背景介绍
使用PyTorch网络应用在昇腾平台执行推理过程中,发现整体执行时间较长。为了找出原因,使用性能分析工具对该网络应用执行推理耗时分析,分析结果显示运行的接口aclmdlExecute执行耗时数值较高,进一步分析发现Conv算子执行时间最长。
打开PyTorch网络转换成的om模型查询Conv算子,发现该算子由多个计算单元组成,会造成极大的推理开销。由于Conv算子所在函数为Mish激活函数,而当前昇腾平台支持的激活函数只有:Relu、Leakyrelu、Prelu、Elu、Srelu,Mish函数暂时不支持,因此造成模型转换后的Mish函数被分解成了多个计算单元。
通过将om模型中的Mish函数替换昇腾平台的激活函数,尝试降低推理耗时,以Leakyrelu替换Mish函数为例,重新执行Profiling性能分析,结果发现推理耗时明显降低。

- 本文仅介绍Profiling性能分析工具的操作及分析过程,对于om模型的算子分析以及函数替换等操作此处不做阐述。
- 有关PyTorch模型转换为om模型的详细介绍请参见《PyTorch 网络模型迁移和训练》中的“模型保存与转换”章节。
Profiling性能分析操作
- 启动MindStudio,单击选择并打开已编译完成的工程。
有关应用工程的创建和编译操作请参见应用开发。
- 单击菜单栏,弹出Profiling配置窗口 。
- 进入Profiling配置窗口,如图1。配置Profiling的工程名称“Project Name”和选择Profiling工程的结果路径“Project Location”。单击“Next”进入下一步。
- 进入“Executable Properties”配置界面,选择Local Run模式。指定执行Profiling目标工程的可执行文件目录。如图2所示。
- 进入“Profiling Options”配置界面,选择Task-based场景。如图3所示。
- 完成上述配置后单击窗口右下角的“Start”按钮,启动Profiling。
工程执行完成后,MindStudio自动展示Profiling结果视图。如图4所示。




问题分析
- 根据Profiling Timeline视图的字段解释,展示模型、算子的耗时数据体现在AscendCL API字段。
通过设置Timeline颜色配置调色板,设置显色比例为20%<=黄色<50%<=红色,如图5所示。
得到新的Timeline比例并放大视图,如图6所示。此时可以直观的看到耗时最长的时间线有两段,分别为aclmdlLoadFromFileWithMem和aclmdlExcute接口。
- 接着在AscendCL API字段上右键单击“Show in Event View”并将Duration列按从大到小排序,如图7所示。
- 可以看到耗时最高的两个AscendCL接口为aclmdlLoadFromFileWithMem和aclmdlExcute。
到这里基本可以断定执行应用推理过程中耗时最高的两个接口就是aclmdlLoadFromFileWithMem和aclmdlExcute。
参见《应用软件开发指南(C&C++)》中的“AscendCL API参考”章节查找aclmdlLoadFromFileWithMem接口的作用为“从文件加载离线模型数据”,可以分析该接口耗时取决于加载离线模型的时间,加载时间我们暂时无法进行调优。
- 继续查找aclmdlExecute接口的作用为“执行应用推理,直到返回推理结果,同步接口”。
可以发现该接口是执行接口,也就是说应用在执行推理的过程中确实存在耗时长的问题,而模型中所有算子执行的时间总和就是执行耗时。
那么查看Profiling结果AI Core Metrics视图中的算子执行耗时并按Task Duration算子执行任务的时间从高到低排列,如图9所示。
可以看到第一个Conv算子的执行时间为3170.625us远高于同进程下其他算子的执行时间,可以判断该函数拖慢了整体的执行效率。
到此Profiling性能分析工具的任务已经完成。
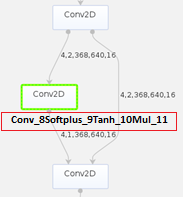
- 接下来可以通过模型可视化工具打开PyTorch网络转换成的om模型查询Conv算子,发现该算子是多个计算单元组成,如图10所示,这样会造成极大的推理开销。
- 通过查询代码发现计算单元中的Softplus、Tanh和Mul是属于Mish激活函数的计算公式,如图11所示。
当前昇腾平台支持的激活函数只有:Relu、Leakyrelu、Prelu、Elu和Srelu,Mish函数不在支持范围内,因此造成模型转换后的Mish函数被分解成了多个计算单元。
解决该问题最简单的办法就是找到效率更高的替代函数。






问题解决
尝试以昇腾官方提供的Leaky Relu激活函数作为替换函数。函数替换操作请用户自行处理,此处不作阐述。

结论
通过Profiling性能分析工具前后两次对网络应用推理的运行时间进行分析,并对比两次执行时间可以得出结论,替换Leaky Relu激活函数后,降低了Conv算子在应用推理的运行时间,提升了推理效率。