



【昇腾热点算子大解密】CANN极致优化GroupedMatmul量化方案,MoE推理Decode性能提升超30%
发表于 2025/07/17
LLM部署面临的高显存、高算力和推理效率挑战
在当前的大语言模型推理领域,以MoE推理模型为代表的超大参数量模型,其显存占用和带宽瓶颈已成为实际部署过程中的核心挑战。每提升一个数量级的模型参数或上下文长度,显存消耗都会急剧增长,这直接限制了单卡可支持的最大模型规模、上下文长度和并发能力。为应对这一挑战,各类量化压缩方案应运而生。
GroupedMatmul W4A8量化与MSD方案
分组矩阵乘法(GroupedMatmul)是一种将多个独立的小规模矩阵乘法(GEMM)任务分组并行执行的优化技术,通过合并计算拓扑相似的算子为单一内核调用,有效降低核启动开销并减少内存访问碎片化。
MoE模型在Decode阶段每个专家处理的激活数量偏少,导致传统的GEMM操作因单个专家计算规模小而难以充分发挥硬件算力。GroupedMatmul天然适配MoE模型的稀疏专家计算,通过将分散的专家任务合并为分组批量进行计算,提升任务规模以实现接近峰值算力的效率;同时,连续存储专家权重可以进一步优化缓存命中率,显著提升计算性能。
W4A8量化方案是当前主流的大模型低比特量化方案之一,通常结合per-channel、per-group和per-token等多种量化scale,兼顾精度与效率。通过将权重量化为INT4格式、激活量化为INT8格式,可以极大压缩模型参数的存储需求,W4A8方案的权重占用仅为传统FP16方案的四分之一。其显存优化能力,为大模型在有限硬件资源下的高效部署提供了坚实基础。
下图展示了GroupedMatmul的非对称/对称量化方案。在推理时,INT4权重通过scale和zero point解码,激活则直接以INT8参与整数GEMM计算;所有量化/反量化操作均在整数域内完成,最后一步统一反量化为浮点。
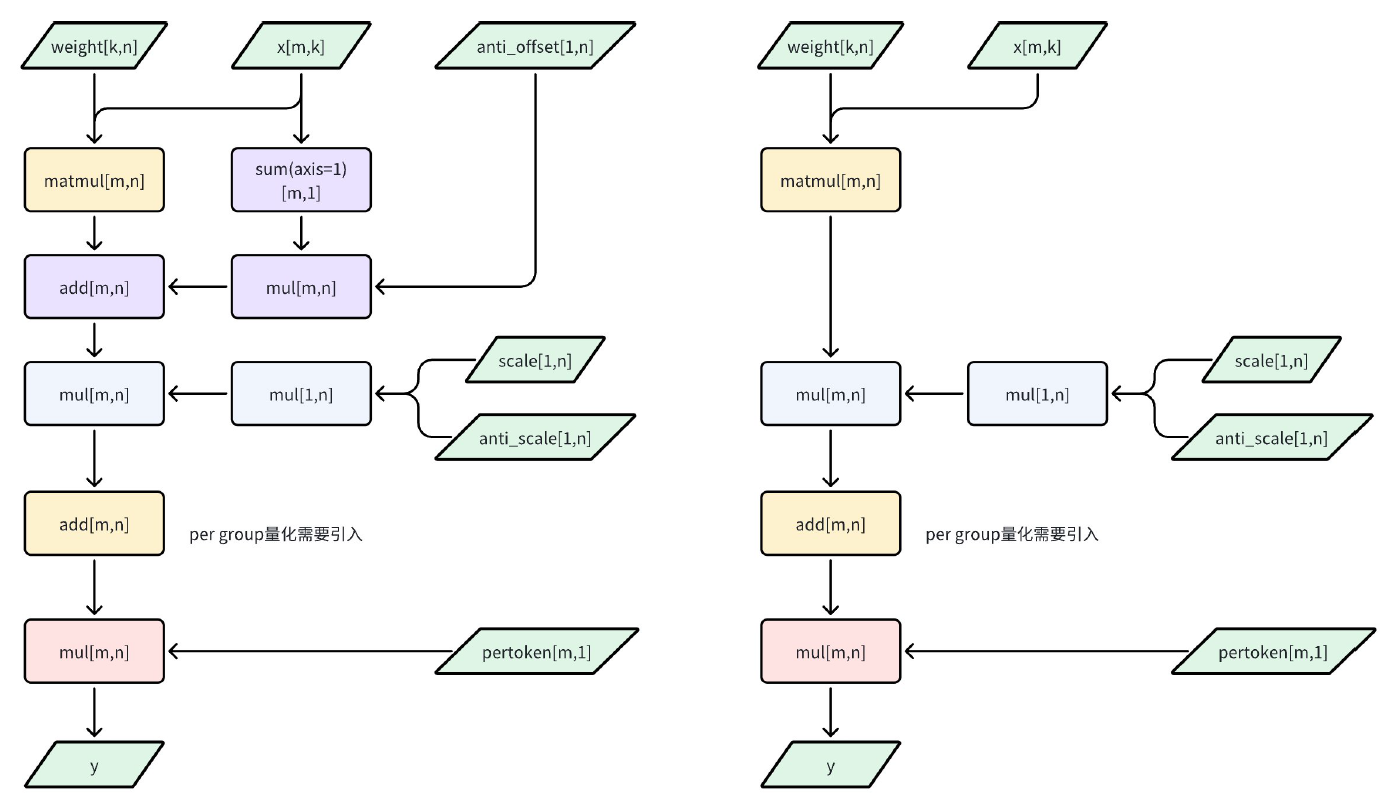
