TBuf的使用
在大多数算子开发时,核函数计算过程需要使用临时内存来存储运算的中间结果,这些中间结果以临时变量表示,临时变量占用的内存可以使用TBuf数据结构来管理,具体介绍请参考TBuf。下文将以输入的数据类型为bfloat16_t、在单核上运行的Add算子为例,介绍TBuf的使用方式。本样例中介绍的算子完整代码请参见使用临时内存的Add算子样例。
在
通过以上分析,得到Ascend C Add算子的设计规格如下:
|
算子类型(OpType) |
Add |
|||
|---|---|---|---|---|
|
算子输入输出 |
name |
shape |
data type |
format |
|
x(输入) |
(1, 2048) |
bfloat16_t |
ND |
|
|
y(输入) |
(1, 2048) |
bfloat16_t |
ND |
|
|
z(输出) |
(1, 2048) |
bfloat16_t |
ND |
|
|
核函数名称 |
add_custom |
|||
|
使用的主要接口 |
DataCopy:数据搬移接口 |
|||
|
Cast:矢量精度转换接口 |
||||
|
Add:矢量双目指令接口 |
||||
|
EnQue、DeQue等接口:Queue队列管理接口 |
||||
|
算子实现文件名称 |
add_custom.cpp |
|||
算子类实现
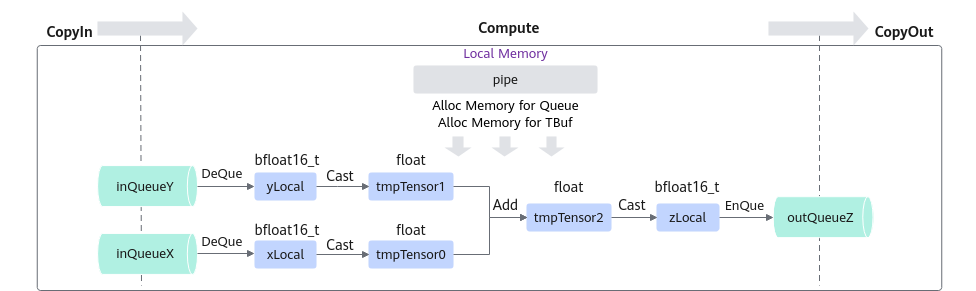
该样例的CopyIn,CopyOut任务与基础矢量算子相同,Compute任务的具体流程如下图所示。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
class KernelAdd { public: __aicore__ inline KernelAdd() {} __aicore__ inline void Init(GM_ADDR x, GM_ADDR y, GM_ADDR z){} __aicore__ inline void Process(){} private: __aicore__ inline void CopyIn(int32_t progress){} __aicore__ inline void Compute(int32_t progress){} __aicore__ inline void CopyOut(int32_t progress){} private: AscendC::TPipe pipe; AscendC::TQue<AscendC::TPosition::VECIN, BUFFER_NUM> inQueueX, inQueueY; AscendC::TQue<AscendC::TPosition::VECOUT, BUFFER_NUM> outQueueZ; AscendC::TBuf<AscendC::TPosition::VECCALC> tmpBuf0, tmpBuf1, tmpBuf2; AscendC::GlobalTensor<bfloat16_t> xGm; AscendC::GlobalTensor<bfloat16_t> yGm; AscendC::GlobalTensor<bfloat16_t> zGm; }; |
初始化函数阶段除原有步骤外,需要调用InitBuffer接口为TBuf变量分配内存,具体的初始化函数代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
__aicore__ inline void Init(GM_ADDR x, GM_ADDR y, GM_ADDR z) { xGm.SetGlobalBuffer((__gm__ half *)x, TOTAL_LENGTH); yGm.SetGlobalBuffer((__gm__ half *)y, TOTAL_LENGTH); zGm.SetGlobalBuffer((__gm__ half *)z, TOTAL_LENGTH); pipe.InitBuffer(inQueueX, 1, TOTAL_LENGTH * sizeof(bfloat16_t)); pipe.InitBuffer(inQueueY, 1, TOTAL_LENGTH * sizeof(bfloat16_t)); pipe.InitBuffer(outQueueZ, 1, TOTAL_LENGTH * sizeof(bfloat16_t)); pipe.InitBuffer(tmpBuf0, TOTAL_LENGTH * sizeof(float)); pipe.InitBuffer(tmpBuf1, TOTAL_LENGTH * sizeof(float)); pipe.InitBuffer(tmpBuf2, TOTAL_LENGTH * sizeof(float)); } |
基于矢量编程范式,核函数需要实现3个基本任务:CopyIn,Compute,CopyOut。与基础矢量算子实现相同,Process函数按顺序调用CopyIn函数,Compute函数,CopyOut函数。其中,CopyIn函数,CopyOut函数与基础矢量算子的CopyIn函数、基础矢量算子的CopyOut函数的实现没有差异,此处不过多赘述。Compute函数的实现步骤如下:
- 使用DeQue从VECIN的Queue中取出LocalTensor。
- 使用TBuf.Get从TBuf上获取全部长度的Tensor作为临时内存。
- 使用Cast接口将LocalTensor转换为float类型,并存入临时内存。
- 使用Add接口完成矢量计算,将计算结果存入临时内存。
- 使用Cast接口将临时内存中的计算结果转换为bfloat16_t类型。
- 使用EnQue将bfloat16_t类型的结果LocalTensor放入VECOUT的Queue中。
- 使用FreeTensor释放不再使用的LocalTensor。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
__aicore__ inline void Compute(int32_t progress) { AscendC::LocalTensor<bfloat16_t> xLocal = inQueueX.DeQue<bfloat16_t> (); AscendC::LocalTensor<bfloat16_t> yLocal = inQueueY.DeQue<bfloat16_t> (); AscendC::LocalTensor<bfloat16_t> zLocal = outQueueZ.AllocTensor<bfloat16_t> (); AscendC::LocalTensor<float> tmpTensor0 = tmpBuf0.Get<float>(); AscendC::LocalTensor<float> tmpTensor1 = tmpBuf1.Get<float>(); AscendC::LocalTensor<float> tmpTensor2 = tmpBuf2.Get<float>(); AscendC::Cast(tmpTensor0, xLocal, AscendC::RoundMode::CAST_NONE, TOTAL_LENGTH); AscendC::Cast(tmpTensor1, yLocal, AscendC::RoundMode::CAST_NONE, TOTAL_LENGTH); AscendC::Add(tmpTensor2, tmpTensor0, tmpTensor1, TOTAL_LENGTH); AscendC::Cast(zLocal, tmpTensor2, AscendC::RoundMode::CAST_RINT, TOTAL_LENGTH); outQueueZ.EnQue<bfloat16_t>(zLocal); inQueueX.FreeTensor(xLocal); inQueueY.FreeTensor(yLocal); } |