网络应用中的函数计算性能优化分析样例
背景介绍
使用PyTorch网络应用在昇腾AI处理器执行推理过程中,发现整体执行时间较长。为了找出原因,使用Profiling性能分析工具对该网络应用执行推理耗时分析,分析结果显示运行的接口aclmdlExecute执行耗时数值较高,进一步分析结果发现Conv算子执行时间最长。因此我们打开PyTorch网络转换成的om模型查询Conv算子,发现该算子是多个计算单元组成,这样会造成极大的推理开销。由于Conv算子所在函数为Mish激活函数,而当前昇腾AI处理器支持的激活函数只有:Relu、Leakyrelu、Prelu、Elu、Srelu,Mish函数暂时不在支持范围内,因此造成模型转换后的Mish函数被分解成了多个计算单元。
问题解决:我们通过将om模型中的Mish函数替换昇腾AI处理器的激活函数,尝试降低推理耗时,以Leakyrelu替换Mish函数为例,重新执行Profiling性能分析,结果发现推理耗时明显降低。
Profiling性能分析思路
Profiling数据采集的目的是通过数据分析出执行推理或训练过程中软件硬件的性能瓶颈,可以根据图1来对数据进行分析。
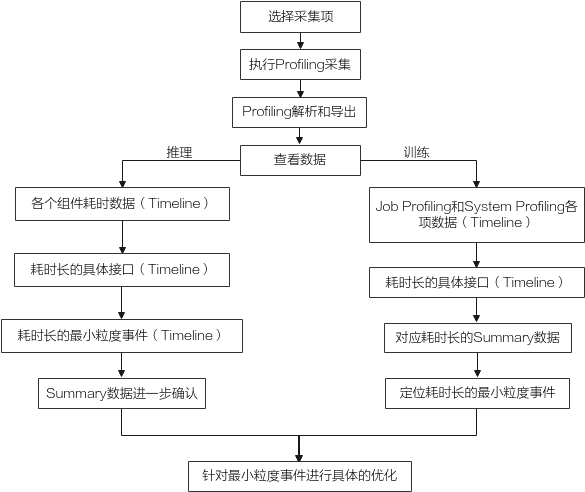
- 根据执行推理或训练场景选择Profiling采集的方式以及采集项。
- 执行Profiling采集、解析并导出Timeline和Summary数据。
- 查看数据:
- 推理:先查看各个组件耗时数据,观察并找出耗时多的接口,找到耗时长的接口详细Timeline文件并进一步分析接口内耗时长的内容,直到定位出最小粒度的事件,找到对应的Summary文件进一步确认,最后针对该事件进行具体的优化。