然而,仅依赖W4A8方案并不能充分释放低比特运算的潜力。推理流程中不同阶段对计算和访存的依赖有所区别,Prefill阶段的activation更长,计算更密集;而Decode阶段activation更短,访存压力更大,两者对硬件资源的需求和优化重点不同。面对Decode阶段的访存瓶颈,传统W4A8方案虽然能降低显存占用,但在实际计算时仍需将INT4权重还原为INT8后,再与INT8激活做矩阵乘法,有冗余的反量化计算开销。
因此,我们将W4A8量化方案与昇腾硬件微架构特性结合优化,创新性地提出MSD(Mixed-precision Split-activation Decomposition,混合精度激活拆分分解)方案,将INT8激活拆分为高、低两路INT4,并直接与INT4权重进行计算,用“高位×16+低位”合成,在保证结果等价于原始INT8×INT4计算结果的同时,大幅降低KV Cache和参数存储需求,提升单卡batch size和上下文的支持长度。
分层量化方案设计
W4A8量化方案采用三层量化scale设计,实现了精细化的量化控制,其数学公式表达如下:
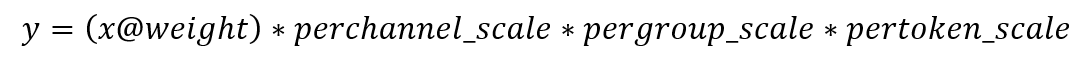
其中量化scale分别为:
(1) Per-channel scale:针对weight的通道级量化参数,保证不同通道间的精度平衡
(2) Per-group scale:针对weight的分组级量化参数,提供更细粒度的量化控制
(3) Per-token scale:针对activation的token级量化参数,动态适应不同输入的分布特性
这种多层级的量化策略能够更好地适应不同数据分布的特点,有效降低量化误差。实践中发现,per-group量化对模型精度的提升较为轻微,所以实践中一般可以不采用per-group量化。
前处理:完成MSD方案拆分过程
MSD方案的核心是将单一INT8激活拆分为两个INT4分量,这个拆分过程在前处理中完成。假设原始INT8激活为x_int8,那么其拆分过程可以表示为:
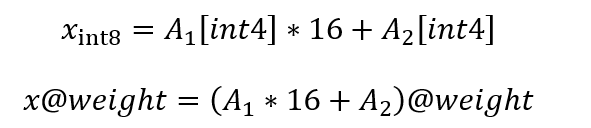
其中A1[int4]和A2[int4]分别为activation的高4位和低4位的INT4表示。
当INT8被拆分为两个INT4时,由于INT4的符号位决定了其范围在[-8, 7],而低4位的最高有效位(即符号扩展)会带来一个偏移量,具体就是8*weight。为了保证拆分的精度,需要将拆分操作变型为如下过程:
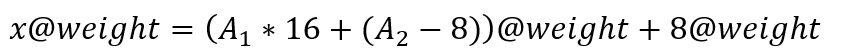
这个多余项在所有INT8拆分为INT4的操作中是固定的,等价于每个权重通道都引入了一个偏置项。在GroupedMatmul的具体实现中,通常将这部分多余项放入bias参数中,通过离线计算提前补偿,从而保证推理精度和性能。下图展示了前处理的计算流程:
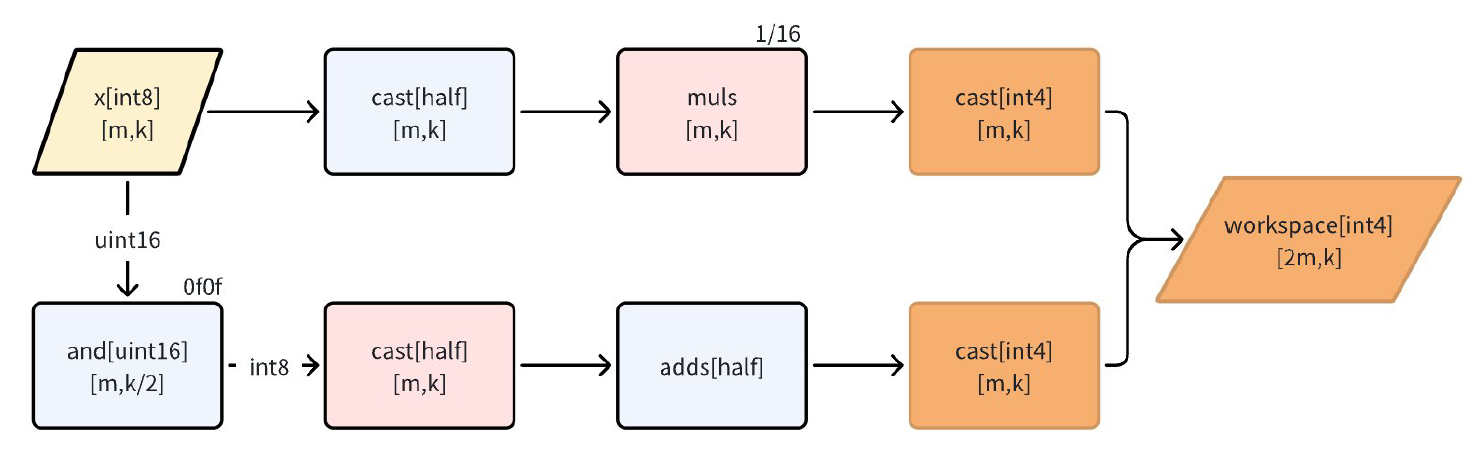
MatMul过程
1. Per-channel和per-group scale的融合
权重首先以per-channel FP16 scale进行粗量化,得到中间的INT8权重。然后对INT8权重再做per-group INT4量化,得到最终的INT4权重和per-group scale。
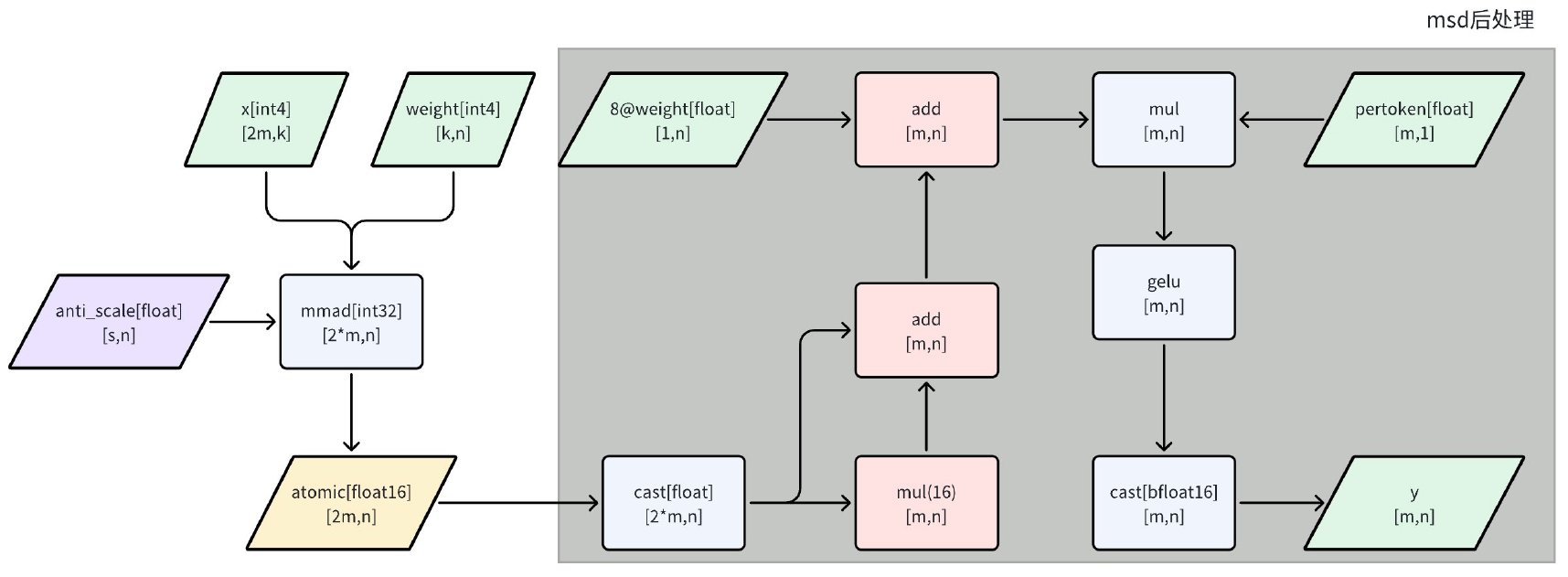
如上图所示,x与weight被拆分后完成INT4矩阵乘。在实际推理时,为了提升效率,per-channel scale和per-group scale会离线融合成一个总scale(图中的anti-scale),这样可以在GEMM输出阶段一次性完成浮点还原,减少多次逐步缩放带来的性能损耗。
融合后的scale一般为total_scale = perchannel_scale * pergroup_scale。这样,矩阵乘法主环节只需用整数计算,最后输出时统一乘以融合后的scale即可。
2. GEMM的per-group累加实现
Per-group scale是针对权重的分组量化,每组权重共用一个scale。在GEMM实现中,通常沿着k轴(即输入通道)切分,每g个通道为一组(g为group size),每组使用独立的scale。
在做矩阵乘法时,需要将输入矩阵X(已分解为INT4)与权重矩阵W(INT4,已分组)分块处理。对每个group,通过total scale将INT4权重直接解码为FP16。具体而言,每进行一组累加,就应用对应的per-group scale。
后处理:合成并反量化输出结果
W4A8量化后处理主要包括三个步骤:高低位结果合成、bias补偿、反量化(per-token scale)。如下图,matmul的结果在图中表示为C,经过后处理后输出的结果为y。
