torch_npu.npu_grouped_matmul
功能描述
- 算子功能:npu_grouped_matmul是一种对多个矩阵乘法(matmul)操作进行分组计算的高效方法。该API实现了对多个矩阵乘法操作的批量处理,通过将具有相同形状或相似形状的矩阵乘法操作组合在一起,减少内存访问开销和计算资源的浪费,从而提高计算效率。
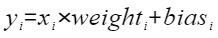
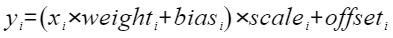
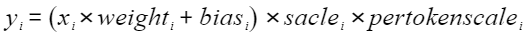
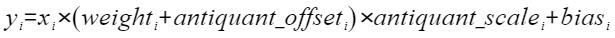
接口原型
npu_grouped_matmul(x, weight, *, bias=None, scale=None, offset=None, antiquant_scale=None, antiquant_offset=None, per_token_scale=None, group_list=None, activation_input=None, activation_quant_scale=None, activation_quant_offset=None, split_item=0, group_type=-1, group_list_type=0, act_type=0, output_dtype=None) -> List[torch.Tensor]
参数说明
- x (List[torch.Tensor]):输入矩阵列表,表示矩阵乘法中的左矩阵。
- 支持的数据类型如下:
Atlas A2 训练系列产品/Atlas 800I A2 推理产品/A200I A2 Box 异构组件 、Atlas A3 训练系列产品/Atlas A3 推理系列产品 :torch.float16、torch.float32、torch.bfloat16和torch.int8。Atlas 推理系列产品 :torch.float16。
- 列表最大长度为128。
- 当split_item=0时,张量支持2至6维输入;其他情况下,张量仅支持2维输入。
- 支持的数据类型如下:
- weight (List[torch.Tensor]):权重矩阵列表,表示矩阵乘法中的右矩阵。
- 支持的数据类型如下:
Atlas A2 训练系列产品/Atlas 800I A2 推理产品/A200I A2 Box 异构组件 、Atlas A3 训练系列产品/Atlas A3 推理系列产品 :- 当group_list输入类型为List[int]时,支持torch.float16、torch.float32、torch.bfloat16和torch.int8。
- 当group_list输入类型为torch.Tensor时,支持torch.float16、torch.float32、torch.bfloat16、int4和torch.int8。
Atlas 推理系列产品 :torch.float16。
- 列表最大长度为128。
- 每个张量支持2维或3维输入。
- 支持的数据类型如下:
- bias (List[torch.Tensor]):每个分组的矩阵乘法输出的独立偏置项。
- 支持的数据类型如下:
Atlas A2 训练系列产品/Atlas 800I A2 推理产品/A200I A2 Box 异构组件 、Atlas A3 训练系列产品/Atlas A3 推理系列产品 :torch.float16、torch.float32和torch.int32。Atlas 推理系列产品 :torch.float16。
- 列表长度与weight列表长度相同。
- 每个张量仅支持1维输入。
- 支持的数据类型如下:
- scale (List[torch.Tensor]):用于缩放原数值以匹配量化后的范围值,代表量化参数中的缩放因子,对应公式(2)和公式(3)。
- 支持的数据类型如下:
Atlas A2 训练系列产品/Atlas 800I A2 推理产品/A200I A2 Box 异构组件 、Atlas A3 训练系列产品/Atlas A3 推理系列产品 :- 当group_list输入类型为List[int]时,支持torch.int64。
- 当group_list输入类型为torch.Tensor时,支持torch.float32、torch.bfloat16和torch.int64。
Atlas 推理系列产品 :仅支持传入None。
- 列表长度与weight列表长度相同。
- 每个张量仅支持1维输入。
- 支持的数据类型如下:
- offset (List[torch.Tensor]):用于调整量化后的数值偏移量,从而更准确地表示原始浮点数值,对应公式(2)。当前仅支持传入None。
- antiquant_scale (List[torch.Tensor]):用于缩放原数值以匹配伪量化后的范围值,代表伪量化参数中的缩放因子,对应公式(4)。
- 支持的数据类型如下:
Atlas A2 训练系列产品/Atlas 800I A2 推理产品/A200I A2 Box 异构组件 、Atlas A3 训练系列产品/Atlas A3 推理系列产品 :torch.float16、torch.bfloat16。Atlas 推理系列产品 :仅支持传入None。
