吞吐率指标
神经网络的吞吐量(Throughput)定义为网络模型在单位时间(例如1s)内可以处理的最大输入的训练样本数据。
与涉及单个样本数据处理的延迟Latency不同,为了实现最大吞吐量Throughput,希望在集群训练的过程中并行处理尽可能多的样本数据。有效的并行性显然依赖于数据、模型和设备规模。
因此,为了正确测量吞吐量,可以执行以下两个步骤:
- 估计允许最大并行度的最佳训练样本数据批量大小,即Batch Size;
- 在AI训练集群中给定这个最佳批量大小,测量网络在1秒钟内可以处理的训练样本数据。
要找到最佳批量大小,一个好的经验法则是达到Ascend昇腾处理器对给定数据类型的内存限制,即Batch Size塞满内存。这个大小当然取决于硬件类型、网络的大小以及输入数据的大小。
要找到这个最大批量大小的Batch Size,最快方法是执行二分搜索。当时间不重要时,简单的顺序搜索就足够了。不过在大模型训练的过程中,因为Batch Size比较重要,涉及到重计算、Pipeline并行、Tensor并行等不同并行模式的配比,还有包括micro Batch Size的数据配比。因此默认Batch Size为16的倍数比较合理。
这确定了AI加速卡上可以处理的最大批量大小,用于训练大模型及其处理的输入训练样本数据。在找到最佳批量大小后,可以计算实际吞吐量,然后使用以下公式:
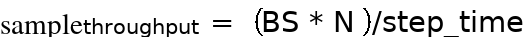
其中,BS为Batch Size per DP(每个数据并行维度的batch size大小),N为集群中数据并行维度的大小,step_time为在分布式集群中,执行完一个total Batch Size的时间(单位为s)。大模型训练的吞吐率的单位在CV和部分NLP任务中为Samples/s,在固定Shape的NLP任务有seq_len,因此单位为tokens/s,计算公式为:
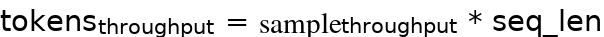
假设GLM10B网络模型的吞吐为25 Samples/s,max seq_len为1024,那么按照tokens来计算吞吐率为 25 * 1024 = 25600 tokens/s。也就是每秒能处理2万多个tokens。