- 训练:分别查看Job Profiling和System Profiling各项数据的Timeline文件,找出对应耗时较长的项并找出对应是Summary文件,在Summary文件中定位到耗时长的最小粒度事件,针对该事件进行具体的优化。
Profiling性能分析操作
通过以下操作方法执行Profiling:
- 采集Profiling数据。
执行Profiling命令,采集当前已编译完成的应用软件模块性能数据。
./msprof --output=/home/HwHiAiUser/result --application=/home/HwHiAiUser/AscendProjects/MyApp1/out/main --ascendcl
此处以通过msprof命令行方式采集Profiling数据为例,更多采集方式请参见本文的“采集Profiling数据”。
执行完上述命令后,会在--output目录下生成PROFXXX目录,PROFXXX目录即为保存的原始Profiling数据。
- 解析Profiling数据。
- 以Ascend-cann-toolkit开发套件包的运行用户登录开发环境。以HwHiAiUser用户为例。
- 切换至msprof.py脚本所在目录,如/home/HwHiAiUser/Ascend/ascend-toolkit/latest/toolkit/tools/profiler/profiler_tool/analysis/msprof。

小技巧:为方便执行msprof.py脚本,您可以使用HwHiAiUser用户执行命令alias msprofanlysis='python3 /home/HwHiAiUser/Ascend/ascend-toolkit/latest/toolkit/tools/profiler/profiler_tool/analysis/msprof/msprof.py'设置别名,后续就可以不