- 列表长度与weight列表长度相同。
- 每个张量支持输入维度如下(其中g为matmul组数,G为per-group数,Gi为第i个tensor的per-group数):
- 伪量化per-channel场景,weight为单tensor时,shape限制为[g, n];weight为多tensor时,shape限制为[ni]。
- 伪量化perr-group场景,weight为单tensor时,shape限制为[g, G, n];weight为多tensor时,shape限制为[Gi, ni]。
- 支持的数据类型如下:
- antiquant_offset (List[torch.Tensor]):用于调整伪量化后的数值偏移量,从而更准确地表示原始浮点数值,对应公式(4)。
- 支持的数据类型如下:
Atlas A2 训练系列产品/Atlas 800I A2 推理产品/A200I A2 Box 异构组件 、Atlas A3 训练系列产品/Atlas A3 推理系列产品 :torch.float16、torch.bfloat16。Atlas 推理系列产品 :仅支持传入None。
- 列表长度与weight列表长度相同。
- 每个张量输入维度和antiquant_scale输入维度一致。
- 支持的数据类型如下:
- per_token_scale (List[torch.Tensor]):用于缩放原数值以匹配量化后的范围值,代表per-token量化参数中由x量化引入的缩放因子,对应公式(3)。
- group_list输入类型为List[int]时,当前只支持传入None。
- group_list输入类型为torch.Tensor时:
- 数据类型支持torch.float32。
- 列表长度与x列表长度相同。
- 每个张量仅支持1维输入。
- group_list (List[int]/torch.Tensor):用于指定分组的索引,表示x的第0维矩阵乘法的索引情况。数据类型支持torch.int64。
Atlas A2 训练系列产品/Atlas 800I A2 推理产品/A200I A2 Box 异构组件 、Atlas A3 训练系列产品/Atlas A3 推理系列产品 :支持List[int]或torch.Tensor类型。若为torch.Tensor类型,仅支持1维输入,长度与weight列表长度相同。Atlas 推理系列产品 :仅支持torch.Tensor类型。仅支持1维输入,长度与weight列表长度相同。- 配置值要求如下:
- group_list输入类型为List[int]时,配置值必须为非负递增数列,且长度不能为1。
- group_list输入类型为torch.Tensor时:
- 当group_list_type为0时,group_list必须为非负、单调非递减数列。
- 当group_list_type为1时,group_list必须为非负数列,且长度不能为1。
- activation_input (List[torch.Tensor]):代表激活函数的反向输入,当前仅支持传入None。
- activation_quant_scale (List[torch.Tensor]):预留参数,当前只支持传入None。
- activation_quant_offset (List[torch.Tensor]):预留参数,当前只支持传入None。
- split_item (int):用于指定切分模式。数据类型支持torch.int32。
- 0/1:输出为多个张量,数量与weight相同。
- 2/3:输出为单个张量。
- group_type (int):代表需要分组的轴。数据类型支持torch.int32。
- group_list_type (int):代表group_list的表达形式。数据类型支持torch.int32。
- act_type (int):代表激活函数类型。数据类型支持torch.int32。
- output_dtype (torch.dtype):输出数据类型。支持的配置包括:
- None:默认值,表示输出数据类型与输入x的数据类型相同。
- 与输出y数据类型一致的类型,具体参考约束说明。
返回值
- 当split_item为0或1时,返回的张量数量与weight相同。
- 当split_item为2或3时,返回的张量数量为1。
约束说明
- 该接口仅在推理场景下使用。
- 该接口支持图模式(目前仅支持PyTorch 2.1.0版本)。
- x和weight中每一组tensor的最后一维大小都应小于65536。xi的最后一维指当x不转置时xi的K轴或当x转置时xi的M轴。weighti的最后一维指当weight不转置时weighti的N轴或当weight转置时weighti的K轴。
- 各场景输入与输出数据类型使用约束:
- group_list输入类型为List[int]时,
Atlas A2 训练系列产品/Atlas 800I A2 推理产品/A200I A2 Box 异构组件 、Atlas A3 训练系列产品/Atlas A3 推理系列产品 数据类型使用约束。表1 数据类型约束 场景
x
weight
bias
scale
antiquant_scale
antiquant_offset
output_dtype
y
非量化
torch.float16
torch.float16
torch.float16
无需赋值
