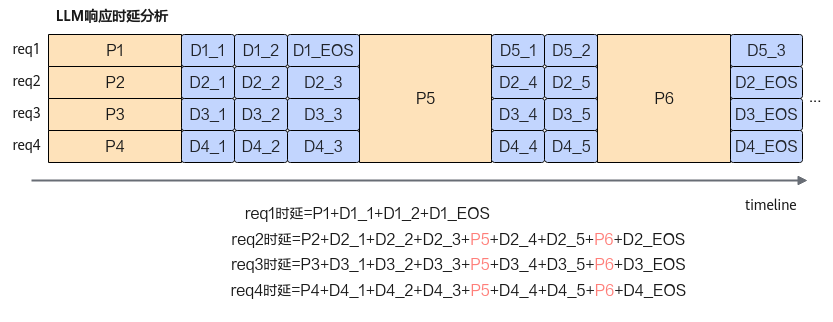
从实现上来看,整个LLM推理过程由Prefill和多轮迭代的Decode组成,想要在Decode阶段实现Continuing Batching的前提是,每个被调度的request需要空闲算力完成Prefill计算。按现有的部署模式,当Prefill和Decode部署在一起时,当有新的Prefill请求时,会被优先处理,从而导致Decode的执行流程被影响,增量Token时延(TBT)无法得到有效保障。例如下图,当request5或request6到来时,系统可能会优先执行request5或request6的Prefill,此时request2/3/4的响应时延会受到一定影响,从而导致TBT不稳定。
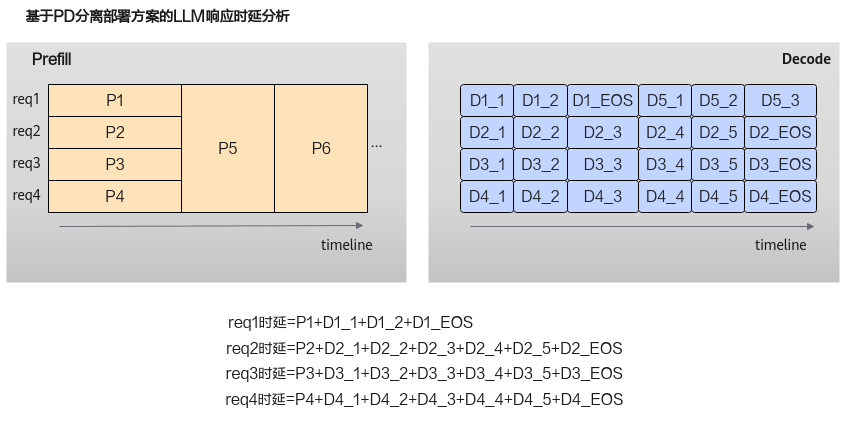
在实际的深度学习模型部署中,由于Prefill和Decode两阶段的计算/通信特征的差异特点,为了提升性能和资源利用效率,通过PD分离部署方案将Prefill和Decode分别部署在不同规格和架构的集群中,并且配合服务层的任务调度,在满足TTFT和TBT指标范围内,结合Continuous batching机制尽可能提高Decode阶段的batch并发数,在提供更好用户体验的前提下,提升算力利用率。
基于该方案,结合下图可以看到Prefill和Decode的执行互不影响,系统能够提供给用户一个稳定的TBT。