迭代轨迹数据说明
请参见导出summary数据获取迭代轨迹数据step_trace_{device_id}_{model_id}_{iter_id}.csv,其中{device_id}表示设备ID,{model_id}表示某轮迭代的模型ID号,{iter_id}表示某轮迭代的ID号。
step_trace_{device_id}_{model_id}_{iter_id}.csv文件内容格式示例如下:

导出的迭代轨迹数据表文件列说明如下:
|
字段名 |
字段解释 |
|---|---|
|
Iteration ID |
迭代ID。 |
|
FP Start |
FP开始时间。 |
|
BP End |
BP结束时间。 |
|
Iteration End |
迭代最后一次梯度聚合完成时间。 |
|
Iteration Time(us) |
迭代时长(本轮迭代Iteration End - 本轮迭代Iteration End)。因为计算第一轮迭代时长时没有上一轮迭代的Iteration End数据,所以第一轮迭代时长计算公式使用:本轮Iteration End – 本轮FP Start时间。单位为us。 |
|
FP to BP Time(us) |
FP/BP计算时间(BP End - FP Start)。单位为us。 |
|
Grad Refresh Bound(us) |
梯度更新拖尾(Iteration End - BP End)。单位为us。 |
|
Data Aug Bound(us) |
数据增强拖尾(本轮迭代FP Start - 上一个迭代Iteration End)。因为计算第一轮数据增强拖尾时没有上一轮迭代的Iteration End数据,因此第一轮迭代的数据增强拖尾数据值默认为N/A。单位为us。 |
|
model_id |
某轮迭代的模型中的图ID。 |
|
Reduce |
集合通信时间,可能存在多组集合通信时间,本示例按照系统默认切分策略是分为两段集合通信时间,Reduce Start表示开始时间,Reduce Duration表示由开始到结束时间,单位us;如果非多P环境,则没有Reduce数据。 |
迭代轨迹数据即训练任务及AI软件栈的软件信息,实现对训练任务的性能分析。以默认的两段式梯度切分为例,通过打印出训练任务中关键节点fp_start/bp_end/Reduce Start/Reduce Duration(us)的时间,达到把一个迭代的执行情况描述清楚的目的。
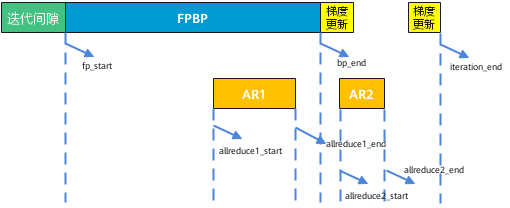
如图,如果需要确定梯度切分策略,则需要计算图中bp_end - allreduce1_end的大小。根据已获取的迭代轨迹数据,我们需要使用第一组集合通信时间来计算,具体公式如下:bp_end - allreduce1_end = (BP End - Reduce Start) / 100 - Reduce Duration,其中BP End、Reduce Start、Reduce Duration参见表1。若bp_end - allreduce1_end计算结果大于0,则表示AR1被隐藏在BPFP之间。