基于捕获方式构建模型运行实例

本功能为试验特性,后续版本可能会存在变更,不支持应用于商用产品中。
基本原理
在当前主流框架(例如PyTorch)采用的Eager模式下,每个操作或任务都是边下发边执行,无需构建计算图,这种模式带来了即时可见的执行效果和便捷的调试功能,但同时也带来了Host的下发开销。随着性能优化的不断深入,这些Host开销逐渐成为瓶颈,变成不可忽视的问题。
在昇腾AI处理器上可以将相关任务下沉到Device上并执行,从而减少Host的开销。为了达到此效果,AscendCL提供了“捕获Stream任务到模型中、再执行模型推理”的功能,如图1所示,在aclmdlRICaptureBegin和aclmdlRICaptureEnd接口之间,所有在指定Stream上下发的任务不会立即执行,而是被暂存在模型的运行实例中,只有在调用aclmdlRIExecuteAsync接口执行模型推理时这些任务才会被真正执行。当Stream上的任务需要被多次执行时,无需再下发任务,只需多次调用aclmdlRIExecuteAsync接口执行模型即可,达到减少Host侧的任务下发开销的效果。任务执行完毕后,若无需再使用模型的运行实例,可调用aclmdlRIDestroy接口及时销毁该资源。
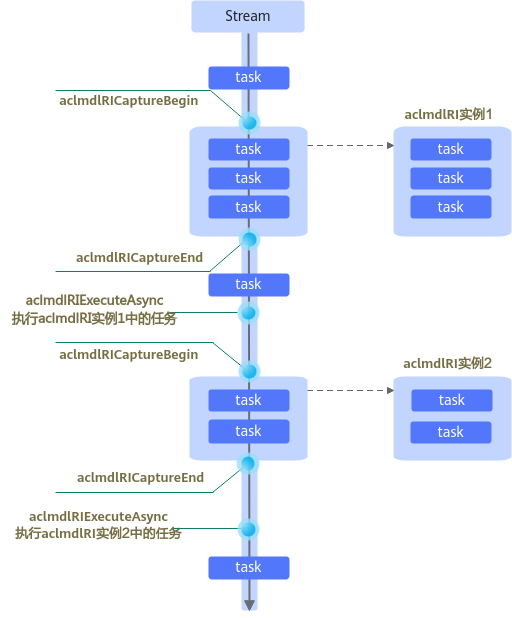
捕获任务到模型中、再执行模型推理的场景下,存在如下基本限制:
- 在进入捕获状态前,Stream上的任务依然是立即执行的。
- 在捕获过程中,对默认Stream的操作也是非法的。
- 在捕获过程中,任务使用的Device内存必须保持不变,直至模型不再被使用、被销毁后才能销毁相关资源。
- 在捕获过程中,在ACL_MODEL_RI_CAPTURE_MODE_GLOBAL模式(全局禁止,所有线程都不可以调用非安全函数)下,调用内存同步操作类函数(例如aclrtMemset、aclrtMemcpy、aclrtMemcpy2d)是非法的,会校验报错导致捕获失败。
然而,若业务侧确定这些函数的执行不会影响任务捕获,此时,可以通过调用aclmdlRICaptureThreadExchangeMode接口切换当前线程的捕获模式为ACL_MODEL_RI_CAPTURE_MODE_RELAXED,解除调用限制。
- 捕获Stream上的任务时,只会将任务下沉到Device上,并不会立即执行,因此,对Stream或Event的查询或同步均为非法操作。同样,对Device或Context的查询或同步也是非法的,因为Device和Context中包含了Stream的同步信息。
调用接口后,需增加异常处理的分支,并记录报错日志、提示日志,此处不一一列举。以下是关键步骤的代码示例,不可以直接拷贝编译运行,仅供参考。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 |
#include <stdio.h> #include <vector> #include "acl/acl.h" #include "aclnnop/aclnn_add.h" #define ACL_LOG(fmt, args...) fprintf(stdout, "[INFO] " fmt "\n", ##args) int64_t GetShapeSize(const std::vector<int64_t> &shape) { int64_t shape_size = 1; for (auto i : shape) { shape_size *= i; } return shape_size; } template <typename T> int CreateAclTensor(const std::vector<T> &hostData, const std::vector<int64_t> &shape, void **deviceAddr, aclDataType dataType, aclTensor **tensor) { auto size = GetShapeSize(shape) * sizeof(T); // 申请Device侧内存 auto ret = aclrtMalloc(deviceAddr, size, ACL_MEM_MALLOC_HUGE_FIRST); // 计算连续tensor的stride std::vector<int64_t> strides(shape.size(), 1); for (int64_t i = shape.size() - 2; i >= 0; i--) { strides[i] = shape[i + 1] * strides[i + 1]; } // 调用aclCreateTensor接口创建aclTensor *tensor = aclCreateTensor(shape.data(), shape.size(), dataType, strides.data(), 0, aclFormat::ACL_FORMAT_ND, shape.data(), shape.size(), *deviceAddr); return 