精度问题概述和场景
随着大语言模型技术的迅速发展,尤其是在诸如ChatGPT、DeepSeek等应用的引领下,大模型迅速成为AI界热点。大模型训练需要强大的算力支撑,涉及数据、模型、框架、算子、硬件等诸多环节。由于规模巨大,训练过程复杂,经常出现精度问题。
训练精度问题是多种因素共同作用的结果。主要表现为训练收敛不及预期,如loss起飞、毛刺、NaN、下游任务评测效果变差等。
训练精度场景可分为有标杆和无标杆2类。
- 有标杆对应迁移场景,即用户将原本在标杆(如GPU、其他训练框架)上训练的大语言模型或者其他类型深度神经网络的训练迁移到NPU上进行训练。
- 无标杆对应原生开发场景,即用户直接在NPU上进行模型搭建及训练。
其中,本文聚焦主流的有标杆迁移场景,主要表现为NPU训练过程和结果与标杆(GPU或NPU的其他框架)上的训练过程和结果不一致且偏差超过容忍阈值,我们称之为不对齐。该场景具体可再细分为以下几类现象:
- 首step差异,即第0步或前几步loss就已与标杆相比出现差异,平均误差大于1%,如下图所示:图1 首step差异
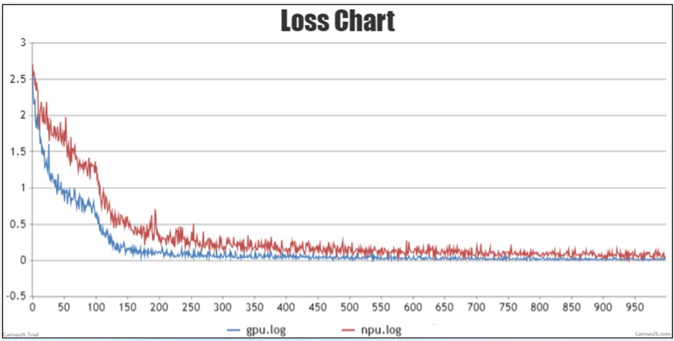
- 长稳loss差异,即前期loss拟合但后期与标杆差异变大,平均误差大于1%,如下图所示图2 长稳loss差异
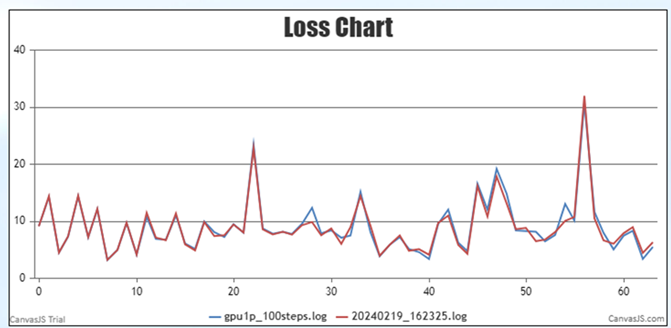
- 溢出或NaN,即迁移后相较于标杆出现更频繁的溢出、NaN或毛刺,如下图所示:图3 溢出或NaN

- 训练中loss与标杆相比差异较小但下游指标差异大
值得注意的是,哪怕属于同一类问题现象,其根因也复杂各异。本文介绍大模型训练精度问题定位时的整体定位思路和标准流程,并介绍其对应的经典定位案例及详细过程,以帮助用户快速熟悉精度问题定位流程及方法。