TensorFlow框架
本章节介绍TensorFlow框架算子适配的流程,用于将TensorFlow框架的算子映射成CANN算子(开发者基于CANN框架自定义开发的算子),从而完成从TensorFlow 框架调用到CANN算子的过程。同时给出TensorFlow框架侧算子调用的示例,便于开发者了解完整流程。
下图展示了完整的开发流程图,关键步骤如下:首先开发者需要参考工程化算子开发和算子入图(GE图)开发完成算子实现和入图开发;然后进行TensorFlow框架适配插件开发,这是本节介绍的重点,用于将TensorFlow框架的算子映射成CANN算子;TensorFlow框架的算子包括TensorFlow自定义算子和原生算子,如果需要从TensorFlow自定义算子映射到CANN算子,还需要完成TensorFlow自定义算子的开发;最后进行TensorFlow框架侧算子调用代码编写。TensorFlow自定义算子和TensorFlow算子调用的相关内容您可以在TensorFlow的官方文档中找到更详细的介绍,本章节仅给出示例供参考。
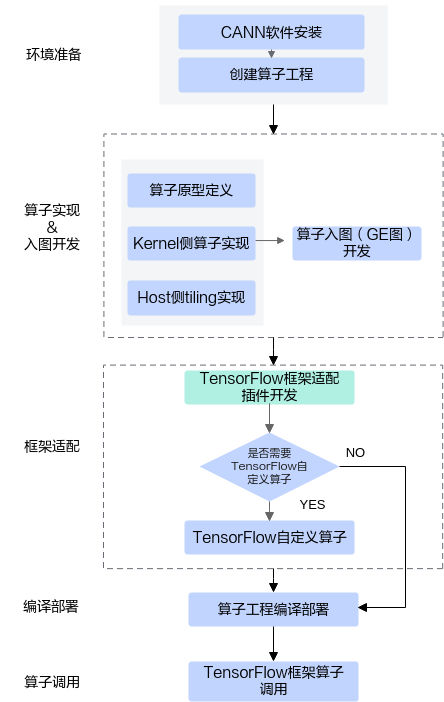
具体步骤如下:
- 环境准备。
- CANN软件安装请参考环境准备。
- 创建算子工程。使用msOpGen工具创建算子开发工程。TensorFlow框架算子适配场景下,需要通过framework参数指定具体的框架为tf或者tensorflow,工具会自动生成框架适配代码。以自定义CANN算子AddCustom为例,使用msOpGen工具创建算子开发工程的具体命令如下:
${INSTALL_DIR}/python/site-packages/bin/msopgen gen -i $HOME/sample/add_custom.json -f tf -c ai_core-<soc_version> -lan cpp -out $HOME/sample/AddCustom
- 算子实现。
- 算子原型定义。通过原型定义来描述算子输入输出、属性等信息以及算子在AI处理器上相关实现信息,并关联tiling实现等函数。
- Kernel侧算子实现和host侧tiling实现请参考算子实现;工程化算子开发,支持开发者调用Tiling API基于CANN提供的编程框架进行tiling开发,kernel侧也提供对应的接口方便开发者获取tiling参数,具体内容请参考Kernel侧算子实现和Host侧tiling实现,由此而带来的额外约束也在上述章节说明。
- 算子入图(GE图)开发。算子入图场景下,需要提供shape推导等算子入图适配函数的实现。
- TensorFlow框架适配插件开发。详细说明见适配插件开发。
- 编译部署。通过工程编译脚本完成算子的编译部署。
- TensorFlow框架算子调用。详细说明见样例(TensorFlow原生算子映射到CANN算子)和样例(TensorFlow自定义算子开发并映射到CANN算子)。本章节的完整样例请参考LINK。
适配插件开发
完成算子工程创建后,会在算子工程目录下生成framework/tf_plugin目录,用于存放TensorFlow框架适配插件实现文件。以自定义CANN算子AddCustom为例,算子工程目录如下:
AddCustom ├── build.sh // 编译入口脚本 ├── cmake ├── CMakeLists.txt // 算子工程的CMakeLists.txt ├── CMakePresets.json // 编译配置项 ├── framework // 框架适配插件实现文件目录 │ ├── tf_plugin // TensorFlow框架适配插件实现文件目录 │ │ ├── CMakeLists.txt │ │ ├── tensorflow_add_custom_plugin.cc // TensorFlow框架适配插件实现文件 │ ├── CMakeLists.txt ├── op_host // host侧实现文件 ├── op_kernel // kernel侧实现文件 └── scripts // 自定义算子工程打包相关脚本所在目录
#include "register/register.h"
namespace domi {
REGISTER_CUSTOM_OP("AddCustom")
.FrameworkType(TENSORFLOW)
.OriginOpType("AddCustom")
.ParseParamsByOperatorFn(AutoMappingByOpFn);
}
- 包含插件实现函数相关的头文件。
register.h存储在CANN软件安装后文件存储路径的“include/register/”目录下,包含该头文件,可使用算子注册相关类,调用算子注册相关的接口。
- REGISTER_CUSTOM_OP:注册自定义算子,传入算子的OpType,需要与算子原型注册中的OpType保持一致。
- FrameworkType:TENSORFLOW代表原始框架为TensorFlow。
- OriginOpType:算子在原始框架中的类型。对于TensorFlow自定义算子,还需要完成TensorFlow自定义算子的开发,这里的OriginOpType与REGISTER_OP注册算子名相同,对于TensorFlow原生算子, 即为原生算子名。
- ParseParamsByOperatorFn:用来注册解析算子参数实现映射关系的回调函数,需要用户自定义实现回调函数ParseParamByOpFunc。原始TensorFlow算子中参数与CANN算子中参数一一对应时,可直接使用自动映射回调函数AutoMappingByOpFn自动实现映射。
样例(TensorFlow原生算子映射到CANN算子)
以自定义算子AddCustom为例,将该算子映射到TensorFlow内置算子Add上,需要先修改AddCustom自定义算子目录framework/tf_plugin下插件代码,完成算子名映射:
1 2 3 4 5 6 7 |
#include "register/register.h" namespace domi { REGISTER_CUSTOM_OP("AddCustom") // 当前Ascend C自定义算子名 .FrameworkType(TENSORFLOW) // 第三方框架类型TENSORFLOW .OriginOpType("Add") // 映射到TensorFlow原生算子Add .ParseParamsByOperatorFn(AutoMappingByOpFn); } |