无需赋值
无需赋值
torch.float16
torch.float16
torch.bfloat16
torch.bfloat16
torch.float32
无需赋值
无需赋值
无需赋值
torch.bfloat16
torch.bfloat16
torch.float32
torch.float32
torch.float32
无需赋值
无需赋值
无需赋值
torch.float32
torch.float32
per-channel量化
torch.int8
torch.int8
torch.int32
torch.int64
无需赋值
无需赋值
torch.int8
torch.int8
伪量化
torch.float16
torch.int8
torch.float16
无需赋值
torch.float16
torch.float16
torch.float16
torch.float16
torch.bfloat16
torch.int8
torch.float32
无需赋值
torch.bfloat16
torch.bfloat16
torch.bfloat16
torch.bfloat16
- group_list输入类型为torch.Tensor时,数据类型使用约束。
Atlas A2 训练系列产品/Atlas 800I A2 推理产品/A200I A2 Box 异构组件 、Atlas A3 训练系列产品/Atlas A3 推理系列产品 :表2 数据类型约束 场景
x
weight
bias
scale
antiquant_scale
antiquant_offset
per_token_scale
output_dtype
y
非量化
torch.float16
torch.float16
torch.float16
无需赋值
无需赋值
无需赋值
无需赋值
None/torch.float16
torch.float16
torch.bfloat16
torch.bfloat16
torch.float32
无需赋值
无需赋值
无需赋值
无需赋值
None/torch.bfloat16
torch.bfloat16
torch.float32
torch.float32
torch.float32
无需赋值
无需赋值
无需赋值
无需赋值
None/torch.float32(仅x/weight/y均为单张量)
torch.float32
per-channel量化
torch.int8
torch.int8
torch.int32
torch.int64
无需赋值
无需赋值
无需赋值
None/torch.int8
torch.int8
torch.int8
torch.int8
torch.int32
torch.bfloat16
无需赋值
无需赋值
无需赋值
torch.bfloat16
torch.bfloat16
torch.int8
torch.int8
torch.int32
torch.float32
无需赋值
无需赋值
无需赋值
torch.float16
torch.float16
per-token量化
torch.int8
torch.int8
torch.int32
torch.bfloat16
无需赋值
无需赋值
torch.float32
torch.bfloat16
torch.bfloat16
torch.int8
torch.int8
torch.int32
torch.float32
无需赋值
无需赋值
torch.float32
torch.float16
torch.float16
伪量化
torch.float16
torch.int8/int4
torch.float16
无需赋值
torch.float16
torch.float16
无需赋值
None/torch.float16
torch.float16
torch.bfloat16
torch.int8/int4
torch.float32
无需赋值
torch.bfloat16
torch.bfloat16
无需赋值
None/torch.bfloat16
torch.bfloat16

- 伪量化场景,若weight的类型为torch.int8,仅支持per-channel模式;若weight的类型为int4,支持per-channel和per-group两种模式。若为per-group,per-group数G或Gi必须要能整除对应的ki。若weight为多tensor,定义per-group长度si = ki / Gi,要求所有si(i=1,2,...g)都相等。
- 伪量化场景,若weight的类型为int4,则weight中每一组tensor的最后一维大小都应是偶数。weighti的最后一维指weight不转置时weighti的N轴或当weight转置时weighti的K轴。并且在per-group场景下,当weight转置时,要求per-group长度si是偶数。tensor转置:指若tensor shape为[M,K]时,则stride为[1,M],数据排布为[K,M]的场景,即非连续tensor。
- 当前PyTorch不支持int4类型数据,需要使用时可以通过torch_npu.npu_quantize接口使用torch.int32数据表示int4。
Atlas 推理系列产品 :表3 数据类型约束 x
weight
bias
scale
antiquant_scale
antiquant_offset
per_token_scale
output_dtype
y
torch.float16
torch.float16
torch.float16
无需赋值
无需赋值
无需赋值
torch.float32
torch.float16
torch.float16
- group_list输入类型为List[int]时,
- 根据输入x、输入weight与输出y的Tensor数量不同,支持以下几种场景。场景中的“单”表示单个张量,“多”表示多个张量。场景顺序为x、weight、y,例如“单多单”表示x为单张量,weight为多张量,y为单张量。
- group_list输入类型为List[int]时,
Atlas A2 训练系列产品/Atlas 800I A2 推理产品/A200I A2 Box 异构组件 、Atlas A3 训练系列产品/Atlas A3 推理系列产品 各场景的限制。支持场景
场景说明
场景限制
多多多
x和weight为多张量,y为多张量。每组数据的张量是独立的。
- 仅支持split_item为0或1。
- x中tensor要求维度一致,支持2-6维,weight中tensor需为2维,y中tensor维度和x保持一致。
- x中tensor大于2维,group_list必须传空。
- x中tensor为2维且传入group_list,group_list的差值需与x中tensor的第一维一一对应。
单多单
x为单张量,weight为多张量,y为单张量。
- 仅支持split_item为2或3。
- 必须传group_list,且最后一个值与x中tensor的第一维相等。
- x、weight、y中tensor需为2维。
- weight中每个tensor的N轴必须相等。
单多多
x为单张量,weight为多张量,y为多张量。
- 仅支持split_item为0或1。
- 必须传group_list,group_list的差值需与y中tensor的第一维一一对应。
- x、weight、y中tensor需为2维。
多多单
x和weight为多张量,y为单张量。每组矩阵乘法的结果连续存放在同一个张量中。
- 仅支持split_item为2或3。
- x、weight、y中tensor需为2维。
- weight中每个tensor的N轴必须相等。
- 若传入group_list,group_list的差值需与x中tensor的第一维一一对应。
- group_list输入类型为torch.Tensor时,各场景的限制。
Atlas A2 训练系列产品/Atlas 800I A2 推理产品/A200I A2 Box 异构组件 、Atlas A3 训练系列产品/Atlas A3 推理系列产品 : - 量化、伪量化仅支持group_type为-1和0场景。
- 仅per-token量化场景支持激活函数计算。
group_type
支持场景
场景说明
场景限制
-1
多多多
x和weight为多张量,y为多张量。每组数据的张量是独立的。
- 仅支持split_item为0或1。
- x中tensor要求维度一致,支持2-6维,weight中tensor需为2维,y中tensor维度和x保持一致
- group_list必须传空。
- 支持weight转置,但weight中每个tensor是否转置需保持统一。
- x不支持转置。
0
单单单
x、weight与y均为单张量。
- 仅支持split_item为2或3。
- weight中tensor需为3维,x、y中tensor需为2维。
- 必须传group_list,且当group_list_type为0时,最后一个值与x中tensor的第一维相等,当group_list_type为1时,数值的总和与x中tensor的第一维相等。
- group_list第1维最大支持1024,即最多支持1024个group。
- 支持weight转置。
- x不支持转置。
0
单多单
x为单张量,weight为多张量,y为单张量。
- 仅支持split_item为2或3。
- 必须传group_list,且当group_list_type为0时,最后一个值与x中tensor的第一维相等,当group_list_type为1时,数值的总和与x中tensor的第一维相等,长度最大为128。
- x,weight,y中tensor需为2维。
- weight中每个tensor的N轴必须相等。
- 支持weight转置,但weight中每个tensor是否转置需保持统一。
- x不支持转置。
0
多多单
x和weight为多张量,y为单张量。每组矩阵乘法的结果连续存放在同一个张量中。
- 仅支持split_item为2或3。
- x、weight、y中tensor需为2维。
- weight中每个tensor的N轴必须相等。
- 若传入group_list,当group_list_type为0时,group_list的差值需与x中tensor的第一维一一对应,当group_list_type为1时,group_list的数值需与x中tensor的第一维一一对应,且长度最大为128。
- 支持weight转置,但weight中每个tensor是否转置需保持统一。
- x不支持转置。
Atlas 推理系列产品 :输入输出只支持float16的数据类型,输出y的n轴大小需要是16的倍数。
