



【昇腾热点算子大解密】RazorAttention突破长序列KV Cache压缩瓶颈,实现最高70%压缩率
发表于 2025/07/09
长序列输入场景下大语言模型中的KV Cache访存挑战
在大语言模型(LLM)的实际应用中,如长文档分析场景,KV Cache的访存开销问题日益凸显。KV Cache机制通过缓存历史token的key与value空间映射,来避免重计算,节省后续decode阶段的计算复杂度。然而,随着输入序列的延长,KV Cache所占用的空间会呈线性增长,总体达到O(seq_len)的空间复杂度,导致显存消耗迅速增加(极端情况下KV Cache与模型权重的显存占比可达到9:1),进而影响模型推理性能、限制其部署。如何优化KV Cache的存储机制,平衡计算效率与显存消耗,已成为当前LLM高效化应用的重要挑战。
RazorAttention: 基于Attention可解释性的静态长序列KV Cache压缩算法
目前,业界主流的KV Cache压缩算法均采用实时动态压缩策略,即在线计算注意力分数(与FlashAttention不兼容)或基于Top-k筛选稀疏模式。然而,这些压缩策略会拖慢推理速度,在实际部署中往往难以适用。因此,静态KV Cache压缩成为了一条极具实用价值的探索路线。
RazorAttention的灵感来源于Anthropic 2022年的研究论文《In-context Learning and Induction Heads》。该论文揭示了Decoder-Only架构的大语言模型独有的上下文学习能力(In-Context Learning),并发现部分注意力头和模型的上下文学习能力强相关,文中称之为具有推断能力的Induction Heads。而大模型的长序列能力,本质上是上下文学习能力的一个子集,因此我们进一步思考,并展开深入研究,创新性地采用了静态压缩策略。实验表明,RazorAttention能够在保持高精度(误差<1%)的同时,静态压缩高达70%的KV Cache内存占用,为用户大大节约AI大模型推理部署的成本。
从ALiBi编码场景到RoPE编码场景:“不同注意力头拥有不同视野”
以ALiBi位置编码的模型为例,理论分析表明,不同注意力头拥有不同的视野范围,因此可以通过动态调整每个头的KV Cache大小来实现高效压缩。具体而言,首先计算每个头的有效视野长度Lh,并只保留最近的Lh个token在KV Cache中,丢弃距离较远的token。这样可以保证在模型精度不变的前提下,大幅减少存储空间的开销。
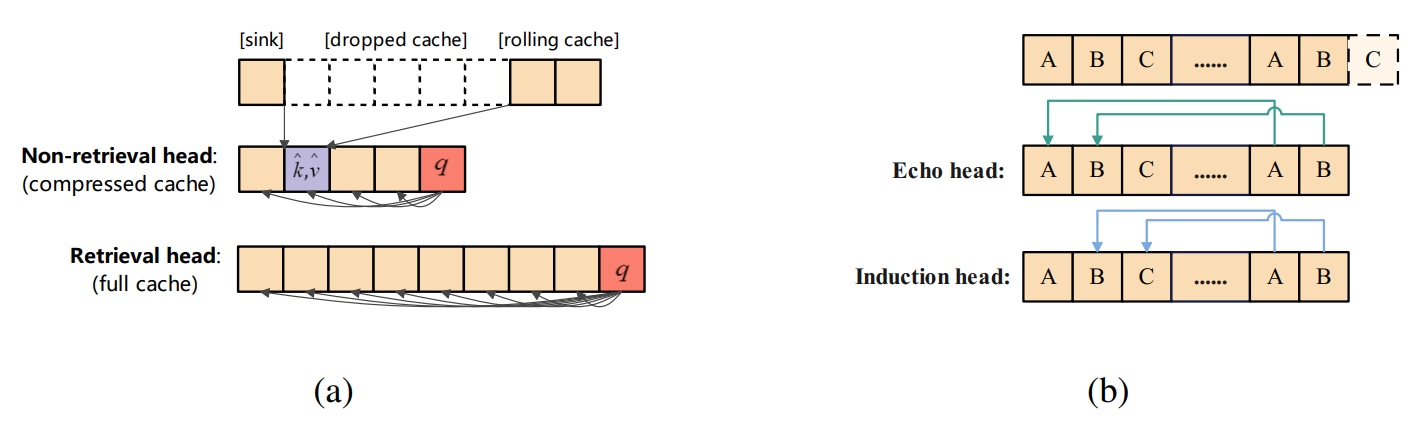
进一步研究发现,“不同注意力头拥有不同视野”的结论可以扩展到任意位置编码(如RoPE)的大语言模型。RazorAttention在Induction Heads基础上,进一步识别出Echo Heads同样对长文本任务起到关键作⽤,并将二者统称为检索头(Retrieval Heads)。检索头通常能有效捕捉长距离依赖关系,对输入拥有全局视野,因此其对应的KV Cache也⾮常重要:
(1) Echo Head:关注前文中与当前token相同的token
(2) Induction Head:关注前文中与当前token相同的下一个token
在压缩算法设计上,RazorAttention对检索头的KV Cache进行保护,确保上下文当中重要且主要信息不丢失;而对于非检索头对应的KV Cache,只保留Attention Sink + Local Attention,其它KV Cache直接丢弃,以达到压缩的目的。此外,RazorAttention提出了补偿token(Compensation token),对于丢弃掉的KV Cache以平均值形式保留在非检索头中,达到保护非检索头的局部视野的效果。基于RoPE位置编码的KV Cache压缩原理如下:

基于Attention可解释性的静态压缩,有效平衡模型精度和推理性能
作为一种静态KV Cache压缩算法,RazorAttention具备两大核心优势:
(1) 零动态计算开销:其压缩策略与实时输入无关,类似PTQ仅需少量样本离线校准即可确定Attention稀疏模式,部署轻量便捷;
(2) 广泛兼容性:可与FlashAttention/PagedAttention等主流融合算子兼容,且几乎不引入额外计算开销。实际部署数据显示,在Llama3-70B、GLM4-9B-1M等模型的长序列场景中,端到端吞吐量提升20%以上。
可解释性方面,在LongBench和大海捞针实验中,RazorAttention都展现出了优于大多数已有压缩算法的效果,且近乎实现语义无损压缩。
下图表格使用了Qwen1.5、Llama2、Llama3和Baichuan作为大语言模型的典型代表(涵盖MHA和GQA架构,ALiBi编码和RoPE编码场景),在LongBench数据集上进行长序列评估,结果显示RazorAttention算法精度损失极低,验证了大语言模型的长序列能力主要来源于检索头,其对于全局视野的信息则主要来源于检索头的KV Cache。
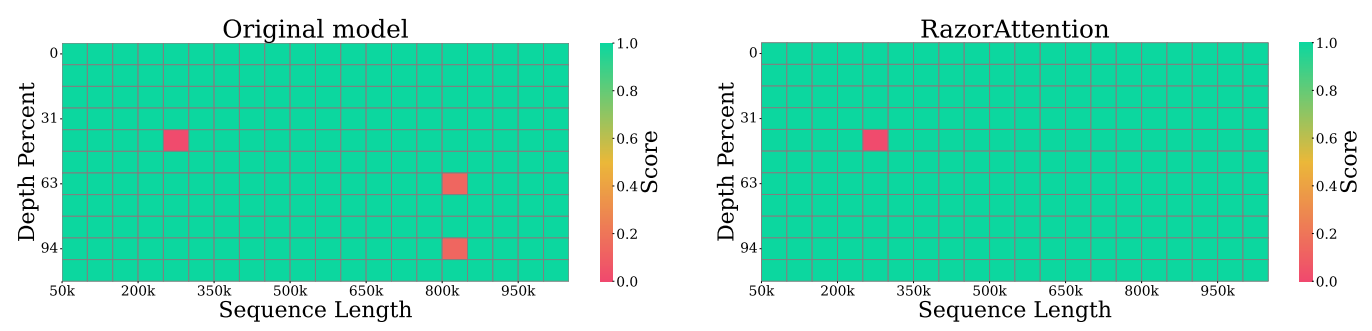
大海捞针任务的测试结果进一步证实,RazorAttention能够完整保留原始上下文中的语义信息,在1M长输入场景下也有效。
针对大语言模型的KV Cache显存占用问题,RazorAttention通过提前识别出检索头与非检索头,并对这两类注意力头的KV Cache执行不同的压缩策略,从而达到静态压缩50~70% KV Cache的效果。
RazorAttention的相关研究已通过论文进行发布,期待与业界共同推进LLM高效化技术的发展。
论文标题:RazorAttention: Efficient KV Cache Compression Through Retrieval Heads
论文链接:https://openreview.net/pdf?id=tkiZQlL04w
作者单位:Huawei Technologies Co., Ltd

结语
随着大语言模型的广泛应用,长序列处理能力已成为模型发展的必然趋势。如何高效压缩KV Cache,RazorAttention算法通过静态压缩策略给出了一种解答。未来,我们将持续探索更高效的KV Cache优化方案,结合动态稀疏化、量化等技术进一步突破长序列推理的访存瓶颈,推动大语言模型在超长上下文理解、实时交互等场景的落地应用。
目前RazorAttention算法已产品化集成在昇腾MindIE/MindStudio,支持主流8K~1M长序列KV Cache压缩。模型的压缩窗口配置通过昇腾推理工具链msit获得,可参考:
以压缩Alibi编码的Baichuan2-13B为例:
(1) 参考环境准备,完成CANN开发环境的部署、PyTorch 2.1.0及以上版本的安装及Python环境变量的配置。执行命令安装如下依赖。
pip3 install numpy==1.26.4
pip3 install transformers==4.43.1
pip3 install torch==2.1.0 # 安装CPU版本的PyTorch 2.1.0(不依赖torch_npu)
