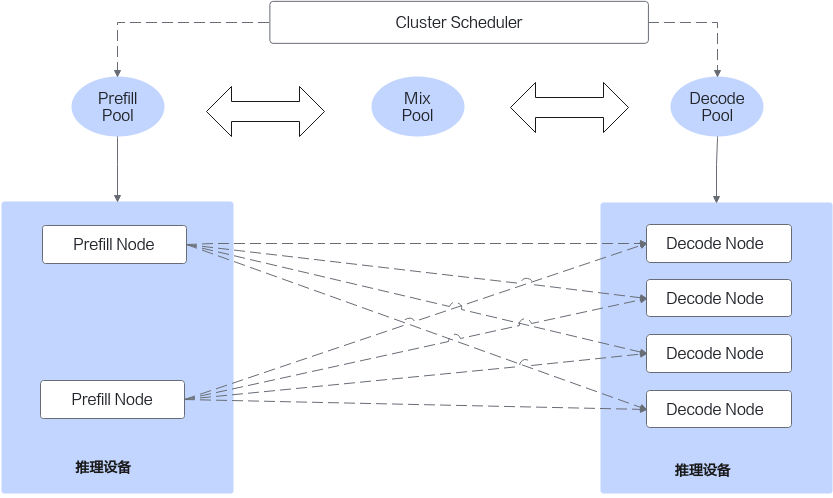
通过LLM-DataDist构建大模型推理分离式框架。
在大模型推理中,Prefill阶段将用户请求prompt传入大模型进行计算,中间结果写入KV Cache并推出第1个token。在Decode阶段中,将请求的前1个token传入大模型,从显存读取之前产生的KV Cache再进行计算。基于KV Cache的大模型推理过程,详见大模型推理流程简介。
在PD分离式框架中,为了提升性能和资源利用效率,将Prefill和Decode分别部署在不同规格和架构的集群中。PD分离式框架可提升大模型推理系统吞吐,详见为什么要做PD分离。
PD分离式框架中,Prefill阶段生成的KV Cache需要传输到Decode,然后Decode阶段进行增量迭代推理。LLM-DataDist作为大模型分布式集群和数据管理组件,通过简易的API开放给用户,构建大模型推理PD分离式框架如下图所示,LLM-DataDist提供了Prefill Node和Decode Node之间的KV Cache传输及链路管理。