使用前必读
当出现硬件故障,且无备用设备时,集群调度组件将对故障节点进行隔离,并根据任务预设的规模和当前集群中可用的节点数,重新设置任务副本数,然后进行重调度和重训练(需进行脚本适配)。
前提条件
- 确保环境中有配置相应的存储方案,比如使用NFS(Network File System),用户可以参见安装NFS进行操作。
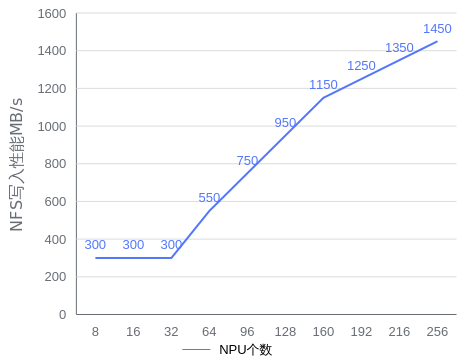
NFS需要用户根据使用情况进行目录隔离,NFS的随机读写性能必须能够在15分钟内保存完整的ckpt文件,建议用户使用专业的存储服务器,NFS具体性能要求给出如下参考。
- 在命令行场景下使用弹性训练特性,需要确保已经安装如下组件。
- Ascend Device Plugin
- Ascend Docker Runtime
- Volcano(弹性训练特性只支持使用Volcano作为调度器,不支持使用其他调度器。)
- Ascend Operator
- NodeD
- Resilience Controller
- ClusterD
- 若没有安装,可以参考安装部署章节进行操作。
使用说明
- 资源监测可以和训练场景下的所有特性一起使用。
- 集群中同时跑多个训练任务,每个任务使用的特性可以不同。
- 集群调度组件管理的训练节点出现故障(安装昇腾AI处理器并启用NodeD的节点网络故障或者芯片故障)后,集群调度组件将对故障节点进行隔离,并根据任务预设的规模和当前集群中可用的节点数重新设置任务副本数,然后进行重调度和重训练(需进行脚本适配)。
- 重调度功能由Kubernetes(简称K8s)配合Volcano或者其他调度器实现。
- 更多说明详见表1。
表1 使用说明 场景
说明
环境要求
需要保证K8s集群中各节点时间一致,避免程序误判。
用于检测NPU芯片间连通性的IP地址推荐配置为路由器的IP地址。
故障处理
使用单机多卡进行训练,当出现故障时,优先按照原任务规格进行恢复,且任务规格遵循8、4、2、1卡的恢复策略。
若Resilience Controller在重新调度任务的过程中,该任务出现新的故障,将不再进行处理。
若在集群资源有限的场景中,当多个任务同时故障触发重调度,可能会出现由于资源不足而导致任务处于Pending状态。
特性说明
本特性不适用于虚拟化实例场景。
本特性目前支持服务器和芯片间数据并行和混合并行的分布式vcjob类型的训练任务。
本特性仅支持设备故障和服务器网络故障检测,说明如下:
支持的产品形态
支持Atlas 800 训练服务器产品使用弹性训练。
父主题: 弹性训练