功能介绍
简介
专家系统(Advisor)是用于聚焦模型和算子的性能调优TOP问题,识别性能瓶颈Pattern,重点构建模型和算子瓶颈分析并提供优化推荐,支撑开发效率提升的工具。当前提供的功能有:基于Roofline模型的算子瓶颈识别与优化建议、算子优化分析、基于Timeline的AI CPU算子优化、算子融合推荐、TransData算子识别和基于训练场景的优化推荐。
基于Roofline模型的算子瓶颈识别与优化建议
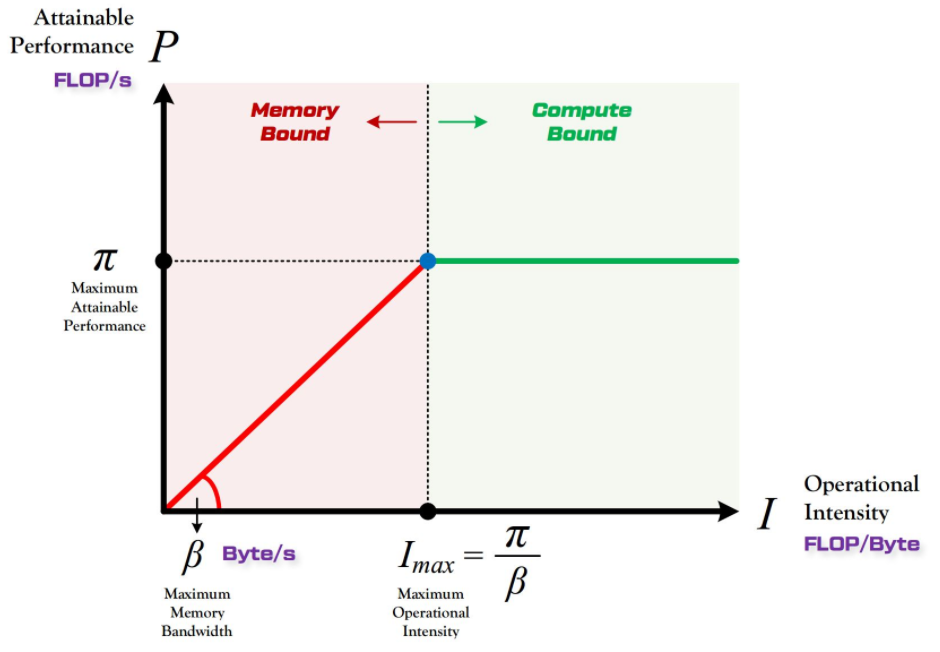
如图1所示,横坐标单位是FLOP/Byte,表示计算强度,每搬运1byte数据可以进行多少次运算,越大表示内存搬运利用率越高。纵坐标单位是FLOP/s,表示运算速度,越大表示运算越快。
当横坐标很大时,表示每搬运1byte数据可以进行很多的运算,但是每秒的运算次数无法超过硬件的性能上限π,即图中绿色横线;随着横坐标减小到一定的阈值以下,即图中蓝点的横坐标Imax,搬运的数据将不支持硬件达到性能上限的算力,此时的纵坐标性能为β·x,β表示硬件的带宽,即图中红色斜线。
蓝点将Roofline模型分成2个部分,红色部分为Memory Bound,绿色部分为Compute Bound,且实际工作点越靠近红线或绿线,表示Bound越严重,为主要瓶颈所在。
算子优化分析
在算子开发结束和整网运行出现算子性能不达标两种场景下,需要对算子进行调优。算子调优对开发者的要求比较高,需要开发者对底层和框架有一定的了解,同时具备一定的算子调优经验。算子优化分析可以协助开发者迅速找到算子性能瓶颈,并给出相应的优化手段,能够有效提升开发者算子调优的效率。
通过输入算子仿真生成的dump文件,从向量指令的执行效率和流水打断两个维度进行分析,并给出分析的数据和相应的优化建议。
基于Timeline的AI CPU算子优化
AI CPU是昇腾AI处理器计算单元,因为该CPU计算处理单位自身瓶颈,导致运行在AI CPU上的算子影响模型的执行时间。AI CPU算子的优化往往是重点关注点和优化对象。
模型开发和模型转换过程中,引入AI CPU算子,出现因为串行等待AI CPU算子执行影响模型执行。
从时间序列分析,性能瓶颈一般由串行等待算子造成。当前Timeline时序信息以Stream粒度展示,无法直观发现算子间的串并行关系。
如图2,AI CPU Timeline中Task1(PTCopy)存在模型执行串行等待AI CPU算子执行,瓶颈分析模型需要主动识别这类瓶颈。AI CPU Timeline中Task2计算时间隐藏在AICore计算时间中,这类AI CPU算子执行可以忽略。

基于Timeline的AI CPU算子优化以Profiling Task Scheduler任务调度文件数据(task_time_xxxx.json)作为输入数据,自动识别串行执行AI CPU算子,给出优化建议,提升模型整体性能。
算子融合推荐
算子融合推荐包括UB算子融合、首层算子融合和L2融合(动态Batch切分)三个功能:
- 首层算子融合
在load3dv2支持输入通道非16/32对齐的场景,可以直接支持4通道卷积的,极大减少MTE2与cube运算。但是当前该模式存在一个问题:
- 非AIPP场景下,算子首层需要cast和trans_data算子进行图片的数据类型转换和数据排布格式转换,在C0=4的场景下,trans_data算子性能恶化严重,此时整网性能恶化严重;
- AIPP场景,此时网络首层会进行AIPP+conv融合或AIPP+conv+maxpooling融合,由于一般首层16通道卷积的耗时占比整网的10%左右,此时开启small channel模式会大幅提升整网性能。
首层算子融合以OM模型离线文件作为输入数据,自动发现OM模型中可优化的数据预处理算子,使能AIPP,提升性能。
- L2融合(动态Batch切分)
在整网中,由于某些算子层为L2融合,数据量较大(包含输入和输出数据),超出L2的空间,会引发DDR(DDR主要统计读写带宽,在Analysis Summary中以表格形式呈现)写回的操作;而DDR的带宽远小于L2,造成MTE2 bound严重,同时可能进一步引发流水问题。
以resnet50_int8_8batch为例:
理论上8batch的单算子计算耗时小于等于2倍4batch单算子计算耗时,但如果8batch各层的算子为L2融合,导致数据量变大,造成L2 cache空间不足,产生DDR写回情况,引发算子性能恶化。
表1 8batch_4batch算子计算性能对比 算子
8batch性能/us
4batch性能/us
8batch/4batch 倍数
res2a_branch2c
200.63
38.284
5.24
res2b_branch2c
189.97
40.527
4.69
res2c_branch2c
147.84
38.533
3.84
res3a_branch1
74.00
31.109
2.38
整网时间
2031
954
-
整网占比
30.2%
15.5%
-
如表1所示,可以看到8batch的算子计算耗时远超过4batch算子的2倍,算子性能恶化较严重。
专家系统工具通过分析OM模型中的各层算子,以及读取op_summary.csv数据,识别并输出L2融合且未达到性能瓶颈的算子。需要对这些算子进行切分以实现每层算子的数据均不超过L2的范围,防止DDR写回的情况发生。
TransData算子识别
模型中格式转换是影响模型性能的一个重要因素。当前格式转换由NPU CUBE单元的特性引入,在CV网络主要体现大量的4D与5D的转换,而在NLP网络主要体现为大量4D与NZ的转换。大量的TransData算子会影响模型的性能。
TransData算子识别功能通过分析模型引入TransData的常见场景,识别转化算子性能瓶颈,从算子层、适配层和模型层三个层面进行分析,选择合适的方案进行优化,减少模型中TransData的调用次数。
基于训练场景的优化推荐
训练场景下,Profiling采集用于性能瓶颈分析的数据包括数据增强(Data Aug)、正向-反向(FP_BP)计算、梯度更新(Grad Refresh)阶段的多伦迭代数据。专家系统根据训练场景的Profiling数据对三个阶段的数据进行性能瓶颈分析。该功能仅针对TensorFlow框架下的模型训练场景进行性能分析。