group_type
支持场景
场景说明
场景限制
0
单单单
x、weight与y均为单张量
- 仅支持split_item为2或3。
- weight中tensor需为3维,x、y中tensor需为2维。
- 必须传group_list,且当group_list_type为0时,最后一个值与x中tensor的第一维相等,当group_list_type为1时,数值的总和与x中tensor的第一维相等。
- group_list第1维最大支持1024,即最多支持1024个group。
- 支持weight转置,不支持x转置。
- group_list输入类型为List[int]时,
支持的型号
Atlas A2 训练系列产品/Atlas 800I A2 推理产品/A200I A2 Box 异构组件 Atlas 推理系列产品 Atlas A3 训练系列产品/Atlas A3 推理系列产品
调用示例
- 单算子模式调用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
import torch import torch_npu x1 = torch.randn(256, 256, device='npu', dtype=torch.float16) x2 = torch.randn(1024, 256, device='npu', dtype=torch.float16) x3 = torch.randn(512, 1024, device='npu', dtype=torch.float16) x = [x1, x2, x3] weight1 = torch.randn(256, 256, device='npu', dtype=torch.float16) weight2 = torch.randn(256, 1024, device='npu', dtype=torch.float16) weight3 = torch.randn(1024, 128, device='npu', dtype=torch.float16) weight = [weight1, weight2, weight3] bias1 = torch.randn(256, device='npu', dtype=torch.float16) bias2 = torch.randn(1024, device='npu', dtype=torch.float16) bias3 = torch.randn(128, device='npu', dtype=torch.float16) bias = [bias1, bias2, bias3] group_list = None split_item = 0 npu_out = torch_npu.npu_grouped_matmul(x, weight, bias=bias, group_list=group_list, split_item=split_item)
- 图模式调用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33
import torch import torch.nn as nn import torch_npu import torchair as tng from torchair.configs.compiler_config import CompilerConfig config = CompilerConfig() npu_backend = tng.get_npu_backend(compiler_config=config) class GMMModel(nn.Module): def __init__(self): super().__init__() def forward(self, x, weight): return torch_npu.npu_grouped_matmul(x, weight) def main(): x1 = torch.randn(256, 256, device='npu', dtype=torch.float16) x2 = torch.randn(1024, 256, device='npu', dtype=torch.float16) x3 = torch.randn(512, 1024, device='npu', dtype=torch.float16) x = [x1, x2, x3] weight1 = torch.randn(256, 256, device='npu', dtype=torch.float16) weight2 = torch.randn(256, 1024, device='npu', dtype=torch.float16) weight3 = torch.randn(1024, 128, device='npu', dtype=torch.float16) weight = [weight1, weight2, weight3] model = GMMModel().npu() model = torch.compile(model, backend=npu_backend, dynamic=False) custom_output = model(x, weight) if __name__ == '__main__': main()