ChatGPT的推出意味着交互式人工智能逐渐成为商业化成熟产品,同时也进一步推动了底层技术大型语言模型LLM的研究和进步。现有主要使用的LLM包括GPT系列、LLAMA系列、GLM系列。其模型基础架构都采用Transformer架构,并以Decode-Only为主。该类Transformer-Based-Decode-Only的LLM在推理预测时,采用自回归生成(auto-aggressive generative)模式。即每个Token生成需要经过LLM模型的前向推理过程,即完成N次Transformer Layer层计算,意味着包含M个Token的语句完整生成需要经过M次完整LLM前向推理过程。
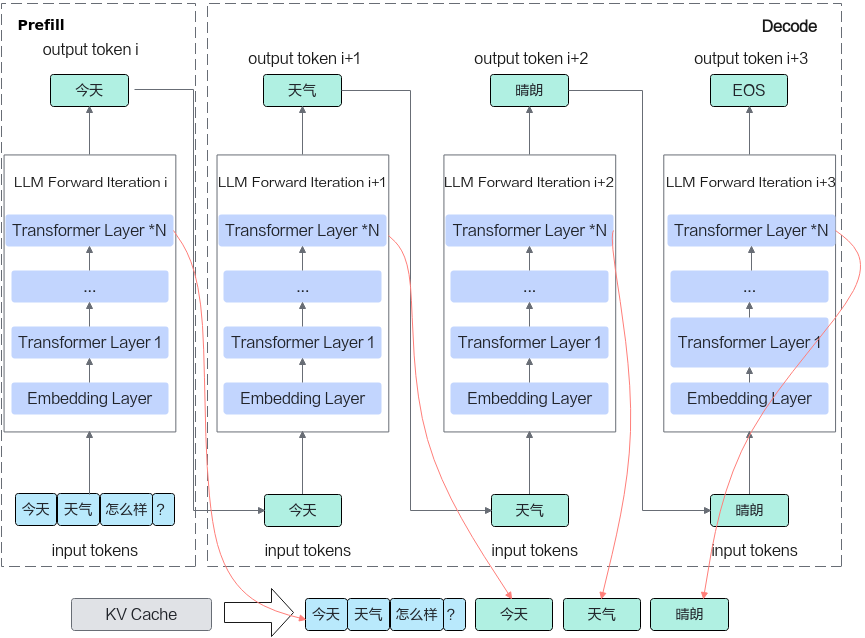
在Transformer推理过程中利用KV Cache技术可降低Decoding阶段的计算量,目前已成为LLM推理系统的必选技术。采用KV Cache的LLM推理过程通常分为预填充(Prefill)和解码(Decode)两个阶段。
- Prefill阶段:将用户请求的prompt传入大模型,进行计算,中间结果写入KV Cache并推理出第1个token。随着Prompt Sequence Length长度线性增长,对首Token时延(TTFT)指标有要求的业务通常采用单batch方式执行LLM推理,该阶段属于计算密集型操作。
- Decode阶段:将请求的前1个Token传入大模型,从显存读取前文产生的KV Cache再进行计算。采用KV Cache技术后,单Token计算量低,而主要瓶颈在于搬运参数量,故通常需要采用多batch方式提升利用率,该阶段属于访存密集型操作。