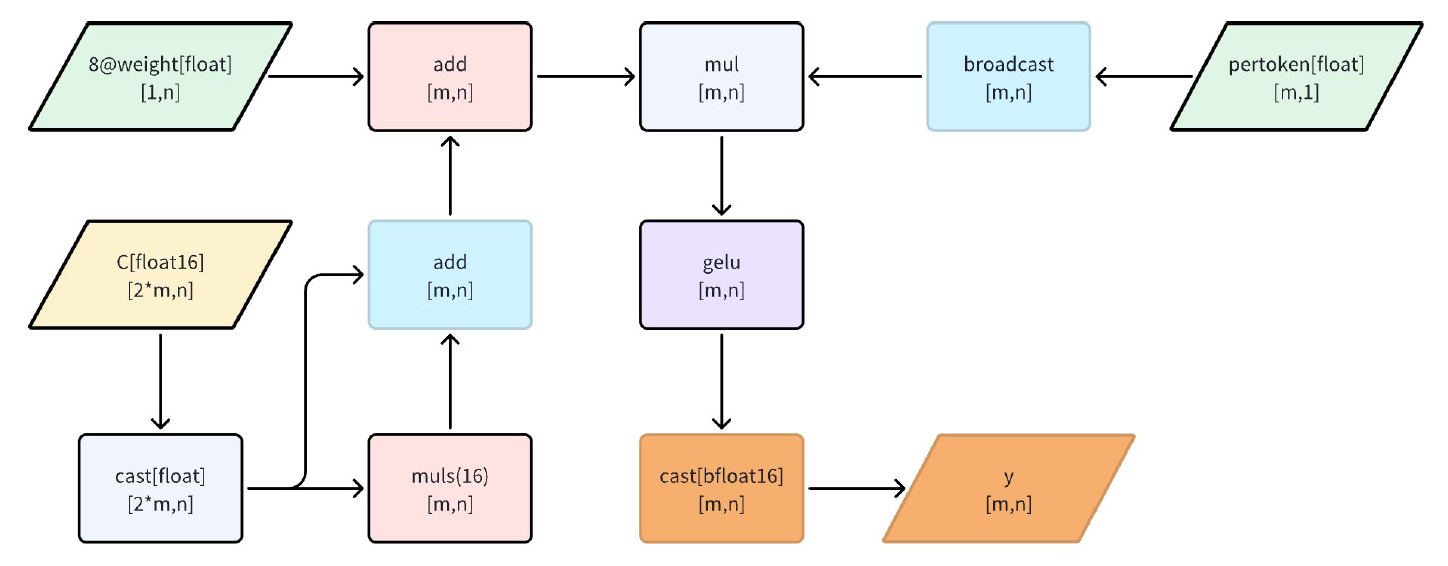
下面详细介绍各环节的原理和实现方式:
(1) 高低位结果合成:在W4A8方案中,INT8激活被拆分为高4位和低4位。为还原INT8原始乘法的效果,需要将高4位的结果左移4位(即乘以16),再与低4位结果相加。这样可以保证拆分计算后,数值与直接INT8×INT4乘法结果一致。
(2) BIAS余量补偿:拆分INT8为两个INT4时,由于符号扩展和量化区间的差异,会引入一个额外的常量项(8×W×scale)。这个多余项在量化离线阶段提前计算,并作为bias参数加到最终输出上,补偿拆分带来的偏移,保证数值精度。在实际后处理时,直接将该bias向量加到矩阵乘法的结果上即可,无需额外计算,且不会影响推理效率。
(3) Per-token反量化:W4A8方案通常采用per-token scale对激活进行量化,推理后需反量化还原浮点结果。Per-token反量化中包含每个token(即每一行激活)独立的量化尺度,能够动态适应不同输入分布,提升精度。这种逐token的反量化方式,能有效降低量化误差,尤其适合大模型推理中的动态输入场景。
至此,W4A8量化与MSD方案的所有主流程均在整数域内完成,充分利用昇腾硬件对低比特整数计算的支持,减少主循环的访存和运算瓶颈,为LLM的高效推理提供了关键支撑,极大提升大模型推理的响应速度和服务能力。基于W4A8方案的DeepSeek R1单机部署实践表明,其最大BatchSize达到了W8A8方案的3.1倍;同时,W4A8+MSD方案在Decode阶段的性能更是达到了W8A8的1.3~1.7倍。
结语
综上所述,GroupedMatmul W4A8量化与MSD方案的结合,为LLM推理带来了显存占用与计算效率的双重突破。通过创新的激活拆分与多尺度量化策略,不仅显著降低了显存需求,还为模型在实际部署中的高效运行提供了坚实保障。随着大模型应用场景的不断拓展,这类极致优化的量化技术将成为推动AI产业落地和普及的关键力量。
GroupedMatmul算子功能通过CANN软件包使能,社区版资源下载地址:
https://www.hiascend.com/developer/download/community/result?module=cann
算子接口定义为:
aclnnStatus aclnnGroupedMatmulV4GetWorkspaceSize(const aclTensorList *x, const aclTensorList *weight, const aclTensorList *biasOptional, const aclTensorList *scaleOptional,
const aclTensorList *offsetOptional, const aclTensorList *antiquantScaleOptional, const aclTensorList *antiquantOffsetOptional, const aclTensorList *perTokenScaleOptional,
const aclTensor *groupListOptional, const aclTensorList *activationInputOptional, const aclTensorList *activationQuantScaleOptional, const aclTensorList *activationQuantOffsetOptional,
int64_t splitItem, int64_t groupType, int64_t groupListType, int64_t actType, aclTensorList *out, aclTensorList *activationFeatureOutOptional, aclTensorList *dynQuantScaleOutOptional,
uint64_t *workspaceSize, aclOpExecutor **executor)
aclnnStatus aclnnGroupedMatmulV4(void* workspace, uint64_t workspaceSize, aclOpExecutor* executor, aclrtStream stream)详细接口文档可参考昇腾社区API描述: