快速介绍
Triton简介
Triton Inference Server是高性能开源推理服务框架,专为简化和加速机器学习模型在生产环境中的部署而设计。支持多种框架,如TensorFlow、PyTorch和ONNX等,且支持多种硬件平台上执行推理任务。Triton提供了灵活的模型管理、自动批处理、动态调度以及多模型并行推理等功能,使得开发者可以轻松扩展和优化模型的推理服务,从而更好地满足实时和批处理推理的需求。
基于MindIE LLM向Triton提供的统一接口LLM Manager进行了适配开发,主要为基于开源服务化框架进行深度业务适配与客户提供兼容方案,使其能够在昇腾硬件上运行Triton,协助客户降低迁移成本。
Triton适配昇腾整体方案介绍
采用非侵入性适配,将Triton_Backend提供的C++后端接口逻辑与MindIE LLM推理运行逻辑对齐并打通,确保Triton能够正确的调用MindIE的推理功能并返回响应结果。
适配过程主要分为两部分:
- 面向Tritonserver中core层的北向(上层)接口设计,Triton提供了定制化接口函数,主要负责对Backend、Model、ModelInstacne进行实际初始化与销毁,同时接收来自core层的请求并设置后续的执行动作。
- 面向MindIE LLM的南向(下层)接口设计,MindIE LLM提供给Backend唯一核心接口类LLM Manager,具有模型推理和请求调度的能力。在适配过程中,需要实现推理请求的读取、解析和转换,并发送给LLM调度执行,最后将底层推理出的响应发送回Tritonserver侧。
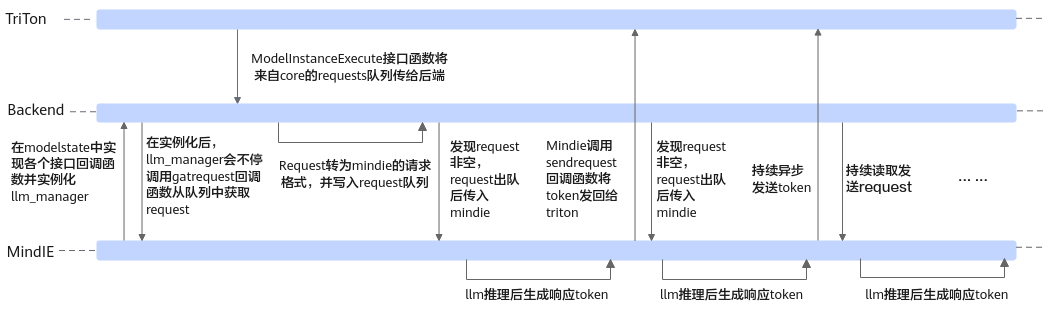
Triton推理服务框架搭载MindIE在适配后的整体运行逻辑如图1所示。
支持版本特性与模型
|
支持的Triton版本 |
浮点 |
量化 |
MoE |
|---|---|---|---|
|
v24.02 |
同MindIE LLM |
同MindIE LLM |
同MindIE LLM |