完成算子工程的编译部署后,构造单算子的TensorFlow 1.15版本测试用例进行验证。
- 编写测试用例“tf_add.py”。
- 导入python库。
1 2 3 4
import logging # Python标准库日志模块 import tensorflow as tf # 导入TensorFlow开源库 from npu_bridge.estimator import npu_ops # 导入TensorFlow开源库中的npu_ops模块 import numpy as np # 导入Python的数学基础库
- 通过config()定义昇腾AI处理器和CPU上的运行参数。
当“execute_type”为“ai_core”时,代表在昇腾AI处理器上运行单算子网络,最终会调用到Ascend C算子。
当“execute_type”为“cpu”时,代表在Host侧的CPU运行单算子网络,调用的是TensorFlow算子。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
def config(execute_type): if execute_type == 'ai_core': session_config = tf.ConfigProto( allow_soft_placement=True, log_device_placement=False,) custom_op = session_config.graph_options.rewrite_options.custom_optimizers.add() custom_op.name = "NpuOptimizer" custom_op.parameter_map["enable_data_pre_proc"].b = True # 开启数据预处理下沉到Device侧执行 custom_op.parameter_map["mix_compile_mode"].b = True custom_op.parameter_map["use_off_line"].b = True # True表示在昇腾AI处理器上执行训练 elif execute_type == 'cpu': session_config = tf.ConfigProto( allow_soft_placement=True, log_device_placement=False) return session_config
- 单算子网络测试用例主函数。
- 算子输入请根据算子实际输入个数及shape进行构造。
- 算子输出的计算,请根据算子逻辑调用TensorFlow相关接口进行实现。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
#np.allclose比较函数的相对公差参数 atol = 0.001 #np.allclose比较函数的绝对公差参数 rtol = 0.001 def main(unused_argv): shape_params = (8, 2048) dtype_params = np.float16 # 构造Add算子的两个输入数据,shape为shape_params,范围在[-2,2]之间的随机数 x_data = np.random.uniform(-2, 2, size=shape_params).astype(dtype_params) y_data = np.random.uniform(-2, 2, size=shape_params).astype(dtype_params) # 分别对Add算子的两个输入数据进行占位 x = tf.compat.v1.placeholder(dtype_params, shape=shape_params) y = tf.compat.v1.placeholder(dtype_params, shape=shape_params) # 计算算子输出 out = tf.math.add(x, y) # 在Host侧CPU上运行单算子,得到期望运行结果 with tf.compat.v1.Session(config=config('cpu')) as session: result_cpu = session.run(out, feed_dict={x: x_data, y: y_data}) # 在昇腾AI处理器上运行单算子,得到实际运行结果 with tf.compat.v1.Session(config=config('ai_core')) as session: result_ai_core = session.run(out, feed_dict={x: x_data, y: y_data}) np.array(result_ai_core).astype(dtype_params) np.array(result_cpu).astype(dtype_params) print('====================================') # 通过np.allclose比较昇腾AI处理器上运行的实际结果和cpu上运行的期望结果,其中atol和rtol为np.allclose比较函数的相对公差参数和绝对公差参数。 cmp_result = np.allclose(result_ai_core, result_cpu, atol, rtol) print(cmp_result) print('====================================')
- 运行单算子网络。
1 2
if __name__ == "__main__": tf.app.run()
样例(TensorFlow自定义算子开发并映射到CANN算子)
- 适配插件代码开发。以自定义算子AddCustom为例,将该算子映射到TensorFlow自定义算子AddCustom上,需要先修改CANN AddCustom自定义算子工程目录framework/tf_plugin下插件代码,完成算子名映射:
REGISTER_CUSTOM_OP("AddCustom") .FrameworkType(TENSORFLOW) .OriginOpType("AddCustom") .ParseParamsByOperatorFn(AutoMappingByOpFn); - TensorFlow自定义算子的开发。本节仅给出示例说明,详细内容请参考TensorFlow官方文档。创建TensorFlow原型注册文件custom_assign_add_custom.cc,内容如下:
#include "tensorflow/core/framework/op.h" #include "tensorflow/core/framework/shape_inference.h" #include "tensorflow/core/framework/op_kernel.h" #include "tensorflow/core/framework/common_shape_fns.h" using namespace tensorflow; // 通过TensorFlow提供的REGISTER_OP接口完成算子原型的注册 REGISTER_OP("AddCustom") // TensorFlow 注册算子名 .Input("x: T") // 算子原型,输入参数x,类型为T .Input("y: T") // 算子原型,输入参数y,类型为T .Output("z: T") // 算子原型,输入参数z,类型为T .Attr("T: {half}") // T类型支持范围 .SetShapeFn(shape_inference::BroadcastBinaryOpShapeFn); // 算子shape信息推导,BroadcastBinaryOpShapeFn为TensorFlow提供的内置函数,输出shape信息由输入shape传播推导,即输入和输出shape保持一致 // 实现一个CPU版本的kernel函数,因为Tensorflow的计算图在构建时会检查所有的算子是否有任意设备上的kernel函数(NPU Kernel无法被感知),如果没有将会报错。这里实现一个固定返回错误的CPU kernel函数: class AddCustomOp : public OpKernel { public: explicit AddCustomOp(OpKernelConstruction* context) : OpKernel(context) {} void Compute(OpKernelContext* context) override { OP_REQUIRES_OK(context, errors::Unimplemented("AddCustomOp is not supported on CPU")); } }; REGISTER_KERNEL_BUILDER(Name("AddCustom").Device(DEVICE_CPU), AddCustomOp); // 注册AddCustom算子的CPU实现内核,该函数当前仅打印日志提示CPU不支持使用如下命令对上述代码进行编译,产物为libcustom_ops.so,后续的算子调用脚本中可通过load_op_library接口加载该so为python模块,从而调用自定义算子。TF_CFLAGS=( $(python3 -c 'import tensorflow as tf; print(" ".join(tf.sysconfig.get_compile_flags()))') ) // 获取TensorFlow编译选项 TF_LFLAGS=( $(python3 -c 'import tensorflow as tf; print(" ".join(tf.sysconfig.get_link_flags()))') ) // 获取TensorFlow链接选项 SOURCE_FILES=custom_assign_add_custom.cc // 包含TensorFlow算子注册和CPU内核实现的cc文件 g++ -std=c++14 -shared $SOURCE_FILES -o ${Path}/libcustom_ops.so -fPIC ${TF_CFLAGS[@]} ${TF_LFLAGS[@]} -O2 // 编译命令,产物为libcustom_ops.so,TensorFlow即可通过load_op_library加载该so为python模块,调用自定义算子 - 测试脚本中加载上一步骤编译好的动态库,实现自定义算子的调用。
- TensorFlow 1.15.0调用代码示例
import os import tensorflow as tf import numpy as np from npu_bridge.npu_init import * tf.enable_resource_variables() #np.allclose比较函数的相对公差参数 atol = 0.001 #np.allclose比较函数的绝对公差参数 rtol = 0.001 def main(unused_argv): custom_op_lib = tf.load_op_library('./outputs/libcustom_ops.so') # 加载so为python模块 shape_params = (8, 2048) dtype_params = np.float16 x_data = np.random.uniform(-2, 2, size=shape_params).astype(dtype_params) y_data = np.random.uniform(-2, 2, size=shape_params).astype(dtype_params) x = tf.compat.v1.placeholder(dtype_params, shape=shape_params) y = tf.compat.v1.placeholder(dtype_params, shape=shape_params) tf_z = tf.math.add(x, y) # 调用TensorFlow原生算子 ac_z = custom_op_lib.add_custom(x, y) # 调用AscendC AddCustom自定义算子 config = tf.ConfigProto() custom_op = config.graph_options.rewrite_options.custom_optimizers.add() custom_op.name = "NpuOptimizer" # 配置在昇腾AI处理器上运行单算子 config.graph_options.rewrite_options.remapping = RewriterConfig.OFF config.graph_options.rewrite_options.memory_optimization = RewriterConfig.OFF with tf.Session(config=config) as sess: sess.run(tf.global_variables_initializer()) tf_golden = sess.run(tf_z, feed_dict={x: x_data, y: y_data}) with tf.Session(config=config) as sess: sess.run(tf.global_variables_initializer()) ascend_out = sess.run(ac_z, feed_dict={x: x_data, y: y_data}) np.array(tf_golden).astype(dtype_params) np.array(ascend_out).astype(dtype_params) print('====================================') # 通过np.allclose比较昇腾AI处理器上运行的实际结果和使用TensorFlow原生算子运行的期望结果,其中atol和rtol为np.allclose比较函数的相对公差参数和绝对公差参数。 cmp_result = np.allclose(tf_golden, ascend_out, atol, rtol) print(cmp_result) print('====================================') if __name__ == "__main__": tf.app.run() - TensorFlow 2.6.5调用代码
import os import tensorflow as tf import numpy as np import npu_device from npu_device.compat.v1.npu_init import * npu_device.compat.enable_v1() tf.compat.v1.enable_resource_variables() #np.allclose比较函数的相对公差参数 atol = 0.001 #np.allclose比较函数的绝对公差参数 rtol = 0.001 def main(unused_argv): custom_op_lib = tf.load_op_library('./outputs/libcustom_ops.so') # 加载so为python模块 shape_params = (8, 2048) dtype_params = np.float16 x_data = np.random.uniform(-2, 2, size=shape_params).astype(dtype_params) y_data = np.random.uniform(-2, 2, size=shape_params).astype(dtype_params) x = tf.compat.v1.placeholder(dtype_params, shape=shape_params) y = tf.compat.v1.placeholder(dtype_params, shape=shape_params) tf_z = tf.math.add(x, y) # 调用TensorFlow原生算子 ac_z = custom_op_lib.add_custom(x, y) # 调用AscendC AddCustom自定义算子 config = tf.compat.v1.ConfigProto() custom_op = config.graph_options.rewrite_options.custom_optimizers.add() custom_op.name = "NpuOptimizer" config.graph_options.rewrite_options.remapping = RewriterConfig.OFF config.graph_options.rewrite_options.memory_optimization = RewriterConfig.OFF with tf.compat.v1.Session(config=config) as sess: sess.run(tf.global_variables_initializer()) tf_golden = sess.run(tf_z, feed_dict={x: x_data, y: y_data}) with tf.compat.v1.Session(config=config) as sess: sess.run(tf.global_variables_initializer()) ascend_out = sess.run(ac_z, feed_dict={x: x_data, y: y_data}) np.array(tf_golden).astype(dtype_params) np.array(ascend_out).astype(dtype_params) print('====================================') # 通过np.allclose比较昇腾AI处理器上运行的实际结果和使用TensorFlow原生算子运行的期望结果,其中atol和rtol为np.allclose比较函数的相对公差参数和绝对公差参数。 cmp_result = np.allclose(tf_golden, ascend_out, atol, rtol) print(cmp_result) print('====================================') if __name__ == "__main__": tf.app.run()
- TensorFlow 1.15.0调用代码示例