0; } int main() { int devID = 0; void *self_d = nullptr; void *other_d = nullptr; void *out_d = nullptr; aclTensor *self = nullptr; aclTensor *other = nullptr; aclScalar *alpha = nullptr; aclTensor *out = nullptr; /* aclnnAdd: out = self + other * alpha */ std::vector<float> self_h = {0, 0, 0, 0, 0, 0, 0, 0}; std::vector<float> other_h = {1, 1, 1, 1, 1, 1, 1, 1}; std::vector<int64_t> shape = {4, 2}; float alphaValue = 1.1f; uint64_t workspaceSize = 0; aclOpExecutor *executor; auto size = GetShapeSize(shape); // AscendCL初始化 aclInit(NULL); // 指定计算设备 aclrtSetDevice(devID); // 准备aclnnAdd算子的输入、输出参数 CreateAclTensor(self_h, shape, &self_d, aclDataType::ACL_FLOAT, &self); CreateAclTensor(other_h, shape, &other_d, aclDataType::ACL_FLOAT, &other); alpha = aclCreateScalar(&alphaValue, aclDataType::ACL_FLOAT); CreateAclTensor(self_h, shape, &out_d, aclDataType::ACL_FLOAT, &out); // 获取算子计算所需的workspace大小以及包含了算子计算流程的执行器 aclnnAddGetWorkspaceSize(self, other, alpha, out, &workspaceSize, &executor); void *workspaceAddr = nullptr; if (workspaceSize > 0) { aclrtMalloc(&workspaceAddr, workspaceSize, ACL_MEM_MALLOC_HUGE_FIRST); } aclmdlRI modelRI; aclrtStream stream; aclrtCreateStream(&stream); // ========开始捕获任务======== aclmdlRICaptureBegin(stream, ACL_MODEL_RI_CAPTURE_MODE_GLOBAL); // 异步拷贝,将算子self输入的数据从Host侧传到Device侧 aclrtMemcpyAsync(self_d, size * sizeof(float), self_h.data(), size * sizeof(float), ACL_MEMCPY_HOST_TO_DEVICE, stream); // 切换捕获模式为RELAXED,允许调用aclrtMemcpy函数 aclmdlRICaptureMode mode = ACL_MODEL_RI_CAPTURE_MODE_RELAXED; aclmdlRICaptureThreadExchangeMode(&mode); // 同步拷贝,将算子other输入的数据从Host侧传到Device侧,仅执行一次 aclrtMemcpy(other_d, size * sizeof(float), other_h.data(), size * sizeof(float), ACL_MEMCPY_HOST_TO_DEVICE); // 将捕获模式切换回GLOBAL aclmdlRICaptureThreadExchangeMode(&mode); // 执行aclnnAdd算子 aclnnAdd(workspaceAddr, workspaceSize, executor, stream); // 异步拷贝,将算子输出数据从Device侧传回Host侧 aclrtMemcpyAsync(self_h.data(), size * sizeof(float), out_d, size * sizeof(float), ACL_MEMCPY_DEVICE_TO_HOST, stream); // ========结束捕获任务======== aclmdlRICaptureEnd(stream, &modelRI); // 打印模型信息,维测场景下使用 aclmdlRIDebugPrint(modelRI); // 多次执行模型 for (int i = 0; i < 8; i++) { aclmdlRIExecuteAsync(modelRI, stream); aclrtSynchronizeStream(stream); // 