(2) 用户需要自行准备模型、权重文件。本样例以Baichuan2-13B为例,从该网站下载权重文件,并上传至服务器的“baichuan 2-13b”文件夹,目录示例如下:
config.json
configuration_baichuan.py
cut_utils.py
generation_config.json
generation_utils.py
handler.py
model-00001-of-00003.safetensors
model-00002-of-00003.safetensors
model-00003-of-00003.safetensors
modeling_baichuan_cut.py
modeling_baichuan.py
model.safetensors.index.json
pytorch_model.bin.index.json
quantizer.py
special_tokens_map.json
tokenization_baichuan.py
tokenizer_config.json
tokenizer.model
(3) 新建模型的压缩脚本run.py,将如下样例代码导入run.py文件,并执行。
from msmodelslim.pytorch.ra_compression import RACompressConfig, RACompressor
from transformers import AutoTokenizer, AutoModelForCausalLM
config = RACompressConfig(theta=0.00001, alpha=100) # 压缩类的配置,需根据实际情况进行修改
input_model_path = "/data1/models/baichuan/baichuan2-13b/float_path/" # 模型权重文件的保存路径,需根据实际情况进行修改
save_path = "./win.pt" # 生成压缩窗口的路径,需根据实际情况进行修改
tokenizer = AutoTokenizer.from_pretrained(pretrained_model_name_or_path=input_model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(pretrained_model_name_or_path=input_model_path, trust_remote_code=True).float().cpu() # 不支持使用npu方式进行加载
ra = RACompressor(model, config)
ra.get_alibi_windows(save_path)
(4) 执行以下命令,启动长序列压缩任务,并在“baichuan 2-13b”文件夹的路径下获取.pt文件。python3 run.py .pt文件可用于后续的推理部署任务,具体请参见MindIE的“加速库支持模型列表”章节中已适配量化的模型。
python3 run.pyCANN软件包中的ATB加速库接口PagedAttentionOperation和ReshapeAndCacheOperation通过参数compressType选择是否开启多头自适应压缩(RazorAttention)特性。CANN社区版资源下载地址:
https://www.hiascend.com/developer/download/community/result?module=cann
详细ATB接口文档可参考昇腾社区API描述:
(1) 多头自适应压缩(alibi场景)
(2) 多头自适应压缩(rope场景)