详细说明
vllm_npu_0.4.2版本(即:vLLM 0.4.2版本昇腾框架适配代码)中修改了attention、engine、executor、model_executor、usage、worker六个模块,与vLLM原生框架中的同名模块一一对应进行热替换适配。vllm_npu_0.4.2版本可参考参考代码制作。
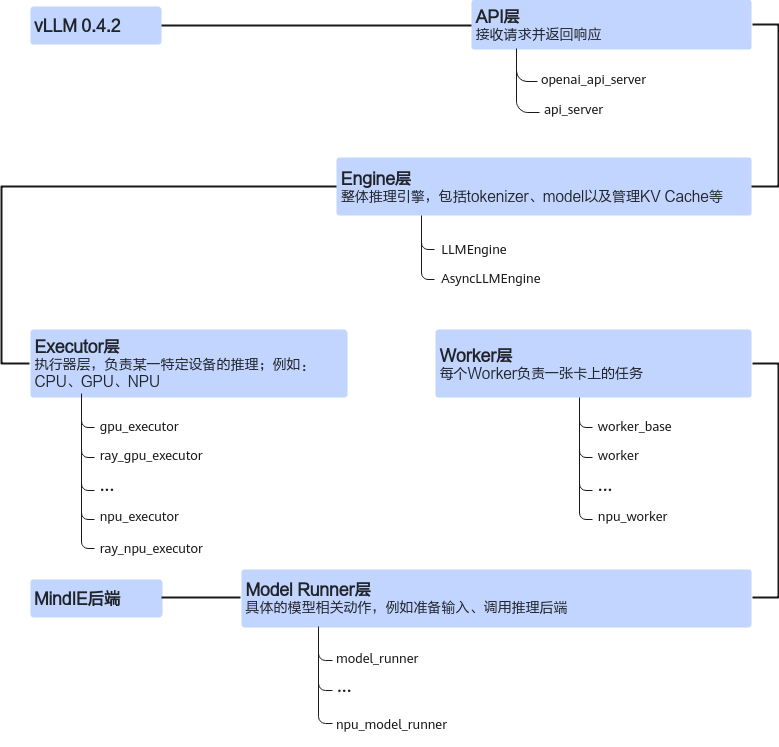
模块 |
简介 |
|---|---|
attention模块 |
该模块重写了vLLM框架中的AttentionBackend类,对昇腾环境下对接MindIE LLM所需要的attention计算数据以及KV Cache的shape等关键信息进行了定义,并在该模块的初始化文件中对原框架的get_atten_backend函数进行了热替换,从而使得框架在昇腾环境下会运行该模块中的attention后端类。 |
engine模块 |
该模块重写了vLLM引擎的from_engine_args函数,vLLM 0.4.2版本中引擎会通过该类方法进行实例化,并在其中根据运行环境信息选择对应的不同executor;这里我们加入了新的判断逻辑分支,当检测到运行在昇腾环境下时,引擎会选择vllm_npu补丁包中定义的AscendExecutor和RayAscendExecutor类分别去进行单卡推理和多卡推理。另外,这里对vLLM原生框架的离线同步推理引擎LLMEngine和在线异步推理引擎AsyncLLMEngine的from_engine_args函数分别进行了重写替换,替换操作发生在该模块的初始化文件中。 |
executor模块 |
该模块中主要实现了四个executor类,其中AscendExecutor和AscendExecutorAsync用于单卡环境的同步和异步调用模式下的推理,RayAscendExecutor和RayAscendExecutorAsync用于多卡ray分布式环境的同步和异步调用模式下的推理。 此外,在ray_utils.py中对initialize_ray_cluster函数进行了重写,主要是因为在昇腾的npu环境下ray无法自动识别到npu的数量,因此需要手动指定。 |
model_executor模块 |
该模块为实际对接MindIE LLM模型推理与后处理的位置,其中包括layers模块和models模块,分别对应后处理和模型推理。
|
usage模块 |
该模块中的UsageMessage类的_report_usage_once成员函数进行了重写,修改了其中的torch.cuda.get_device_properties函数的使用方式,该函数目前在昇腾环境上的使用方式和GPU环境上有所差异。 |
worker模块 |
该模块实现了AscendWorker类,以供executor模块中的executor类进行调用;实现了AscendModelRunner类在AscendWorker中进行调用。 替换原生框架中CacheEngine的_allocate_kv_cache函数,主要是对生成kv_cache的数据格式进行了修改,从Torch.tensor修改为Tuple[torch.Tensor, torch.Tensor]。 AscendModelRunner类继承自原生框架中ModelRunner类,主要是为了对原生的load_model,execute_model和profile_run函数进行重写:vLLM新版本中执行模型调用时分为了先调用模型生成hidden_states,再使用一个process处理hidden_states得到logits,再进行最后的sample操作得到结果;而在MindIE模型仓中前两步操作是通过模型调用一步完成的,因此在这里进行了修改;profile_run函数的修改主要是为了构造warmup时使用的fake data。 |
- layers模块实现代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250
class AscendSampler(nn.Module): def __init__(self, mindie_model): super().__init__() self.mindie_model = mindie_model self.include_gpu_probs_tensor = False def forward( self, logits: torch.Tensor, sampling_metadata: SamplingMetadata, ) -> Optional[SamplerOutput]: _, vocab_size = logits.shape mindie_sampling_data, mindie_sampling_param = self.construct_data(sampling_metadata, vocab_size) probs = torch.softmax(logits, dim=-1, dtype=torch.float) logprobs = torch.log_softmax(logits, dim=-1, dtype=torch.float) next_tokens = self.mindie_model.sample( logits, sampling_data=mindie_sampling_data, sampling_param=mindie_sampling_param, ) sample_results, maybe_sampled_tokens_tensor = recover_data( sampling_metadata=sampling_metadata, sampled_tokens=next_tokens, logprobs=logprobs, include_gpu_probs_tensor=self.include_gpu_probs_tensor, ) if self.include_gpu_probs_tensor: if maybe_sampled_tokens_tensor is None: raise RuntimeError("maybe_sampled_tokens_tensor is None") on_device_tensors = (probs, logprobs, maybe_sampled_tokens_tensor) else: on_device_tensors = None # Get the logprobs query results. prompt_logprobs, sample_logprobs = _get_logprobs( logprobs, sampling_metadata, sample_results) return _build_sampler_output(sample_results, sampling_metadata, prompt_logprobs, sample_logprobs, on_device_tensors=on_device_tensors) def construct_data( self, sampling_metadata: SamplingMetadata, vocab_size: int, ) -> Tuple[SamplingData, SamplingParam]: all_input_tokens: List[List[int]] = [] prompt_tokens: List[List[int]] = [] output_tokens: List[List[int]] = [] top_ks: List[int] = [] temperatures: List[float] = [] top_ps: List[float] = [] min_ps: List[float] = [] presence_penalties: List[float] = [] frequency_penalties: List[float] = [] repetition_penalties: List[float] = [] sampling_seeds: List[int] = [] sample_indices: List[int] = [] do_samples: List[bool] = [] # To Do do_penalties = False do_top_p_top_k = False do_min_p = False greedy_flag = False if sampling_metadata.seq_groups is None: raise RuntimeError("sampling_metadata.seq_group is None, no data received.") for seq_group in sampling_metadata.seq_groups: do_samples.append(seq_group.do_sample) seq_ids = seq_group.seq_ids sampling_params = seq_group.sampling_params temperature = sampling_params.temperature p = sampling_params.presence_penalty f = sampling_params.frequency_penalty r = sampling_params.repetition_penalty top_p = sampling_params.top_p min_p = sampling_params.min_p is_greedy = sampling_params.sampling_type == SamplingType.GREEDY seed = sampling_params.seed if seed is None: if is_greedy: seed = 0 else: lo, hi = torch.iinfo(torch.long).min, torch.iinfo(torch.long).max seed = random.randint(lo, hi) if is_greedy: greedy_flag = True # k should not be greater than the vocab size. top_k = min(sampling_params.top_k, vocab_size) top_k = vocab_size if top_k == -1 else top_k if temperature < _SAMPLING_EPS: temperature = 1.0 if not do_top_p_top_k and (top_p < 1.0 - _SAMPLING_EPS or top_k != vocab_size): do_top_p_top_k = True if not do_min_p and min_p > _SAMPLING_EPS: do_min_p = True if not do_penalties: if abs(p) >= _SAMPLING_EPS: do_penalties = True elif abs(f) >= _SAMPLING_EPS: do_penalties = True elif abs(r - 1.0) >= _SAMPLING_EPS: do_penalties = True is_prompt = seq_group.is_prompt if (seq_group.is_prompt and sampling_params.prompt_logprobs is not None): # For tokens in the prompt that we only need to get # their logprobs query_len = seq_group.query_len if query_len is None: raise RuntimeError("query_len is None") prefill_len = len(seq_group.prompt_logprob_indices) temperatures += [temperature] * prefill_len sampling_seeds += [seed] * prefill_len top_ps += [top_p] * prefill_len top_ks += [top_k] * prefill_len min_ps += [min_p] * prefill_len presence_penalties += [0] * prefill_len frequency_penalties += [0] * prefill_len repetition_penalties += [1] * prefill_len prompt_tokens.extend([] for _ in range(prefill_len)) output_tokens.extend([] for _ in range(prefill_len)) all_input_tokens.extend([] for _ in range(prefill_len)) if seq_group.do_sample: sample_lens = len(seq_group.sample_indices) if sample_lens != len(seq_ids): raise ValueError("sample_lens != len(seq_ids)") for seq_id in seq_ids: seq_data = seq_group.seq_data[seq_id] prompt_tokens.append(seq_data.prompt_token_ids) output_tokens.append(seq_data.output_token_ids) all_input_tokens.append(seq_data.prompt_token_ids + seq_data.output_token_ids) temperatures += [temperature] * len(seq_ids) sampling_seeds += [seed] * len(seq_ids) top_ps += [top_p] * len(seq_ids) top_ks += [top_k] * len(seq_ids) min_ps += [min_p] * len(seq_ids) presence_penalties += [p] * len(seq_ids) frequency_penalties += [f] * len(seq_ids) repetition_penalties += [r] * len(seq_ids) repetition_penalties = np.array(repetition_penalties, dtype=np.float32) frequency_penalties = np.array(frequency_penalties, dtype=np.float32) presence_penalties = np.array(presence_penalties, dtype=np.float32) temperatures = np.array(temperatures, dtype=np.float32) top_ks = np.array(top_ks, dtype=np.int32) top_ps = np.array(top_ps, dtype=np.float32) sampling_seeds = np.array(sampling_seeds) do_samples = np.array(do_samples) max_tokens_len = max([len(tokens) for tokens in all_input_tokens], default=0) padded_all_input_tokens = [ tokens + [vocab_size] * (max_tokens_len - len(tokens)) for tokens in all_input_tokens ] padded_all_input_tokens = np.array(padded_all_input_tokens, dtype=np.int32) output_max_len = max([len(tokens) for tokens in output_tokens], default=0) padded_output_tokens = [ tokens + [vocab_size] * (output_max_len - len(tokens)) for tokens in output_tokens ] padded_output_tokens = np.array(padded_output_tokens, dtype=np.int32) all_input_ids_tensor = _to_tensor( padded_all_input_tokens, torch.int32 ) if padded_all_input_tokens is not None else None output_ids_tensor = _to_tensor( padded_output_tokens, torch.int32 ) if padded_output_tokens is not None else None mindie_sampling_data = SamplingData( all_input_ids=all_input_ids_tensor, output_ids=output_ids_tensor ) if greedy_flag: mindie_sampling_param = None else: mindie_sampling_param = SamplingParam.from_numpy( repetition_penalty=repetition_penalties, frequency_penalty=frequency_penalties, presence_penalty=presence_penalties, temperature=temperatures, top_k=top_ks, top_p=top_ps, seed=sampling_seeds, do_sample=do_samples, to_tensor=_to_tensor, ) return (mindie_sampling_data, mindie_sampling_param) def recover_data( sampling_metadata: SamplingMetadata, sampled_tokens: np.ndarray, logprobs: torch.Tensor, include_gpu_probs_tensor: bool, ) -> Tuple[SampleResultType, Optional[torch.Tensor]]: categorized_seq_group_ids: Dict[SamplingType, List[int]] = {t: [] for t in SamplingType} categorized_sample_indices = sampling_metadata.categorized_sample_indices for i, seq_group in enumerate(sampling_metadata.seq_groups): sampling_params = seq_group.sampling_params sampling_type = sampling_params.sampling_type categorized_seq_group_ids[sampling_type].append(i) sample_results_dict: Dict[int, Tuple[List[int], List[int]]] = {} sample_metadata = {} # Create output tensor for sampled token ids. if include_gpu_probs_tensor: sampled_token_ids_tensor = torch.empty(logprobs.shape[0], 1, dtype=torch.long, device=logprobs.device) else: sampled_token_ids_tensor = None for sampling_type in SamplingType: sample_indices = categorized_sample_indices[sampling_type][:, 0] num_tokens = len(sample_indices) if num_tokens == 0: continue seq_group_id = categorized_seq_group_ids[sampling_type] seq_groups = [sampling_metadata.seq_groups[i] for i in seq_group_id] sample_metadata[sampling_type] = (seq_group_id, seq_groups) for sampling_type in SamplingType: if sampling_type not in sample_metadata: continue (seq_group_id, seq_groups) = sample_metadata[sampling_type] if sampling_type in (SamplingType.GREEDY, SamplingType.RANDOM, SamplingType.RANDOM_SEED): sample_results = normal_wrap(seq_groups, sampled_tokens) elif sampling_type == SamplingType.BEAM: sample_results = beam_wrap(seq_groups, sampled_tokens) sample_results_dict.update(zip(seq_group_id, sample_results)) sample_results = [ sample_results_dict.get(i, ([], [])) for i in