打印每一次的算子输出数据 ACL_LOG("%f %f %f %f %f %f %f %f\n", self_h.data()[0], self_h.data()[1], self_h.data()[2], self_h.data()[3], self_h.data()[4], self_h.data()[5], self_h.data()[6], self_h.data()[7]); } // 释放资源 aclmdlRIDestroy(modelRI); aclrtDestroyStream(stream); aclDestroyTensor(self); aclDestroyTensor(other); aclDestroyTensor(out); aclDestroyScalar(alpha); aclrtFree(self_d); aclrtFree(other_d); aclrtFree(out_d); if (workspaceAddr != nullptr) { aclrtFree(workspaceAddr); } // 释放计算设备的资源 aclrtResetDevice(devID); // AscendCL去初始化 aclFinalize(); } |
跨Stream的任务捕获
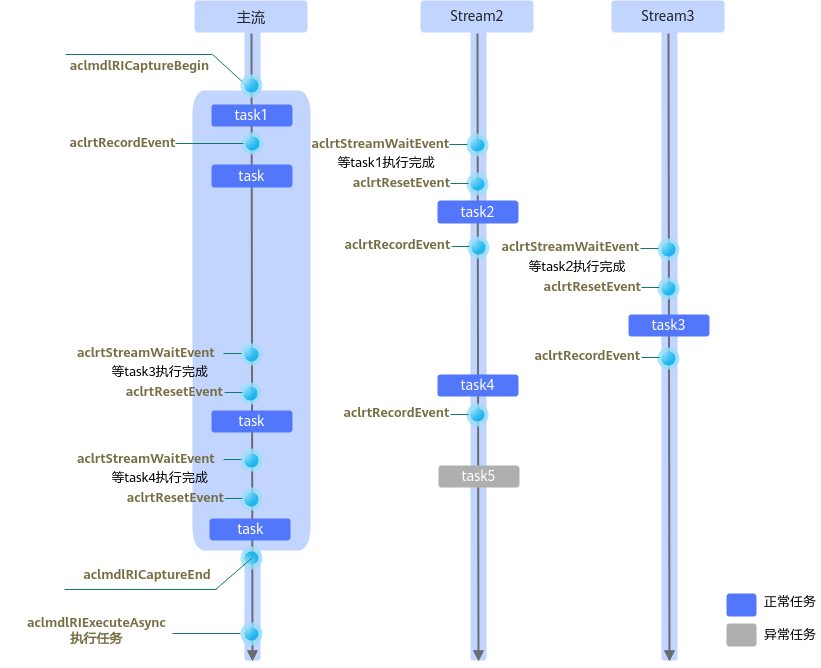
在捕获Stream上的任务时,aclmdlRICaptureBegin和aclmdlRICaptureEnd接口中指定的Stream只能是同一个Stream(我们将其称为“主流”),若要实现跨Stream的捕获任务,可调用aclrtRecordEvent接口在主流上下发Record Event任务、在其他Stream上调用aclrtStreamWaitEvent接口下发Wait Event任务,以建立主流与其他Stream的关联关系,从而将主流以及其他Stream上的任务捕获到同一个模型中。这时,该Event也会进入捕获状态,如果还有其他Stream等待该Event,那么,相应的Stream也会进入捕获状态。如图2所示,Stream2需等待主流上的task1任务完成,Stream3需等待Stream2上的task2任务完成,这种情况下,Stream2直接依赖主流,而Stream3相当于间接依赖主流,因此,Stream2、Stream3均会被纳入捕获状态,Stream2上的task2任务、Stream3上的task3任务也会被捕获到模型中。
通过Event加入捕获状态的Stream,最终还需要直接或间接的再通过Event返回到主流,否则会在结束捕获时触发报错。如图2所示,可调用aclrtRecordEvent接口在Stream2、Stream3上下发Record Event任务、在主流上调用aclrtStreamWaitEvent接口下发Wait Event任务,以实现Stream2、Stream3返回主流。另外,对于像Stream3这种间接依赖主流的情况,也可以在Stream3上下发Record Event任务、在Stream2上下发Wait Event任务,先将Stream3返回Stream2,然后再在Stream2上下发Record Event任务、在主流上下发Wait Event任务,最终返回到主流。返回主流之后,结束捕获前,不能再在Stream2、Stream3上下发task(例如图2中的task5),否则在结束捕获时会因为校验到有未被关联的task而触发报错。
结束捕获之后,Stream上的任务依然是立即执行的。
调用接口后,需增加异常处理的分支,并记录报错日志、提示日志,此处不一一列举。以下是关键步骤的代码示例,不可以直接拷贝编译运行,仅供参考。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 |
#include <stdio.h> #include <vector> #include "acl/acl.h" #include "aclnnop/aclnn_add.h" #define ACL_LOG(fmt, args...) fprintf(stdout, "[INFO] " fmt "\n", ##args) int64_t GetShapeSize(const std::vector<int64_t> &shape) { int64_t shape_size = 1; for (auto i : shape) { shape_size *= i; } return shape_size; } template <typename T> int CreateAclTensor(const std::vector<T> &hostData, const std::vector<int64_t> &shape, void **deviceAddr, aclDataType dataType, aclTensor **tensor) { auto size = GetShapeSize(shape) * sizeof(T); // 申请Device侧内存 auto ret = aclrtMalloc(deviceAddr, size, ACL_MEM_MALLOC_HUGE_FIRST); // 计算连续tensor的stride std::vector<int64_t> strides(shape.size(), 1); for (int64_t i = shape.size() - 2; i >= 0; i--) { strides[i] = shape[i + 1] * strides[i + 1]; } // 调用aclCreateTensor接口创建aclTensor *tensor = aclCreateTensor(shape.data(), shape.size(), dataType, strides.data(), 0, aclFormat::ACL_FORMAT_ND, shape.data(), shape.size(), *deviceAddr); return 0; } int main() { int devID = 0; void *self_d = nullptr; void *other_d = nullptr; void *out_d = nullptr; aclTensor *self = nullptr; aclTensor *other = nullptr; aclScalar *alpha = nullptr; aclTensor *out = nullptr; /* aclnnAdd: out = self + other * alpha */ std::vector<float> self_h = {0, 0, 0, 0, 0, 0, 0, 0}; std::vector<float> other_h = {1, 1, 1, 1, 1, 1, 1, 1}; std::vector<int64_t> shape = {4, 2}; float alphaValue = 1.1f; uint64_t workspaceSize = 0; aclOpExecutor *executor; auto size = GetShapeSize(shape); // AscendCL初始化 aclInit(NULL); // 指定计算设备 aclrtSetDevice(devID); // 准备aclnnAdd算子的输入、输出参数 CreateAclTensor(self_h, shape, &self_d, aclDataType::ACL_FLOAT, &self); CreateAclTensor(other_h, shape, &other_d, aclDataType::ACL_FLOAT, &other); alpha = aclCreateScalar(&alphaValue, aclDataType::ACL_FLOAT); CreateAclTensor(self_h, shape, &out_d, aclDataType::ACL_FLOAT, &out); // 获取算子计算所需的workspace大小以及包含了算子计算流程的执行器 aclnnAddGetWorkspaceSize(self, other, alpha, out, &workspaceSize, &executor); void *workspaceAddr = nullptr; if (workspaceSize > 0) { aclrtMalloc(&workspaceAddr, workspaceSize, ACL_MEM_MALLOC_HUGE_FIRST); } aclmdlRI modelRI; aclrtStream stream1, stream2; aclrtEvent event1, event2; aclrtCreateStream(&stream1); aclrtCreateStream(&stream2); aclrtCreateEvent(&event1); aclrtCreateEvent(&event2); // ========开始捕获任务======== aclmdlRICaptureBegin(stream1, ACL_MODEL_RI_CAPTURE_MODE_GLOBAL); // 异步拷贝,将算子self输入的数据从Host侧传到Device侧 aclrtMemcpyAsync(self_d, size * sizeof(float), self_h.data(), size * sizeof(float), ACL_MEMCPY_HOST_TO_DEVICE, stream1); // 切换捕获模式为RELAXED,允许调用aclrtMemcpy函数 aclmdlRICaptureMode mode = ACL_MODEL_RI_CAPTURE_MODE_RELAXED; aclmdlRICaptureThreadExchangeMode(&mode); // 同步拷贝,将算子other输入的数据从Host侧传到Device侧,仅执行一次 aclrtMemcpy(other_d, size * sizeof(float), other_h.data(), size * sizeof(float), ACL_MEMCPY_HOST_TO_DEVICE); // 将捕获模式切换回GLOBAL aclmdlRICaptureThreadExchangeMode(&mode); // 通过event1,将stream2加入捕获状态 aclrtRecordEvent(event1, stream1); aclrtStreamWaitEvent(stream2, event1); // 执行aclnnAdd算子 aclnnAdd(workspaceAddr, workspaceSize, executor, stream2); // stream2上的任务执行完成后,通过event2,让stream2返回主流stream1 aclrtRecordEvent(event2, stream2); aclrtStreamWaitEvent(stream1, event2); // 异步拷贝,将算子输出数据从Device侧传回Host侧 aclrtMemcpyAsync(self_h.data(), size * sizeof(float), out_d, size * sizeof(float), ACL_MEMCPY_DEVICE_TO_HOST, stream1); // ========结束捕获任务======== aclmdlRICaptureEnd(stream1, &modelRI); // 多次执行模型 for (int i = 0; i < 8; i++) { aclmdlRIExecuteAsync(modelRI, stream1); aclrtSynchronizeStream(stream1); // 打印每一次的算子输出数据 ACL_LOG("%f %f %f %f %f %f %f %f\n", self_h.data()[0], self_h.data()[1], self_h.data()[2], self_h.data()[3], self_h.data()[4], self_h.data()[5], self_h.data()[6], self_h.data()[7]); } // 释放资源 aclmdlRIDestroy(modelRI); aclrtDestroyStream(stream1); aclrtDestroyStream(stream2); aclrtDestroyEvent(event1); aclrtDestroyEvent(event2); aclDestroyTensor(self); aclDestroyTensor(other); aclDestroyTensor(out); aclDestroyScalar(alpha); aclrtFree(self_d); aclrtFree(other_d); aclrtFree(out_d); if (workspaceAddr != nullptr) { aclrtFree(workspaceAddr); } // 释放计算设备的资源 aclrtResetDevice(devID); // AscendCL去初始化 aclFinalize(); } |
任务更新功能
当Stream上的任务已经被捕获,并暂存到模型中之后,若要更新任务(包含任务本身以及任务的参数信息),当前支持两种方式:
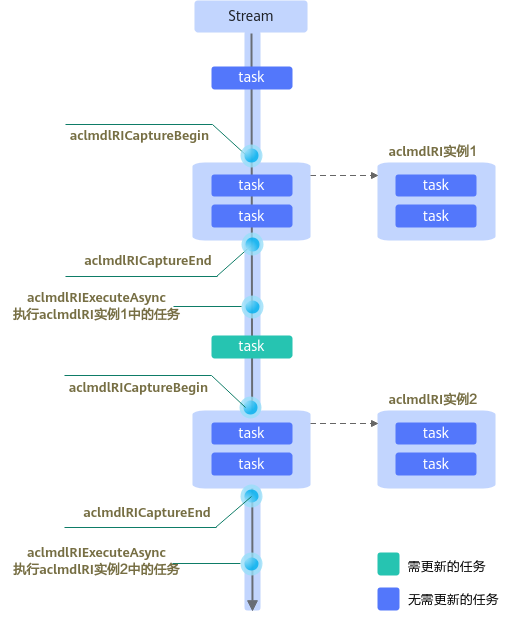
- 方式一:以需要更新的任务为分界点,在aclmdlRICaptureBegin和aclmdlRICaptureEnd接口之间分别捕获该任务前后的任务、并暂存到不同的模型中,分开执行。
该方式适用于大量任务需要更新的场景(例如一个模型有两种不同Shape的input输入场景),接口调用逻辑比较简单,但导致暂存捕获任务的模型数量增多,若模型数量超出硬件资源限制,则会触发报错。
该方式的基本使用流程如下图所示:
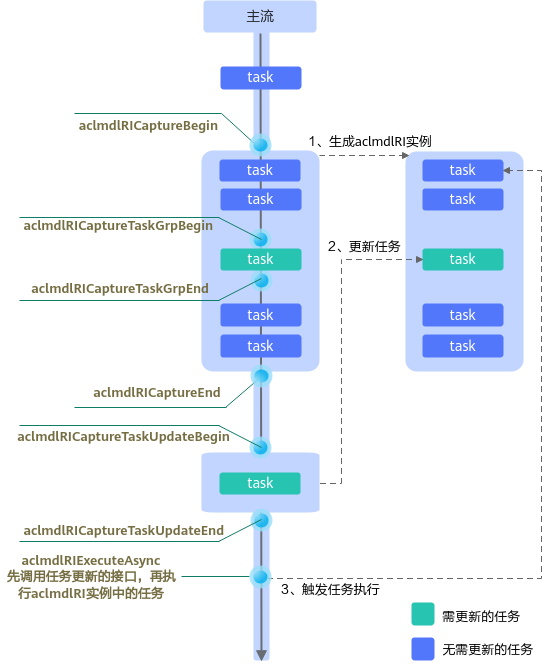
- 方式二:在aclmdlRICaptureBegin、aclmdlRICaptureEnd接口之间下发主流上需捕获的任务,通过aclmdlRICaptureTaskGrpBegin、aclmdlRICaptureTaskGrpEnd接口将待更新的任务标记为在一个任务组中,并返回任务组的handle,在aclmdlRICaptureTaskUpdateBegin、aclmdlRICaptureTaskUpdateEnd接口之间更新任务。
该方式适用于少量单算子调用任务需要更新的场景,支持先更新任务再依次执行模型实例中的任务,也支持更新任务与模型实例中其他任务的并发执行。但更新任务比单独下发任务更耗时,另外,还存在一些使用限制:aclmdlRICaptureTaskGrpBegin、aclmdlRICaptureTaskGrpEnd接口之间的任务数量、任务类型,要与aclmdlRICaptureTaskUpdateBegin、aclmdlRICaptureTaskUpdateEnd接口之间的任务数量、任务类型一致;跨Stream捕获任务的场景下,在aclmdlRICaptureTaskGrpBegin、aclmdlRICaptureTaskGrpEnd接口之间,其它捕获状态的Stream上不允许同时下发任务;任务组类似一个临界资源,不支持多线程多Stream并发更新,否则会导致更新结果非预期。
- 对于“先更新任务,再依次执行aclmdlRI实例中的任务”的场景,使用流程如下图所示:
- 对于“更新任务与其他任务的并发执行”的场景,使用流程如下图所示:
若模型的运行实例中存在大量任务,为了提升性能,可使用external类型的Event实现更新任务与其他任务的并发执行,并且需再单独创建一个用于更新任务的Stream(下文称之为UpdateStream)。这里的external类型的Event,是指调用aclrtCreateEventWithFlag接口并设置flag为ACL_EVENT_EXTERNAL的Event,这种类型的Event规格有限,需要考虑合理复用。创建external类型的Event之后,在UpdateStream上下发更新任务,接着调用aclrtRecordEvent接口下发一个Record Event任务。然后,在主流中,在待更新的任务之前,调用aclrtStreamWaitEvent接口下发一个Wait Event任务,用于等待UpdateStream中的任务更新完成。最后,在主流中,调用aclrtStreamWaitEvent接口之后,再调用aclrtResetEvent接口重置external类型的Event。
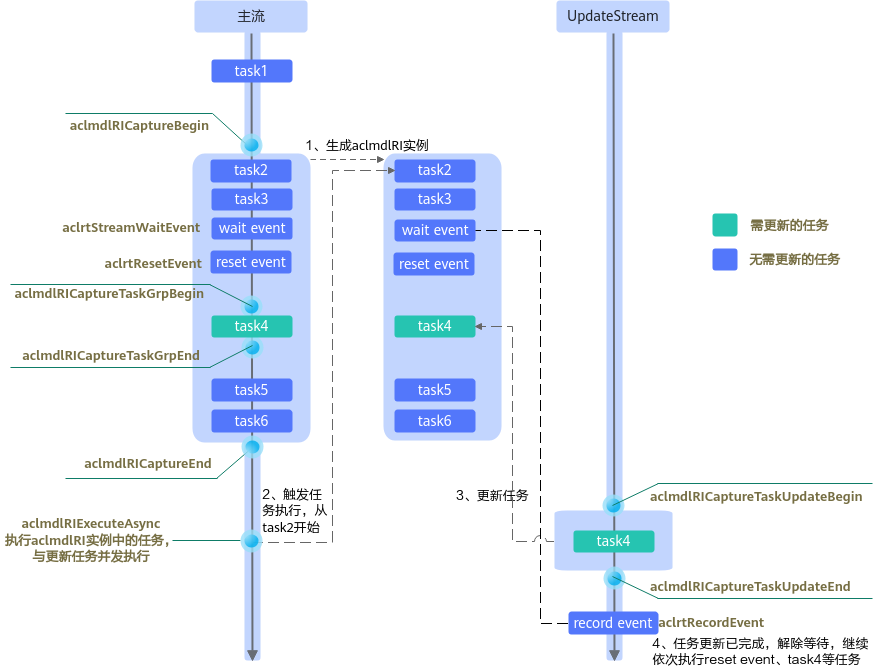
- 对于“先更新任务,再依次执行aclmdlRI实例中的任务”的场景,使用流程如下图所示:
以任务并发执行的场景为例,以下是更新aclnnAdd算子输入参数的关键代码示例,不可以直接拷贝编译运行,仅供参考。
#include <stdio.h>
#include <vector>
#include "acl/acl.h"
#include "aclnnop/aclnn_add.h"
#define ACL_LOG(fmt, args...) fprintf(stdout, "[INFO] " fmt "\n", ##args)
int64_t GetShapeSize(const std::vector<int64_t> &shape)
{
int64_t shape_size = 1;
for (auto i : shape) {
shape_size *= i;
}
return shape_size;
}
template <typename T>
int CreateAclTensor(const std::vector<T> &hostData, const std::vector<int64_t> &shape, void **deviceAddr,
aclDataType dataType, aclTensor **tensor)
{
auto size = GetShapeSize(shape) * sizeof(T);
// 申请Device侧内存
auto ret = aclrtMalloc(deviceAddr, size, ACL_MEM_MALLOC_HUGE_FIRST);
// 计算连续tensor的stride
std::vector<int64_t> strides(shape.size(), 1);
for (int64_t i = shape.size() - 2; i >= 0; i--) {
strides[i] = shape[i + 1] * strides[i + 1];
}
// 调用aclCreateTensor接口创建aclTensor
*tensor = aclCreateTensor(shape.data(),
shape.size(),
dataType,
strides.data(),
0,
aclFormat::ACL_FORMAT_ND,
shape.data(),
shape.size(),
*deviceAddr);
return 0;
}
int main()
{
int devID = 0;
void *self_d = nullptr;
void *other_d = nullptr;
void *out_d = nullptr;
void *outtmp_d = nullptr;
aclTensor *self = nullptr;
aclTensor *other = nullptr;
aclScalar *alpha = nullptr;
aclScalar *updatealpha = nullptr;
aclTensor *out = nullptr;
aclTensor *outtmp = nullptr;
/* aclnnAdd: self = self + other * alpha */
std::vector<float> self_h = {0, 0, 0, 0, 0, 0, 0, 0};
std::vector<float> other_h = {1, -1, 1, -1, 1, -1, 1, -1};
std::vector<int64_t> shape = {4, 2};
std::vector<float> out_h = {0, 0, 0, 0, 0, 0, 0, 0};
float alphaValue = 1.1f;
float updatealphaValue = 5.5f;
uint64_t workspaceSize = 0;
uint64_t workspaceSize1 = 0;
uint64_t workspaceSize2 = 0;
aclOpExecutor *executor2;
aclOpExecutor *executor;
aclOpExecutor *executor1;
auto size = GetShapeSize(shape);
// AscendCL初始化
aclInit(NULL);
// 指定计算设备
aclrtSetDevice(devID);
// 准备aclnnAdd算子的输入、输出参数
CreateAclTensor(self_h, shape, &self_d, aclDataType::ACL_FLOAT, &self);
CreateAclTensor(other_h, shape, &other_d, aclDataType::ACL_FLOAT, &other);
alpha = aclCreateScalar(&alphaValue, aclDataType::ACL_FLOAT);
updatealpha = aclCreateScalar(&updatealphaValue, aclDataType::ACL_FLOAT);
CreateAclTensor(self_h, shape, &out_d, aclDataType::ACL_FLOAT, &out);
CreateAclTensor(self_h, shape, &outtmp_d, aclDataType::ACL_FLOAT, &outtmp);
// 调用aclnnAdd算子的第一段接口,获取算子计算所需的workspace大小以及包含了算子计算流程的执行器
// 后续涉及多次调用aclnnAdd算子,此处需调用多次第一段接口,获取不同的aclOpExecutor
// outtmp = self + alpha * other
// 更新前:out = outtmp + alpha * other 更新后:out = outtmp + updatealpha * other
aclnnAddGetWorkspaceSize(self, other, alpha, outtmp, &workspaceSize, &executor);
void *workspaceAddr = nullptr;
if (workspaceSize > 0) {
aclrtMalloc(&workspaceAddr, workspaceSize, ACL_MEM_MALLOC_HUGE_FIRST);
}
// 更新前:out = outtmp + alpha * other
aclnnAddGetWorkspaceSize(outtmp, other, alpha, out, &workspaceSize1, &executor1);
void *workspaceAddr1 = nullptr;
if (workspaceSize1 > 0) {
aclrtMalloc(&workspaceAddr1, workspaceSize1, ACL_MEM_MALLOC_HUGE_FIRST);
}
// 更新后:out = outtmp + updatealpha * other
aclnnAddGetWorkspaceSize(outtmp, other, updatealpha, out, &workspaceSize2, &executor2);
void *workspaceAddr2 = nullptr;
if (workspaceSize2 > 0) {
aclrtMalloc(&workspaceAddr2, workspaceSize2, ACL_MEM_MALLOC_HUGE_FIRST);
}
aclmdlRI modelRI;
aclrtStream stream1;
aclrtCreateStream(&stream1);
aclrtEvent event;
// 创建external类型的event
aclrtCreateEventWithFlag(&event, ACL_EVENT_EXTERNAL);
// ========开始捕获任务========
aclmdlRICaptureBegin(stream1, ACL_MODEL_RI_CAPTURE_MODE_GLOBAL);
// 异步拷贝,将aclnnAdd算子self输入的数据从Host侧传到Device侧
aclrtMemcpyAsync(self_d, size * sizeof(float), self_h.data(), size * sizeof(float), ACL_MEMCPY_HOST_TO_DEVICE, stream1);
// 异步拷贝,将aclnnAdd算子other输入的数据从Host侧传到Device侧
aclrtMemcpyAsync(other_d, size * sizeof(float), other_h.data(), size * sizeof(float), ACL_MEMCPY_HOST_TO_DEVICE, stream1);
// 执行aclnnAdd算子
aclnnAdd(workspaceAddr, workspaceSize, executor, stream1);
// 在主流stream1上,下发一个Event Wait任务,等待更新任务完成
aclrtStreamWaitEvent(stream1, event);
aclrtResetEvent(event, stream1);
aclrtTaskGrp handle;
// 标记要更新的任务
aclmdlRICaptureTaskGrpBegin(stream1);
aclnnAdd(workspaceAddr1, workspaceSize1, executor1, stream1);
aclmdlRICaptureTaskGrpEnd(stream1, &handle);
// 异步拷贝,将算子输出数据从Device侧传回Host侧
aclrtMemcpyAsync(out_h.data(), size * sizeof(float), out_d, size * sizeof(float), ACL_MEMCPY_DEVICE_TO_HOST, stream1);
// ========结束捕获任务========
aclmdlRICaptureEnd(stream1, &modelRI);
aclrtStream updateStream;
aclrtCreateStream(&updateStream);
for (int i = 0; i < 2; i++) {
ACL_LOG("execute model, loop: %d", i);
aclmdlRIExecuteAsync(modelRI, stream1);
// 开始更新任务,将aclnnAdd算子的alpha参数更新为updatealpha
aclmdlRICaptureTaskUpdateBegin(updateStream, handle);
if (i == 1) {
aclnnAdd(workspaceAddr2, workspaceSize2, executor2, updateStream);
ACL_LOG("update alpha value of aclnnAdd");
}
aclmdlRICaptureTaskUpdateEnd(updateStream);
// 更新任务之后,在updateStream上,下发Event Record任务,用于通知主流stream1继续执行Event Wait之后的任务
aclrtRecordEvent(event, updateStream);
aclrtSynchronizeStream(updateStream);
aclrtSynchronizeStream(stream1);
ACL_LOG("%f %f %f %f %f %f %f %f\n",
out_h.data()[0],
out_h.data()[1],
out_h.data()[2],
out_h.data()[3],
out_h.data()[4],
out_h.data()[5],
out_h.data()[6],
out_h.data()[7]);
}
// 释放资源
aclmdlRIDestroy(modelRI);
aclDestroyTensor(self);
aclDestroyTensor(other);
aclDestroyTensor(out);
aclDestroyTensor(outtmp);
aclDestroyScalar(alpha);
aclDestroyScalar(updatealpha);
aclrtFree(self_d);
aclrtFree(other_d);
aclrtFree(out_d);
aclrtFree(outtmp_d);
aclrtDestroyStream(stream1);
aclrtDestroyStream(updateStream);
aclrtDestroyEvent(event);
if (workspaceAddr != nullptr) {
aclrtFree(workspaceAddr);
}
if (workspaceAddr1 != nullptr) {
aclrtFree(workspaceAddr1);
}
if (workspaceAddr2 != nullptr) {
aclrtFree(workspaceAddr2);
}
// 释放计算设备的资源
aclrtResetDevice(devID);
// AscendCL去初始化
aclFinalize();
}