衡问题,达到内存效率提升的效果,从而规避重计算,以此大幅减少单步运行时间,提升模型训练性能。
图1 pipeline并行导致的显存不均衡
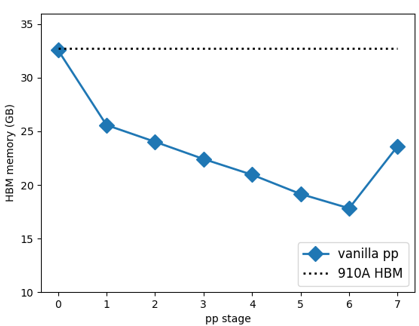
图2 通过优化显存使用规避重计算
使用场景
使用PP并行场景,当前在Atlas A2 训练系列产品上验证:96卡上BLOOM-176B上峰值内存可降低11.9%,性能无损,可使能关闭重计算带来40%的性能提升。
操作步骤
使用AscendSpeed,在PP并行的基础上添加 --use-manual_layer_allocation和 --manual_layers example-config标志, example-config当前需要手动配置不同stage的层数,PP自动并行切分功能开发中。
父主题: 初级调优