range(len(sampling_metadata.seq_groups)) ] return sample_results, sampled_token_ids_tensor def normal_wrap( selected_seq_groups: List[SequenceGroupToSample], samples: np.ndarray, ): samples = samples.tolist() sample_idx = 0 results: SampleResultType = [] for seq_group in selected_seq_groups: if not seq_group.do_sample: results.append(([], [])) continue seq_ids = seq_group.seq_ids num_parent_seqs = len(seq_ids) parent_ids = list(range(num_parent_seqs)) next_token_ids = [samples[sample_idx]] results.append((next_token_ids, parent_ids)) sample_idx += num_parent_seqs return results
另外,该模块中重写了vLLM框架的get_model和get_architecture_class_name函数,从而将MindIELlmWrapper类引入到vLLM框架中。
- models模块实现代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99
class MindIELlmWrapper(nn.Module): def __init__(self, mindie_model_config, linear_method=None, lora_config=None): super(MindIELlmWrapper, self).__init__() self.mindie_model_config = mindie_model_config self.rank = mindie_model_config['rank'] self.local_rank = mindie_model_config['local_rank'] self.npu_id = self.local_rank self.world_size = mindie_model_config['world_size'] self.mindie_model = None self.sampler = None def forward( self, input_ids: torch.Tensor, positions: torch.Tensor, kv_caches: List[KVCache], attn_metadata: AttentionMetadata, ) -> torch.Tensor: is_prompt = attn_metadata.num_prefill_tokens > 0 if kv_caches[0][0] is None: kv_caches, block_tables, slots = self.create_dummy_kv_cache(attn_metadata, input_ids) else: if is_prompt: block_tables = torch.tensor([0], dtype=torch.int32, device="npu") else: block_tables = attn_metadata.decode_metadata.block_tables slots = attn_metadata.slot_mapping if is_prompt: input_lengths = attn_metadata.prefill_metadata.seq_lens_tensor.to(torch.int32) max_seq_len = int(attn_metadata.prefill_metadata.seq_lens_tensor.max()) lm_head_indices = (attn_metadata.prefill_metadata.seq_lens_tensor.cumsum(dim=-1) - 1).to(torch.int64) else: input_lengths = attn_metadata.decode_metadata.seq_lens_tensor max_seq_len = attn_metadata.decode_metadata.max_seq_len lm_head_indices = None logits = self.mindie_model.forward_tensor(input_ids, positions, is_prompt, kv_caches, block_tables, slots, input_lengths, max_seq_len, lm_head_indices) return logits def compute_logits(self, hidden_states: torch.Tensor, sampling_metadata: SamplingMetadata) -> torch.Tensor: return hidden_states def sample( self, logits: torch.Tensor, sampling_metadata: SamplingMetadata, ) -> Optional[SamplerOutput]: # hidden_states is logits next_tokens = self.sampler(logits, sampling_metadata) return next_tokens def load_weights(self, model_name_or_path: str, cache_dir: Optional[str] = None, load_format: str = "auto", revision: Optional[str] = None): if load_format not in ['auto', 'safetensors', 'pt']: raise ValueError('load-format support [safetensors, pt]') self.weight_dtype = torch.get_default_dtype() torch.set_default_dtype(torch.float32) self.mindie_model = GeneratorTorch(self.mindie_model_config) self.sampler = AscendSampler(self.mindie_model) torch.set_default_dtype(self.weight_dtype) # when warmup, create dummy kvcache, block_tables, slot_mapping def create_dummy_kv_cache(self, attn_metadata, input_ids): dummy_block_num = 1 dummy_block_size = 128 model_runner = self.mindie_model.model_wrapper.model_runner kv_cache = [ ( torch.empty( (dummy_block_num, dummy_block_size, model_runner.num_kv_heads, model_runner.head_size), dtype=self.weight_dtype, device="npu", ), torch.empty( (dummy_block_num, dummy_block_size, model_runner.num_kv_heads, model_runner.head_size), dtype=self.weight_dtype, device="npu", ), ) for _ in range(model_runner.num_layers) ] max_s = max(attn_metadata.prefill_metadata.seq_lens_tensor) max_need_block = math.ceil(max_s / dummy_block_size) batch_size = len(attn_metadata.prefill_metadata.seq_lens_tensor) block_tables = torch.zeros(batch_size, max_need_block, dtype=int, device="npu") slot = [i for i in range(dummy_block_size)] slots = [] warm_up_len = len(input_ids) while warm_up_len > 0: if warm_up_len > dummy_block_size: slots.extend(slot) warm_up_len -= dummy_block_size else: slots.extend(slot[:warm_up_len]) warm_up_len = 0 slots = torch.tensor(slots, dtype=torch.long, device="npu") return kv_cache, block_tables, slots
除了上述的六个模块的适配外,还有一些主模块外的Python文件里的函数需要热替换,包括config.py中的DeviceConfig类中我们引入了NPU作为device_type,在utils.py文件中我们引入了is_ascend()函数用于检测当前运行环境是否为昇腾环境。最后,在npu_adaptor.py,我们对vLLM原框架中导入的一些昇腾环境下不具备的包(例如预编译的cuda算子、triton等)进行了屏蔽操作。
- 多模态模型Qwen-VL支持:
为了适配多模态模型Qwen-VL的推理,需要对vLLM框架中离线推理接口类LLM的generate函数进行修改,以及对AscendModelRunner中构造warmup假数据的部分进行修改,并且自己定义了Qwen-VL的tokenizer需要的多模态输入数据格式,同时定义了一个新的MindIETokenizer类来对接MindIE LLM的前处理,具体的适配细节如下:
首先需要在vllm_npu包里新建entrypoints和transformers_utils两个模块和一个sequence.py文件,entrypoints模块下新建__init__.py和llm.py两个文件,transformers_utils模块下新建__init__.py和mindie_tokenizer.py两个文件。
- 在vllm_npu/sequence.py文件中添加如下新类用于定义Qwen-VL的多模态数据:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
from typing import Dict, List class MultiModalData: """Multi modal input for MindIE LLM. Args: data_list: List of input data in the format of dict. For example: [ {"image": url_of_image1}, {"image": url_of_image1}, {"text": input_prompt1}, {"text": input_prompt1} ] """ def __init__(self, data_list: List[Dict[str, str]]): self.data_list = data_list
- 在vllm_npu/transformers_utils/mindie_tokenizer.py文件中引入了新类MindIETokenizer来对接MindIE LLM的前处理:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61
from typing import List, Optional from transformers import PreTrainedTokenizer from vllm.transformers_utils.tokenizer_group.base_tokenizer_group import ( BaseTokenizerGroup) from vllm.transformers_utils.tokenizer import get_lora_tokenizer, get_lora_tokenizer_async from vllm.lora.request import LoRARequest from atb_llm.runner.tokenizer_wrapper import TokenizerWrapper class MindIETokenizer(BaseTokenizerGroup): """A group of tokenizers that can be used for LoRA adapters.""" def __init__(self, model_path: str): self.tokenizer_wrapper = TokenizerWrapper(model_path) self.tokenizer = self.tokenizer_wrapper.tokenizer self.lora_tokenizers = None self.enable_lora = False def ping(self) -> bool: """Check if the tokenizer group is alive.""" return True def get_max_input_len(self, lora_request: Optional[LoRARequest] = None ) -> Optional[int]: """Get the maximum input length for the LoRA request.""" return 0 def encode(self, prompt: str, request_id: Optional[str] = None, lora_request: Optional[LoRARequest] = None) -> List[int]: tokenizer = self.get_lora_tokenizer(lora_request) return tokenizer.encode(prompt) async def encode_async( self, prompt: str, request_id: Optional[str] = None, lora_request: Optional[LoRARequest] = None) -> List[int]: tokenizer = await self.get_lora_tokenizer_async(lora_request) return tokenizer.encode(prompt) def get_lora_tokenizer( self, lora_request: Optional[LoRARequest] = None ) -> "PreTrainedTokenizer": if not lora_request or not self.enable_lora: return self.tokenizer if lora_request.lora_int_id not in self.lora_tokenizers: tokenizer = (get_lora_tokenizer( lora_request, **self.tokenizer_config) or self.tokenizer) self.lora_tokenizers.put(lora_request.lora_int_id, tokenizer) return tokenizer else: return self.lora_tokenizers.get(lora_request.lora_int_id) async def get_lora_tokenizer_async( self, lora_request: Optional[LoRARequest] = None ) -> "PreTrainedTokenizer": if not lora_request or not self.enable_lora: return self.tokenizer if lora_request.lora_int_id not in self.lora_tokenizers: tokenizer = (await get_lora_tokenizer_async( lora_request, **self.tokenizer_config) or self.tokenizer) self.lora_tokenizers.put(lora_request.lora_int_id, tokenizer) return tokenizer else: return self.lora_tokenizers.get(lora_request.lora_int_id)
- 在vllm_npu/entrypoints/llm.py文件里重新定义generate函数,引入多模态数据的输入接口:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94
import torch from typing import List, Optional, Union from vllm.lora.request import LoRARequest from vllm.outputs import RequestOutput from vllm.sampling_params import SamplingParams from vllm.transformers_utils.detokenizer import Detokenizer from vllm_npu.transformers_utils import MindIETokenizer from vllm_npu.sequence import MultiModalData def generate( self, prompts: Optional[Union[str, List[str]]] = None, sampling_params: Optional[Union[SamplingParams, List[SamplingParams]]] = None, prompt_token_ids: Optional[List[List[int]]] = None, use_tqdm: bool = True, lora_request: Optional[LoRARequest] = None, multi_modal_data_list: Optional[List[MultiModalData]] = None, ) -> List[RequestOutput]: """Generates the completions for the input prompts. Args: prompts: A list of prompts to generate completions for. sampling_params: The sampling parameters for text generation. If None, we use the default sampling parameters. When it is a single value, it is applied to every prompt. When it is a list, the list must have the same length as the prompts and it is paired one by one with the prompt. prompt_token_ids: A list of token IDs for the prompts. If None, we use the tokenizer to convert the prompts to token IDs. use_tqdm: Whether to use tqdm to display the progress bar. lora_request: LoRA request to use for generation, if any. multi_modal_data_list: List of Multi modal data. Each element in this list is organized in the form of List[Dict[str, str]] Returns: A list of `RequestOutput` objects containing the generated completions in the same order as the input prompts. """ if prompts is None and prompt_token_ids is None and multi_modal_data_list is None: raise ValueError("Either prompts or prompt_token_ids of multi_modal_data must be " "provided.") if self.llm_engine.model_config.skip_tokenizer_init \ and prompts is not None: raise ValueError("prompts must be None if skip_tokenizer_init " "is True") if isinstance(prompts, str): # Convert a single prompt to a list. prompts = [prompts] if (prompts is not None and prompt_token_ids is not None and len(prompts) != len(prompt_token_ids)): raise