算子调用
图1 算子调用流程
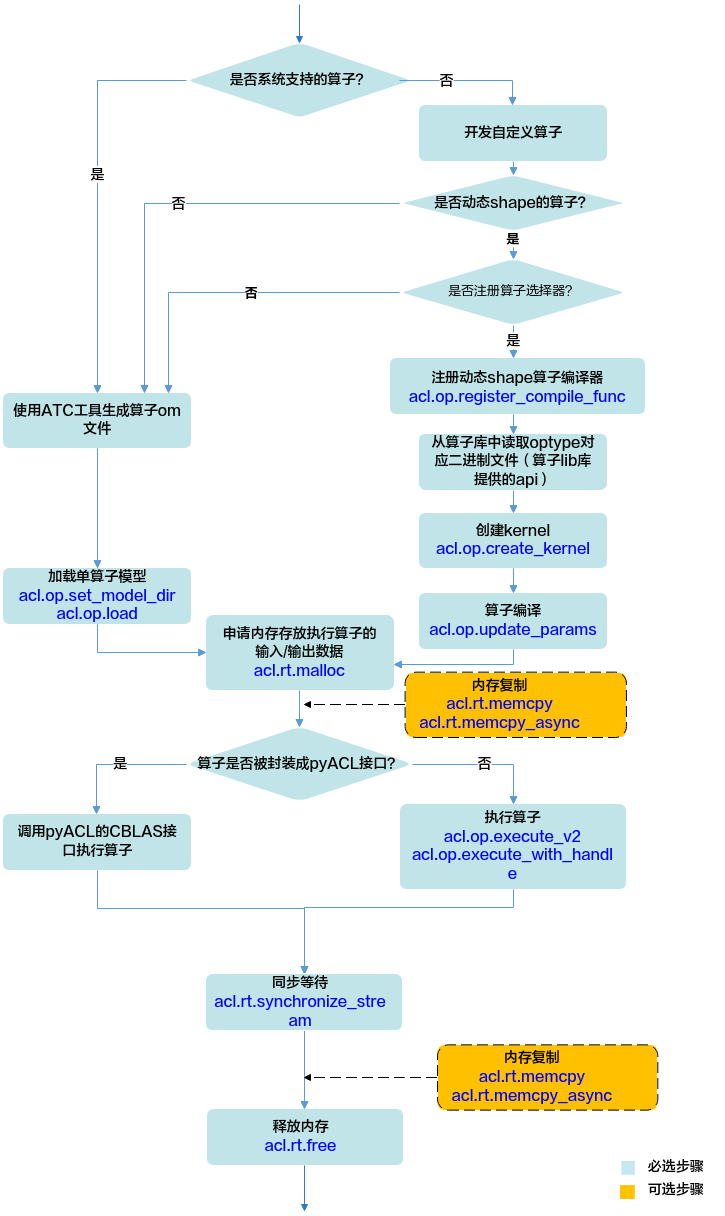
关键接口的说明如下(调用示例请参见单算子调用,系统支持的算子请参见《算子清单》):
- 加载/编译算子。
- 对于固定Shape的算子,调用pyACL接口加载算子:
- 单算子模型文件,需要用户提前参见《ATC工具使用指南》将单算子定义文件(*.json)编译成适配昇腾AI处理器的离线模型(*.om文件)。
- 加载单算子模型文件,有两种方式:
调用函数:set_model_dir接口,设置加载模型文件的目录,目录下存放单算子模型文件(*.om文件)。
调用函数:load接口,从内存中加载单算子模型数据,由用户管理内存。单算子模型数据是指“单算子编译成*.om文件后,再将om文件读取到内存中”的数据。
- 对于动态Shape的算子,需提前注册要编译的自定义算子:
- 调用函数:unregister_compile_func接口注册算子选择器(即选择Tiling策略的函数),用于在算子执行时,能针对不同Shape,选择相应的Tiling策略。
算子选择器需由用户提前定义并实现,算子选择器的实现样例请参见《ATC工具使用指南》中的“专题 > TIK自定义算子动态Shape专题”:
- 函数原型:
def call_back_func(num_inputs, input_desc, num_outputs, output_desc, op_attr, aclop_kernel_desc): pass
- 函数实现:
用户自行编写代码逻辑实现Tiling策略选择、Tiling参数生成,并将调用函数:set_kernel_args接口,设置算子Tiling参数、执行并发数等。
- 函数原型:
- 调用函数:create_kernel接口将算子注册到系统内部,用于在算子执行时,查找到算子实现代码。
- 调用函数:update_params接口编译指定算子,触发算子选择器的调用逻辑。
- 调用函数:unregister_compile_func接口注册算子选择器(即选择Tiling策略的函数),用于在算子执行时,能针对不同Shape,选择相应的Tiling策略。
- 对于固定Shape的算子,调用pyACL接口加载算子:
- 调用函数:malloc接口申请Device上的内存,存放执行算子的输入、输出数据。
如果需要将Host上数据传输到Device,则需要调用函数:memcpy接口(同步接口)或函数:memcpy_async接口(异步接口)通过内存复制的方式实现数据传输。
- 执行算子。
- 如果是系统内置的算子GEMM,该算子已经被封装成pyACL接口,用户可直接调用CBLAS接口(blas)执行该算子。
- 如果是系统内置的算子,但未被封装成pyACL接口,当前支持以下两种方式执行算子:
- 您需自行构造算子描述信息(输入输出Tensor描述、算子属性等)、申请存放算子输入输出数据的内存、调用函数:execute_v2接口加载并执行算子。
该方式下,每次调用函数:execute_v2接口执行算子,系统内部都会根据算子描述信息匹配内存中的模型。
- 您需自行构造算子描述信息(输入输出Tensor描述、算子属性等)、申请存放算子输入输出数据的内存、调用函数:create_handle接口创建一个Handle、再调用函数:execute_with_handle接口加载并执行算子。
该方式下,在调用函数:create_handle接口时,系统内部将算子描述信息匹配到内存中的模型,并缓存在Handle中,每次调用函数:execute_with_handle接口执行算子时,无需重复匹配算子与模型,因此在涉及多次执行同一个算子时,效率更高。Handle使用结束后,需调用函数:destroy_handle接口释放。
- 您需自行构造算子描述信息(输入输出Tensor描述、算子属性等)、申请存放算子输入输出数据的内存、调用函数:execute_v2接口加载并执行算子。
- 如果不是系统内置的算子,则需要用户先进行算子开发,请参见《TBE自定义算子开发指南》,再调用未被封装成pyACL接口的算子中提供的方式执行算子。
- 调用函数:synchronize_stream接口阻塞应用运行,直到指定Stream中的所有任务都完成。
- 调用函数:free接口释放内存。
如果需要将Device上的算子执行结果数据传输到Host,则需要调用函数:memcpy接口(同步接口)或函数:memcpy_async接口(异步接口)通过内存复制的方式实现数据传输,然后再释放内存。
父主题: 接口调用流程