用进入/home/HwHiAiUser/Ascend/ascend-toolkit/latest/toolkit/tools/profiler/profiler_tool/analysis/msprof目录,在任意目录输入msprof即可执行profiling命令。
- 执行如下命令,解析PROFXXX目录下的profiling数据。
python3 msprof.py import -dir /home/HwHiAiUser/profiler_data
此处以通过import命令行方式解析profiling数据为例,解析profiling数据详细介绍请参见解析Profiling数据(msprof.py工具方式)。
- 在msprof.py脚本所在目录继续执行如下命令,导出timeline数据。
python3 msprof.py export timeline -dir home/HwHiAiUser/profiler_data
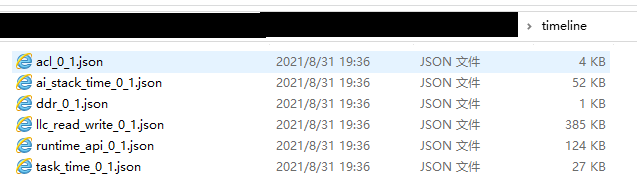
执行完上述命令后,会在collection-dir目录下的PROFXXX目录下生成timeline目录,不同的数据生成对应的json文件,如图2所示。每个文件具体含义请参见表2。
- 在msprof.py脚本所在目录继续执行如下命令,导出summary数据。
python3 msprof.py export summary -dir /home/HwHiAiUser/profiler_data --format csv
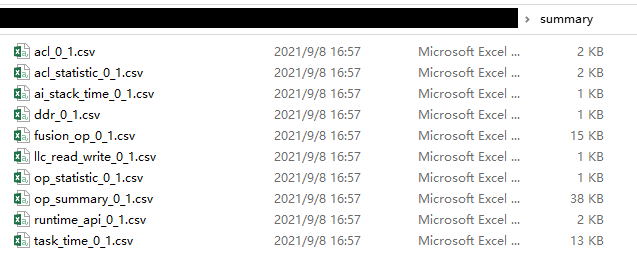
执行完上述命令后,会在collection-dir目录下的PROFXXX目录下生成summary目录,不同的数据(推理,系统)生成对应的csv文件,如图3所示。每个文件具体含义请参见表3。
问题分析
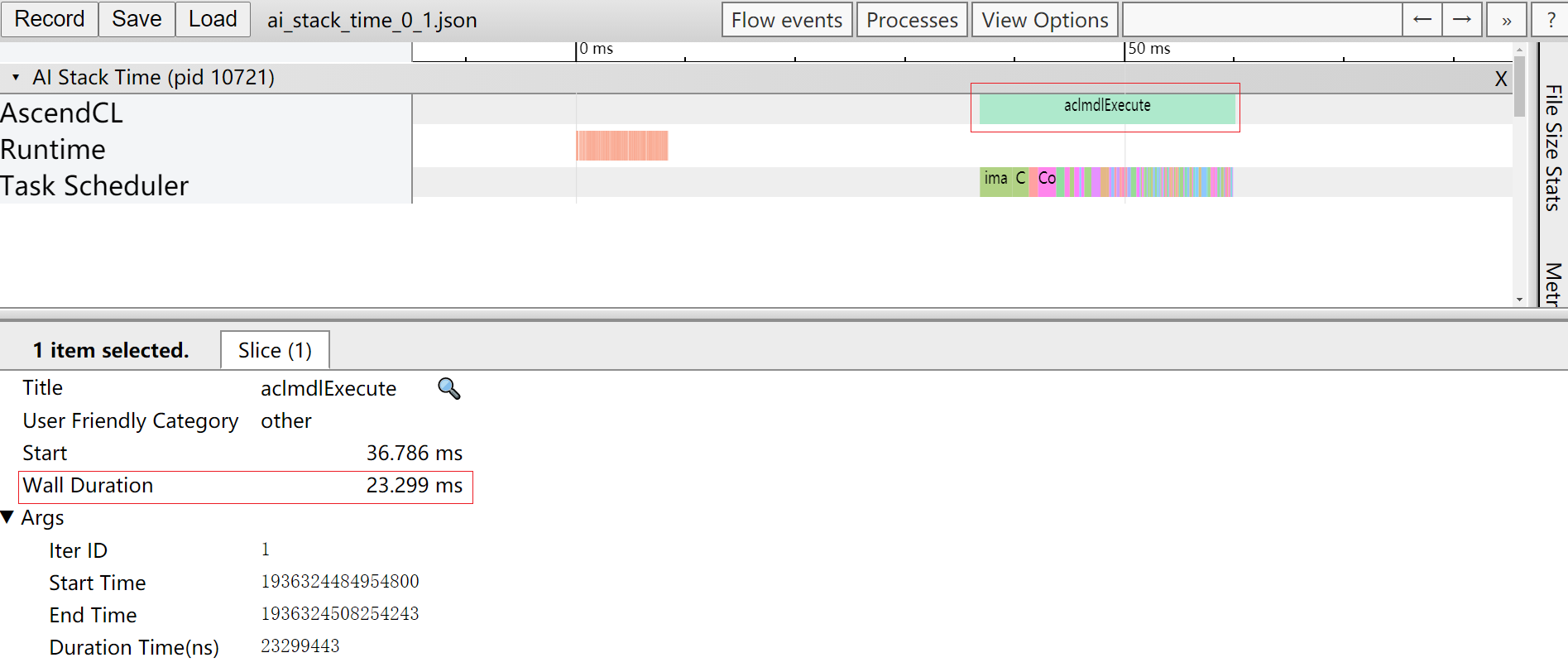
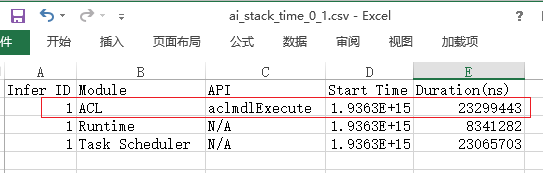
- 我们首先打开timeline数据的ai_stack_time_{device_id}_{model_id}_{iter_id}.json查看各个组件的耗时数据。在Chrome浏览器中输入“chrome://tracing”地址,将各个组件的耗时数据ai_stack_time_{device_id}_{model_id}_{iter_id}.json拖到空白处进行打开,通过键盘上的快捷键(w:放大 s:缩小 a:左移 d:右移),查看每次迭代的耗时情况。如图4所示。
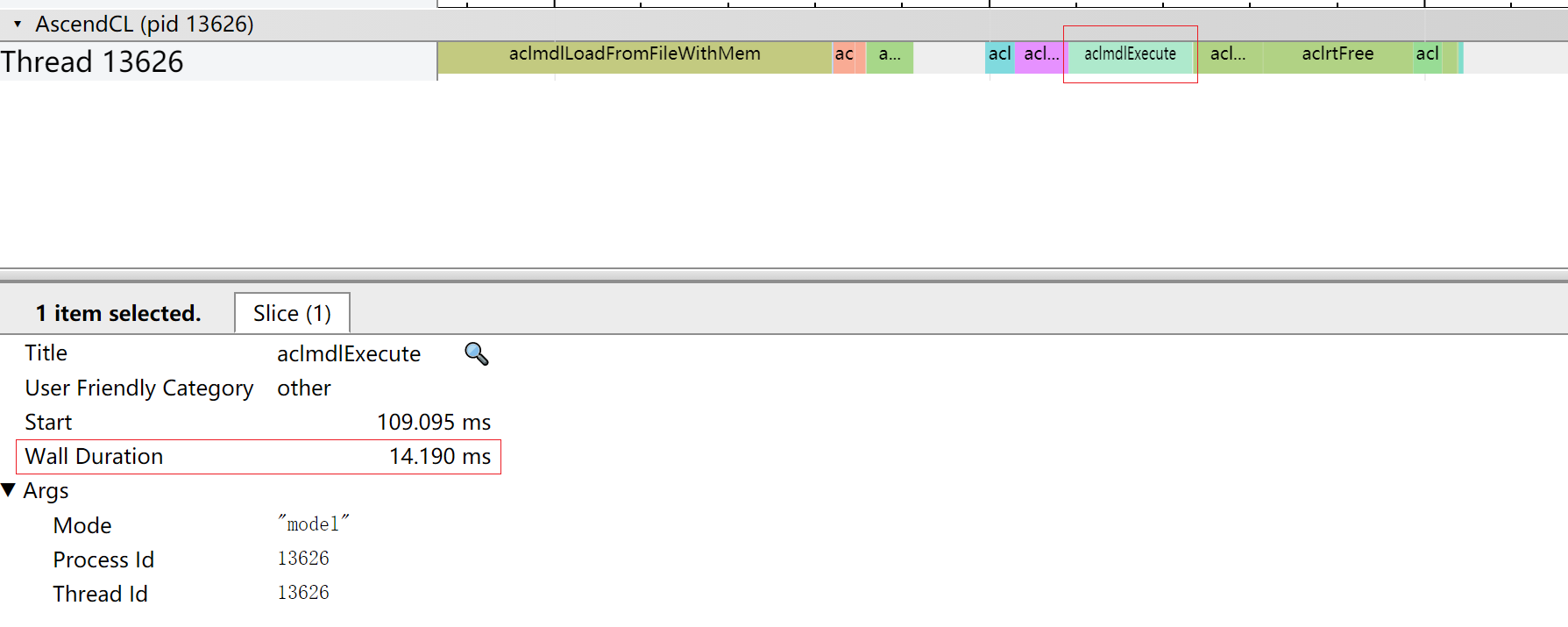
此时我们可以直观的看到接口调用耗时最长的时间线为AscendCL接口的aclmdlExcute接口。
参见《应用软件开发指南 (C&C++)》中的“AscendCL API参考”章节查找aclmdlExcute接口的作用为“执行应用推理,直到返回推理结果,同步接口”。我们可以发现该接口是执行接口,也就是说应用在推理的过程中存在执行耗时较长的接口。
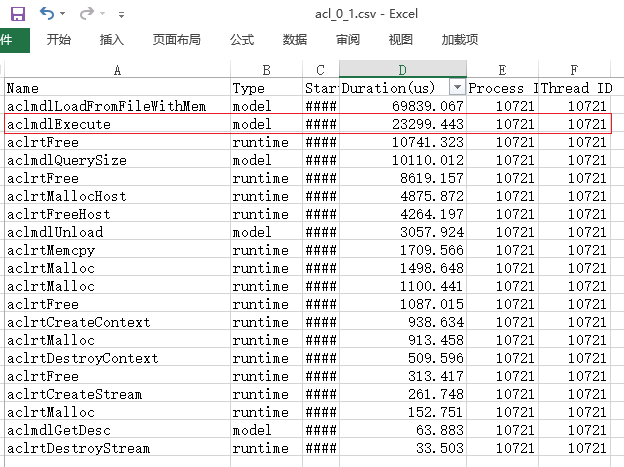
- 我们接着打开acl_{device_id}_{model_id}_{iter_id}.json文件查看AscendCL接口耗时数据。如图5所示。
此时我们可以看到AscendCL接口中耗时最长的时间线有两段,分别为aclmdlLoadFromFileWithMem和aclmdlExcute接口。也就是说虽然aclmdlExcute接口是在执行接口中耗时最长,但是在AscendCL接口中,aclmdlExcute接口耗时仅排第二。
参见《应用软件开发指南 (C&C++)》中的“AscendCL API参考”章节查找aclmdlLoadFromFileWithMem接口的作用为“从文件加载离线模型数据”,可以分析该接口耗时取决于加载离线模型的时间,加载时间我们暂时无法进行调优。那么还需要继续从aclmdlExcute接口深入分析。
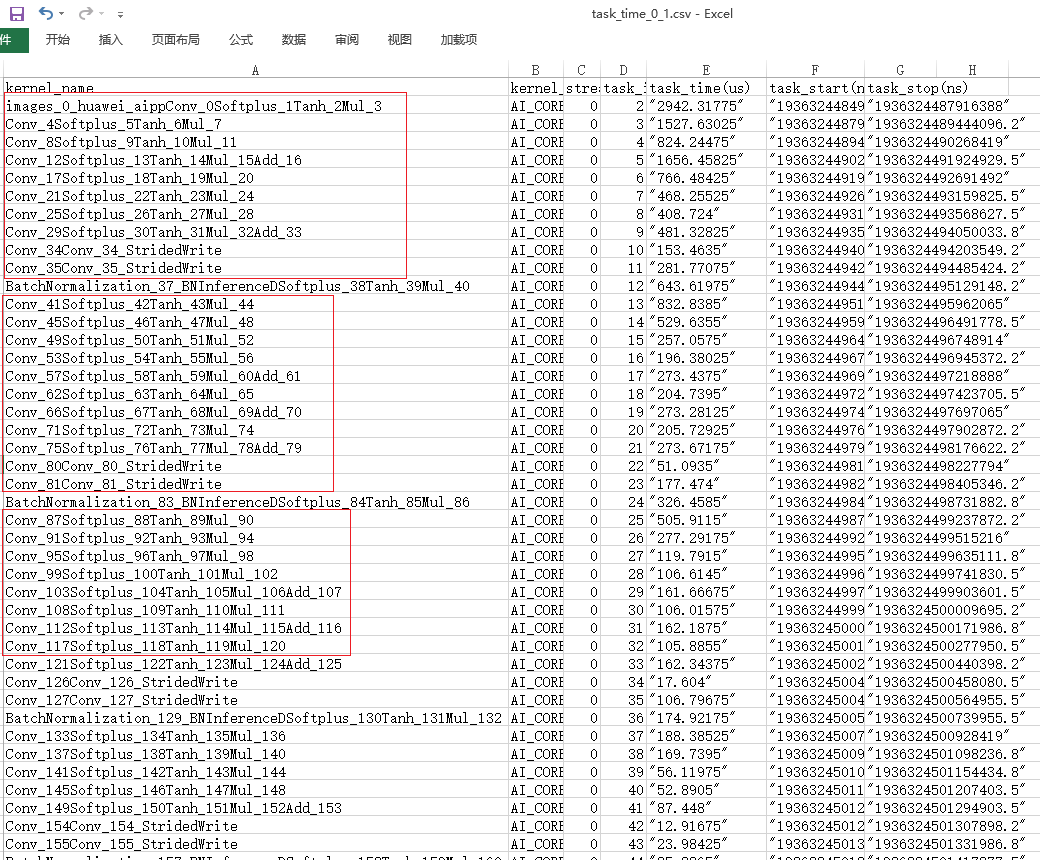
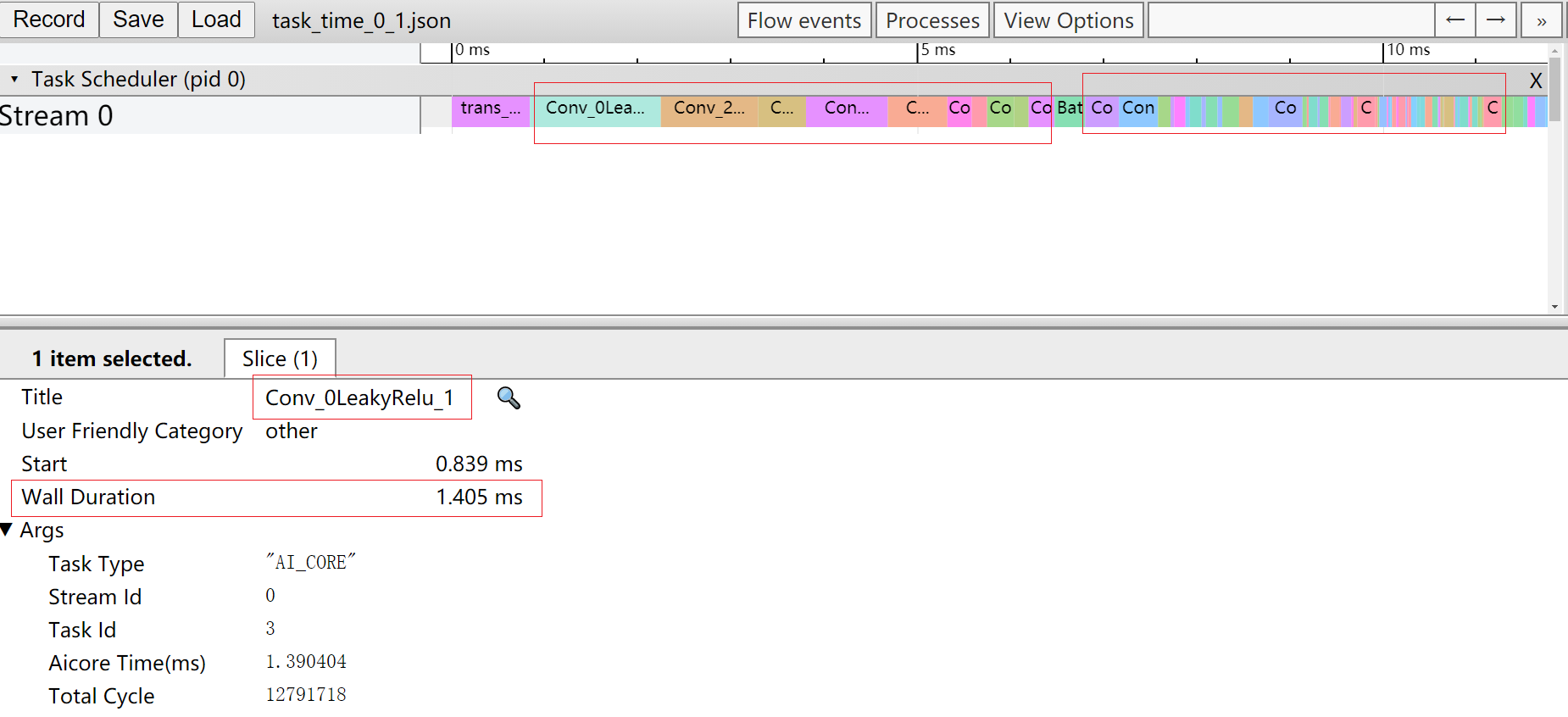
- 由于aclmdlExcute接口是执行接口,而模型中所有算子执行的时间总和就是执行耗时。那么我们通过打开task_time_{device_id}_{model_id}_{iter_id}.json文件查看Task Scheduler任务调度信息数据,分析执行推理过程中具体耗时较长的任务。如图6所示。
从Task Scheduler任务调度信息数据中我们可以看到,时间线中执行了大量的Conv算子(时间线过长图片无法完全展示),且每个Conv算子的执行时间都比其他算子长。
至此我们基本可以判断拖慢应用推理过程中执行效率的因素中,Conv算子的占比较大。
- 为了进一步验证这个结论我们可以打开summary数据中的ai_stack_time_{device_id}_{model_id}_{iter_id}.csv文件如图7所示、acl_{device_id}_{model_id}_{iter_id}.csv文件如图8所示和task_time_{device_id}_{model_id}_{iter_id}.csv文件如图9所示。可以通过表格中的自定义排序,选择Duration为主要关键字,进行降序重排表格。
根据以上三张表中数据可以判断:各个组件耗时信息数据中AscendCL接口的aclmdlExcute接口耗时最长;AscendCL接口中耗时最长的时间线有两段,aclmdlExcute接口耗时排第二;Task Scheduler任务调度信息数据中存在大量的Conv算子,且每个Conv算子的执行时间都较长。
到此Profiling性能分析工具的任务已经完成。
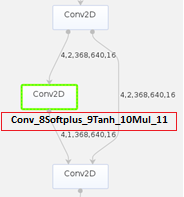
- 接下来我们可以参见《ATC工具使用指南》中的“原始模型文件或离线模型转成json文件”章节,打开PyTorch网络转换成的om模型查询Conv算子,发现该算子是多个计算单元组成,如图10所示,这样会造成极大的推理开销。
- 我们通过查询代码发现计算单元中的Softplus、Tanh和Mul是属于Mish激活函数的计算公式,如图11所示。而当前昇腾AI处理器支持的激活函数只有:Relu、Leakyrelu、Prelu、Elu和Srelu,Mish函数不在支持范围内,因此造成模型转换后的Mish函数被分解成了多个计算单元。
解决该问题最简单的办法就是找到效率更高的替代函数。



问题解决
尝试以官方提供的Leaky Relu激活函数作为替换函数。函数替换操作请用户自行处理,此处不作阐述。完成函数替换后重新执行Profiling性能分析操作得到新的结果中,我们查看图12已经从原先的23.299ms降低到现在的14.190ms,查看图13发现大多数Conv算子的时间线已经得到缩短。同时Leaky Relu函数的精度比Mish函数要小1%,Leaky Relu函数精度更高。
结论
通过Profiling性能分析工具前后两次对网络应用推理的运行时间进行分析,并对比两次执行时间可以得出结论,替换Leaky Relu激活函数后,降低了Conv算子在应用推理的运行时间,提升了推理效率。