ValueError("The lengths of prompts and prompt_token_ids " "must be the same.") if multi_modal_data_list and self.llm_engine.tokenizer is None: self.llm_engine.tokenizer = MindIETokenizer(self.llm_engine.model_config.model) self.llm_engine.detokenizer = Detokenizer(self.llm_engine.tokenizer) self.llm_engine.output_processor.detokenizer = self.llm_engine.detokenizer if prompts is not None: num_requests = len(prompts) elif multi_modal_data_list is not None: num_requests = len(multi_modal_data_list) else: assert prompt_token_ids is not None num_requests = len(prompt_token_ids) if sampling_params is None: # Use default sampling params. sampling_params = SamplingParams() elif isinstance(sampling_params, list) and len(sampling_params) != num_requests: raise ValueError("The lengths of prompts and sampling_params " "must be the same.") # Add requests to the engine. for i in range(num_requests): prompt = prompts[i] if prompts is not None else None token_ids = None if prompt_token_ids is None else prompt_token_ids[ i] if multi_modal_data_list: token_ids = self.llm_engine.tokenizer.tokenizer_wrapper.tokenize( multi_modal_data_list[i].data_list).tolist() # print(token_ids) self._add_request( prompt, sampling_params[i] if isinstance(sampling_params, list) else sampling_params, token_ids, lora_request=lora_request, # Get ith image while maintaining the batch dim. multi_modal_data=None, ) outputs = self._run_engine(use_tqdm) for output in outputs: token_ids = output.outputs[0].token_ids token_ids_tensor = torch.tensor(token_ids, dtype=torch.int64) mindie_generated_text = self.llm_engine.tokenizer.tokenizer.decode(token_ids_tensor, False) output.outputs[0].text = mindie_generated_text return outputs
- 修改vllm_npu/worker/ascend_model_runner.py文件,将其中从MindIE LLM框架里导入的_prepare_fake_inputs去掉,重新定义该函数如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
def _prepare_fake_inputs( seq_len: int, model_config: ModelConfig): """Prepare fake inputs for profile run.""" if getattr(model_config.hf_config, "visual", None) is not None: img_start_id = model_config.hf_config.visual["image_start_id"] img_end_id = img_start_id + 1 img_patch_id = img_start_id + 2 fake_img_token_ids = [24669, 220, 16, 25, 151857, 120, 121] + \ [img_patch_id] * 254 + [img_end_id, 198] img_token_nums = len(fake_img_token_ids) if seq_len < img_token_nums: raise ValueError(f"The number of max_model_len/max_num_seqs is smaller than the img_token_nums({img_token_nums}) of Qwen-VL.") prompt_tokens = fake_img_token_ids + \ [0] * (seq_len - img_token_nums) else: prompt_tokens = [0] * seq_len fake_image_input = None return SequenceData(prompt_tokens), fake_image_input
另外,调用该函数部分的代码更改为:1 2
seq_data, fake_multi_modal_input = _prepare_fake_inputs( seq_len, self.model_config)
- 在vllm_npu/entrypoints/__init__.py中进行generate函数的替换:
1 2 3
from vllm_npu.entrypoints.llm import generate import vllm.entrypoints.llm as vllm_entry_llm vllm_entry_llm.LLM.generate = generate
在vllm_npu/transformers_utils/__init__.py中进行新类的导入:1from .mindie_tokenizer import MindIETokenizer
- 在vllm_npu/__init__.py文件中添加新模块的导入:
1 2 3 4 5
import vllm_npu.transformers_utils import vllm_npu.entrypoints import vllm.sequence as v_sequence v_sequence.MultiModalData = MultiModalData
- 在vllm_npu/sequence.py文件中添加如下新类用于定义Qwen-VL的多模态数据: