aclnnFlashAttentionScoreGrad
Atlas 训练系列产品不支持该算子。
Atlas A2 训练系列产品支持该算子。
接口原型
每个算子分为两段式接口,必须先调用“aclnnFlashAttentionScoreGradGetWorkspaceSize”接口获取入参并根据计算流程计算所需workspace大小,再调用“aclnnFlashAttentionScoreGrad”接口执行计算。
- aclnnStatus aclnnFlashAttentionScoreGradGetWorkspaceSize(const aclTensor *query, const aclTensor *key, const aclTensor *value, const aclTensor *dy, const aclTensor *pseShift, const aclTensor *dropMask, const aclTensor *paddingMask, const aclTensor *attenMask, const aclTensor *softmaxMax, const aclTensor *softmaxSum, const aclTensor *softmaxIn, const aclTensor *attentionIn, const aclTensor *prefix, const aclTensor *dq, const aclTensor *dk, const aclTensor *dv, const aclTensor *dpse, double scaleValue, double keepProb, int64_t preTockens, int64_t nextTockens, int64_t headNum, string *inputLayout, int32_t innerPrecise, int64_t sparseMode, uint64_t *workspaceSize, aclOpExecutor **executor)
- aclnnStatus aclnnFlashAttentionScoreGrad(void *workspace, uint64_t workspaceSize, aclOpExecutor *executor, aclrtStream stream)
功能描述
- 算子功能:训练场景下计算注意力的反向输出,即aclnnFlashAttentionScore的反向计算。
- 计算公式:
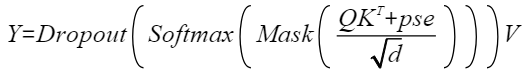
为方便表达,以变量S和P表示计算公式:
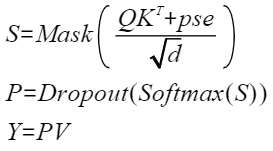
则注意力的反向计算公式为:
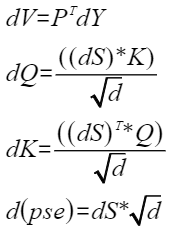
aclnnFlashAttentionGradGetWorkspaceSize
- 参数说明:
- query(aclTensor*,计算输入):Device侧的aclTensor,公式中的输入Q,数据类型支持FLOAT16、BFLOAT16,数据格式支持ND。
- key(aclTensor*,计算输入):Device侧的aclTensor,公式中的输入K,数据类型支持FLOAT16、BFLOAT16,数据格式支持ND。
- value(aclTensor*,计算输入):Device侧的aclTensor,公式中的输入V,数据类型支持FLOAT16、BFLOAT16,数据格式支持ND。
- dy(aclTensor*,计算输入):Device侧的aclTensor,公式中的输入dY,数据类型支持、FLOAT16、BFLOAT16,数据格式支持ND。
- pseShift(aclTensor*,计算输入):Device侧的aclTensor,公式中的输入pse,可选参数,表示位置编码。数据类型支持FLOAT16、BFLOAT16,数据格式支持ND,alibi位置编码场景下,每个batch参数不同[B N S S], 每个batch参数相同[B 1 S S]
- dropMask(aclTensor*,计算输入):Device侧的aclTensor,可选属性,数据类型支持UINT8(标识8个1bit BOOL),数据格式支持ND。
- paddingMask(aclTensor*,计算输入):Device侧的aclTensor,暂不支持该传参。。
- attenMask(aclTensor*,计算输入):Device侧的aclTensor,可选属性,代表下三角全为0上三角全为负无穷的倒三角mask矩阵,数据类型支持BOOL、UINT8,数据格式支持ND。
- softmaxMax(aclTensor*,计算输入):Device侧的aclTensor,注意力正向计算的中间输出,数据类型支持FLOAT,数据格式支持ND。
- softmaxSum(aclTensor*,计算输入):Device侧的aclTensor,注意力正向计算的中间输出,数据类型支持FLOAT,数据格式支持ND。
- softmaxIn(aclTensor*,计算输入):Device侧的aclTensor,注意力正向计算的中间输出,数据类型支持FLOAT16,数据格式支持ND。
- attentionIn(aclTensor*,计算输入):Device侧的aclTensor,注意力正向计算的最终输出attentionOut,数据类型支持FLOAT16、BFLOAT16,数据格式支持ND。
- prefix(aclTensor*,计算输入):Device侧的aclTensor,可选属性,代表prefix稀疏计算场景每个Batch的N值。数据类型支持INT64,数据格式支持ND。
- dq(aclTensor*,计算输出):Device侧的aclTensor,公式中的dQ,表示query的梯度,计算输出,数据类型支持FLOAT16、BFLOAT16,数据格式支持ND。
- dk(aclTensor*,计算输出):Device侧的aclTensor,公式中的dK,表示key的梯度,计算输出,数据类型支持FLOAT16、BFLOAT16,数据格式支持ND。
- dv(aclTensor*,计算输出):Device侧的aclTensor,公式中的dV,表示value的梯度,计算输出,数据类型支持FLOAT16、BFLOAT16,数据格式支持ND。
- dpse(aclTensor*,计算输出):Device侧的aclTensor,公式中的d(pse),表示pse的梯度,计算输出,数据类型支持FLOAT16、BFLOAT16,数据格式支持ND。
- scaleValue(double,计算输入):Host侧的double,公式中d开根号的倒数,代表缩放系数,作为计算流中Muls的scalar值,数据类型支持DOUBLE。
- keepProb(double,计算输入):Host侧的double,可选参数,代表dropMask中1的比例,数据类型支持FLOAT32。
- preTokens(int64_t,计算输入):Host侧的int64_t,用于稀疏计算的参数,可选参数,数据类型支持INT64。
- nextTokens(int64_t,计算输入):Host侧的int64_t,用于稀疏计算的参数,可选参数,数据类型支持INT64。
- headNum(int64_t,计算输入):Host侧的int64_t,代表head个数,数据类型支持INT64。
- inputLayout(string*,计算输入):Host侧的string,代表输入query、key、value的数据排布格式,支持BSH、SBH、BSND、BNSD。

query、key、value数据排布格式支持从多种维度解读,其中B(Batch)表示输入样本批量大小、S(Seq-Length)表示输入样本序列长度、H(Head-Size)表示隐藏层的大小、N(Head-Num)表示多头数、D(Head-Dim)表示隐藏层最小的单元尺寸,且满足D=H/N。
- innerPrecise(int32_t,计算输入):保留参数,暂未使用。
- sparseMode(int64_t,计算输入):Host侧的int,表示sparse的模式。数据类型支持:INT64。
- sparseMode为0时,代表defaultMask模式,如果attenmask未传入则不做mask操作,忽略preTokens和nextTokens(内部赋值为INT_MAX);如果传入,则需要传入完整的attenmask矩阵(S1 * S2),表示preTokens和nextTokens之间的部分需要计算。
- sparseMode为为1时,代表allMask,即传入完整的attenmask矩阵。。
- sparseMode为2时,代表leftUpCausal模式的mask,对应以左顶点为划分的下三角场景,需要传入优化后的attenmask矩阵(2048*2048)。
- sparseMode为3时,代表rightDownCausal模式的mask,对应以右下顶点为划分的下三角场景,需要传入优化后的attenmask矩阵(2048*2048)。
- sparseMode为为4时,代表band场景,即计算preTokens和nextTokens之间的部分。
- sparseMode为为5时,代表prefix场景,即在rightDownCasual的基础上,左侧加上一个长为S1,宽为N的矩阵,N的值由新增的输入prefix获取,且每个Batch轴的N值不一样。
- sparseMode为为6、7、8时,分别代表global、dilated、block_local,均暂不支持。
用户不特意指定时可传入默认值0。注意:当所有的attenmask的shape小于2048且相同的时候,建议使用default模式,来减少内存使用量;sparse_mode配置为2或3时,不能配置preTokens、nextTokens。
- workspaceSize(uint64_t*,出参):返回用户需要在Device侧申请的workspace大小。
- executor(aclOpExecutor**,出参):返回op执行器,包含了算子计算流程。
- 返回值:
返回aclnnStatus状态码,具体参见aclnn返回码。
第一段接口完成入参校验,若出现以下错误码,则对应原因为:
- 返回161001(ACLNN_ERR_PARAM_NULLPTR):如果传入参数是必选输入、输出或者必选属性,且是空指针,则返回161001。
- 返回161002(ACLNN_ERR_PARAM_INVALID):query、key、value、dy、pseShift、dropMask、paddingMask、attenMask、softmaxMax、softmaxSum、softmaxIn、attentionIn、dq、dk、dv的数据类型和数据格式不在支持的范围内。
aclnnFlashAttentionScoreGrad
- 参数说明:
- workspace(void*,入参):在Device侧申请的workspace内存起址。
- workspaceSize(uint64_t,入参):在Device侧申请的workspace大小,由aclnnFlashAttentionGradGetWorkspaceSize获取。
- executor(aclOpExecutor*,入参):op执行器,包含了算子计算流程。
- stream(aclrtStream,入参):指定执行任务的AscendCL stream流。
- 返回值:
返回aclnnStatus状态码,具体参见aclnn返回码。
约束与限制
关于数据shape的约束,以inputLayout的BSND、BNSD为例(BSH、SBH下H=N*D),其中
- B:取值范围为1~256。
- N:取值范围为1~256。
- S:取值范围为1~32K,且为16的倍数。
- D:取值为64、96、128、256。
父主题: 融合类算子接口