混合计算
针对在计算图中有不支持的算子的场景(例如py_func),为提供灵活性和扩展性,提供混合计算模式,可将不支持的算子留在Host由前端框架执行。
概述
昇腾AI处理器默认采用计算全下沉模式,即所有的计算类算子全部在Device侧执行,混合计算模式作为计算全下沉模式的补充,将部分不可离线编译下沉执行的算子(例如资源类算子)留在前端框架中在线执行,用于提升昇腾AI处理器支持TensorFlow的适配灵活性。
实现原理
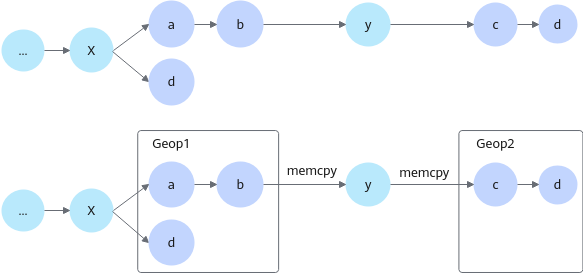
混合计算场景下,识别可下沉算子后,TF Adapter将整图拆分成多个Geop,中间不可下沉算子通过memcpy来完成数据传输。
使用注意事项
- 混合计算模式下,不能同时开启训练迭代循环下沉,即iterations_per_loop必须保持默认1。
- 除了系统默认不下沉的算子外,用户还可通过without_npu_compile_scope自行配置不下沉的算子。
- FusedBatchNormV3是2019年推出的新算子,它的第五个输出是与cuda相关的优化输出,混合计算模式下,在昇腾AI处理器上尚不支持。用户训练脚本中如果使用了tf.layers.batch_normalization,可以通过“with compat.forward_compatibility_horizon(2019, 5, 1):”规避使用该算子。
Estimator模式下开启混合计算
Estimator模式下,通过NPURunConfig中的mix_compile_mode参数开启混合计算功能:
1 2 3 4 | from npu_bridge.npu_init import * session_config=tf.ConfigProto(allow_soft_placement=True) config = NPURunConfig(session_config=session_config, mix_compile_mode=True, iterations_per_loop=1) |
sess.run模式下开启混合计算
sess.run模式下,通过session配置项mix_compile_mode开启混合计算功能。
1 2 3 4 5 6 7 8 | import tensorflow as tf from npu_bridge.npu_init import * config = tf.ConfigProto(allow_soft_placement=True) custom_op = config.graph_options.rewrite_options.custom_optimizers.add() custom_op.name = "NpuOptimizer" custom_op.parameter_map["mix_compile_mode"].b = True config.graph_options.rewrite_options.remapping = RewriterConfig.OFF config.graph_options.rewrite_options.memory_optimization = RewriterConfig.OFF |
Keras模式下开启混合计算
与sess.run模式配置方式类似。
指定不下沉的算子
开启了混合计算功能后,系统会把不能在device侧执行的算子留在host侧执行,但如果用户还需指定某些不下沉的算子,需要通过without_npu_compile_scope自行配置。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | import tensorflow as tf from npu_bridge.npu_init import * X = tf.random_normal([2,]) Y = tf.random_normal([2,]) with npu_scope.without_npu_compile_scope(): pred = tf.add(tf.multiply(X, 1.), 0.) # tf.add和tf.multiply指定为不下沉算子 cost = tf.reduce_sum(tf.abs(pred-Y)) config = tf.ConfigProto(allow_soft_placement=True) custom_op = config.graph_options.rewrite_options.custom_optimizers.add() custom_op.name = "NpuOptimizer" custom_op.parameter_map["mix_compile_mode"].b = True config.graph_options.rewrite_options.remapping = RewriterConfig.OFF config.graph_options.rewrite_options.memory_optimization = RewriterConfig.OFF with tf.Session(config=config) as sess: print(sess.run(cost)) |
父主题: 更多特性