TensorFlow框架
本章节介绍TensorFlow框架算子适配的流程,用于将TensorFlow框架的算子映射成CANN算子(开发者基于CANN框架自定义开发的算子),从而完成从TensorFlow框架调用到CANN算子的过程。同时给出TensorFlow框架侧算子调用的示例,便于开发者了解完整流程。
下图展示了完整的开发流程,具体步骤如下:
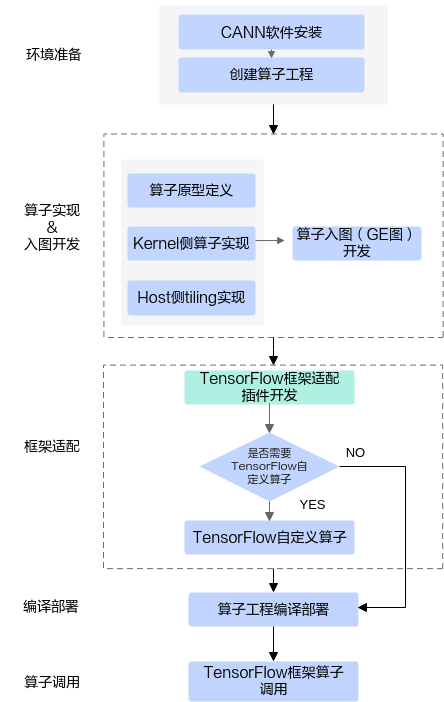
- 环境准备。
- CANN软件安装请参考环境准备。
- 创建算子工程。使用msOpGen工具创建算子开发工程。TensorFlow框架算子适配场景下,需要通过framework参数指定具体的框架为tf或者tensorflow,工具会自动生成框架适配代码。以自定义CANN算子AddCustom为例,使用msOpGen工具创建算子开发工程的具体命令如下:
${INSTALL_DIR}/python/site-packages/bin/msopgen gen -i $HOME/sample/add_custom.json -f tf -c ai_core-<soc_version> -lan cpp -out $HOME/sample/AddCustom
- 算子实现。
- 算子原型定义。通过原型定义来描述算子输入输出、属性等信息以及算子在AI处理器上相关实现信息,并关联tiling实现等函数。
- Kernel侧算子实现和host侧tiling实现请参考算子实现;工程化算子开发,支持开发者调用Tiling API基于CANN提供的编程框架进行tiling开发,kernel侧也提供对应的接口方便开发者获取tiling参数,具体内容请参考Kernel侧算子实现和Host侧tiling实现,由此而带来的额外约束也在上述章节说明。
- 算子入图(GE图)开发。算子入图场景下,需要提供shape推导等算子入图适配函数的实现。
- TensorFlow框架适配插件开发。详细说明见适配插件开发。
- 编译部署。通过工程编译脚本完成算子的编译部署。
- TensorFlow框架算子调用。详细说明见TensorFlow原生算子映射到CANN算子和TensorFlow自定义算子开发并映射到CANN算子。完整样例请参考LINK。
适配插件开发
完成算子工程创建后,会在算子工程目录下生成framework/tf_plugin目录,用于存放TensorFlow框架适配插件实现文件。以自定义CANN算子AddCustom为例,算子工程目录如下:
AddCustom ├── build.sh // 编译入口脚本 ├── cmake ├── CMakeLists.txt // 算子工程的CMakeLists.txt ├── CMakePresets.json // 编译配置项 ├── framework // 框架适配插件实现文件目录 │ ├── tf_plugin // TensorFlow框架适配插件实现文件目录 │ │ ├── CMakeLists.txt │ │ ├── tensorflow_add_custom_plugin.cc // TensorFlow框架适配插件实现文件 │ ├── CMakeLists.txt ├── op_host // host侧实现文件 ├── op_kernel // kernel侧实现文件 └── scripts // 自定义算子工程打包相关脚本所在目录
1 2 3 4 5 6 7 |
#include "register/register.h" namespace domi { REGISTER_CUSTOM_OP("AddCustom") .FrameworkType(TENSORFLOW) .OriginOpType("AddCustom") .ParseParamsByOperatorFn(AutoMappingByOpFn); } |
当TensorFlow算子与CANN算子原型定义不一致时,TensorFlow框架适配插件实现代码如下:
1 2 3 4 5 6 |
#include "register/register.h" REGISTER_CUSTOM_OP("FlashAttentionScore") .FrameworkType(TENSORFLOW) .OriginOpType({"FlashAttentionScore"}) .ParseParamsByOperatorFn(FlashAttentionScoreMapping) .ParseOpToGraphFn(AddOptionalPlaceholderForFA); |
- 包含插件实现函数相关的头文件。
register.h存储在CANN软件安装后文件存储路径的“include/register/”目录下,包含该头文件,可使用算子注册相关类,调用算子注册相关的接口。
- REGISTER_CUSTOM_OP:注册自定义算子,传入算子的OpType,需要与算子原型注册中的OpType保持一致。
- FrameworkType:TENSORFLOW代表原始框架为TensorFlow。
- OriginOpType:算子在原始框架中的类型。对于TensorFlow自定义算子,还需要完成TensorFlow自定义算子的开发,这里的OriginOpType与REGISTER_OP注册算子名相同,对于TensorFlow原生算子, 即为原生算子名。
- ParseParamsByOperatorFn:用来注册解析算子参数实现映射关系的回调函数,需要用户自定义实现回调函数ParseParamByOpFunc。原始TensorFlow算子中参数与CANN算子中参数一一对应时,可直接使用自动映射回调函数AutoMappingByOpFn自动实现映射。
- ParseOpToGraphFn:当TensorFlow算子与CANN算子原型定义不一致(比如CANN算子原型定义原型中有可选输入,但TensorFlow原型定义中不支持可选输入,没有可选输入)的情况时,用来注册调整算子原型映射关系的回调函数。
TensorFlow原生算子映射到CANN算子
以自定义算子AddCustom为例,将该算子映射到TensorFlow内置算子Add上,需要先修改AddCustom自定义算子目录framework/tf_plugin下插件代码,完成算子名映射:
1 2 3 4 5 6 7 |
#include "register/register.h" namespace domi { REGISTER_CUSTOM_OP("AddCustom") // 当前Ascend C自定义算子名 .FrameworkType(TENSORFLOW) // 第三方框架类型TENSORFLOW .OriginOpType("Add") // 映射到TensorFlow原生算子Add .ParseParamsByOperatorFn(AutoMappingByOpFn); } |
完成算子工程的编译部署后,构造单算子的TensorFlow 1.15版本测试用例进行验证。
- 编写测试用例“tf_add.py”。
- 导入python库。
1 2 3 4
import logging # Python标准库日志模块 import tensorflow as tf # 导入TensorFlow开源库 from npu_bridge.estimator import npu_ops # 导入TensorFlow开源库中的npu_ops模块 import numpy as np # 导入Python的数学基础库
- 通过config()定义昇腾AI处理器和CPU上的运行参数。
当“execute_type”为“ai_core”时,代表在昇腾AI处理器上运行单算子网络,最终会调用到Ascend C算子。
当“execute_type”为“cpu”时,代表在Host侧的CPU运行单算子网络,调用的是TensorFlow算子。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
def config(execute_type): if execute_type == 'ai_core': session_config = tf.ConfigProto( allow_soft_placement=True, log_device_placement=False,) custom_op = session_config.graph_options.rewrite_options.custom_optimizers.add() custom_op.name = "NpuOptimizer" custom_op.parameter_map["enable_data_pre_proc"].b = True # 开启数据预处理下沉到Device侧执行 custom_op.parameter_map["mix_compile_mode"].b = True custom_op.parameter_map["use_off_line"].b = True # True表示在昇腾AI处理器上执行训练 elif execute_type == 'cpu': session_config = tf.ConfigProto( allow_soft_placement=True, log_device_placement=False) return session_config
- 单算子网络测试用例主函数。
- 算子输入请根据算子实际输入个数及shape进行构造。
- 算子输出的计算,请根据算子逻辑调用TensorFlow相关接口进行实现。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32
#设置np.allclose比较函数的公差参数。 #np.allclose比较函数的相对公差参数 atol = 0.001 #np.allclose比较函数的绝对公差参数 rtol = 0.001 def main(unused_argv): shape_params = (8, 2048) dtype_params = np.float16 # 构造Add算子的两个输入数据,shape为shape_params,范围在[-2,2]之间的随机数 x_data = np.random.uniform(-2, 2, size=shape_params).astype(dtype_params) y_data = np.random.uniform(-2, 2, size=shape_params).astype(dtype_params) # 分别对Add算子的两个输入数据进行占位 x = tf.compat.v1.placeholder(dtype_params, shape=shape_params) y = tf.compat.v1.placeholder(dtype_params, shape=shape_params) # 计算算子输出 out = tf.math.add(x, y) # 在Host侧CPU上运行单算子,得到期望运行结果 with tf.compat.v1.Session(config=config('cpu')) as session: result_cpu = session.run(out, feed_dict={x: x_data, y: y_data}) # 在昇腾AI处理器上运行单算子,得到实际运行结果 with tf.compat.v1.Session(config=config('ai_core')) as session: result_ai_core = session.run(out, feed_dict={x: x_data, y: y_data}) np.array(result_ai_core).astype(dtype_params) np.array(result_cpu).astype(dtype_params) print('====================================') # 通过np.allclose比较昇腾AI处理器上运行的实际结果和cpu上运行的期望结果,其中atol和rtol为np.allclose比较函数的相对公差参数和绝对公差参数 cmp_result = np.allclose(result_ai_core, result_cpu, atol, rtol) print(cmp_result) print('====================================')
- 运行单算子网络。
1 2
if __name__ == "__main__": tf.app.run()
TensorFlow自定义算子开发并映射到CANN算子
- 适配插件代码开发。以自定义算子AddCustom为例,将该算子映射到TensorFlow自定义算子AddCustom上,需要先修改CANN AddCustom自定义算子工程目录framework/tf_plugin下插件代码,完成算子名映射:
1 2 3 4
REGISTER_CUSTOM_OP("AddCustom") .FrameworkType(TENSORFLOW) .OriginOpType("AddCustom") .ParseParamsByOperatorFn(AutoMappingByOpFn);
- TensorFlow自定义算子的开发。本节仅给出示例说明,详细内容请参考TensorFlow官方文档。
创建TensorFlow原型注册文件custom_assign_add_custom.cc,内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
#include "tensorflow/core/framework/op.h" #include "tensorflow/core/framework/shape_inference.h" #include "tensorflow/core/framework/op_kernel.h" #include "tensorflow/core/framework/common_shape_fns.h" using namespace tensorflow; // 通过TensorFlow提供的REGISTER_OP接口完成算子原型的注册 REGISTER_OP("AddCustom") // TensorFlow 注册算子名 .Input("x: T") // 算子原型,输入参数x,类型为T .Input("y: T") // 算子原型,输入参数y,类型为T .Output("z: T") // 算子原型,输入参数z,类型为T .Attr("T: {half}") // T类型支持范围 .SetShapeFn(shape_inference::BroadcastBinaryOpShapeFn); // 算子shape信息推导,BroadcastBinaryOpShapeFn为TensorFlow提供的内置函数,输出shape信息由输入shape传播推导,即输入和输出shape保持一致 // 实现一个CPU版本的kernel函数,因为Tensorflow的计算图在构建时会检查所有的算子是否有任意设备上的kernel函数(NPU Kernel无法被感知),如果没有将会报错。这里实现一个固定返回错误的CPU kernel函数: class AddCustomOp : public OpKernel { public: explicit AddCustomOp(OpKernelConstruction* context) : OpKernel(context) {} void Compute(OpKernelContext* context) override { OP_REQUIRES_OK(context, errors::Unimplemented("AddCustomOp is not supported on CPU")); } }; REGISTER_KERNEL_BUILDER(Name("AddCustom").Device(DEVICE_CPU), AddCustomOp); // 注册AddCustom算子的CPU实现内核,该函数当前仅打印日志提示CPU不支持
使用如下命令对上述代码进行编译,产物为libcustom_ops.so,后续的算子调用脚本中可通过load_op_library接口加载该so为python模块,从而调用自定义算子。
TF_CFLAGS=( $(python3 -c 'import tensorflow as tf; print(" ".join(tf.sysconfig.get_compile_flags()))') ) // 获取TensorFlow编译选项 TF_LFLAGS=( $(python3 -c 'import tensorflow as tf; print(" ".join(tf.sysconfig.get_link_flags()))') ) // 获取TensorFlow链接选项 SOURCE_FILES=custom_assign_add_custom.cc // 包含TensorFlow算子注册和CPU内核实现的cc文件 g++ -std=c++14 -shared $SOURCE_FILES -o ${Path}/libcustom_ops.so -fPIC ${TF_CFLAGS[@]} ${TF_LFLAGS[@]} -O2 // 编译命令,产物为libcustom_ops.so,TensorFlow即可通过load_op_library加载该so为python模块,调用自定义算子 - 测试脚本中加载上一步骤编译好的动态库,实现自定义算子的调用。
- TensorFlow 1.15.0调用代码示例
import os import tensorflow as tf import numpy as np from npu_bridge.npu_init import * tf.enable_resource_variables() #np.allclose比较函数的相对公差参数 atol = 0.001 #np.allclose比较函数的绝对公差参数 rtol = 0.001 def main(unused_argv): custom_op_lib = tf.load_op_library('./outputs/libcustom_ops.so') # 加载so为python模块 shape_params = (8, 2048) dtype_params = np.float16 x_data = np.random.uniform(-2, 2, size=shape_params).astype(dtype_params) y_data = np.random.uniform(-2, 2, size=shape_params).astype(dtype_params) x = tf.compat.v1.placeholder(dtype_params, shape=shape_params) y = tf.compat.v1.placeholder(dtype_params, shape=shape_params) tf_z = tf.math.add(x, y) # 调用TensorFlow原生算子 ac_z = custom_op_lib.add_custom(x, y) # 调用AscendC AddCustom自定义算子;add_custom是将REGISTER_OP(AddCustom)中的AddCustom由大驼峰命名转为下划线格式 config = tf.ConfigProto() custom_op = config.graph_options.rewrite_options.custom_optimizers.add() custom_op.name = "NpuOptimizer" # 配置在昇腾AI处理器上运行单算子 config.graph_options.rewrite_options.remapping = RewriterConfig.OFF config.graph_options.rewrite_options.memory_optimization = RewriterConfig.OFF with tf.Session(config=config) as sess: sess.run(tf.global_variables_initializer()) tf_golden = sess.run(tf_z, feed_dict={x: x_data, y: y_data}) with tf.Session(config=config) as sess: sess.run(tf.global_variables_initializer()) ascend_out = sess.run(ac_z, feed_dict={x: x_data, y: y_data}) np.array(tf_golden).astype(dtype_params) np.array(ascend_out).astype(dtype_params) print('====================================') # 通过np.allclose比较昇腾AI处理器上运行的实际结果和使用TensorFlow原生算子运行的期望结果,其中atol和rtol为np.allclose比较函数的相对公差参数和绝对公差参数。 cmp_result = np.allclose(tf_golden, ascend_out, atol, rtol) print(cmp_result) print('====================================') if __name__ == "__main__": tf.app.run() - TensorFlow 2.6.5调用代码
import os import tensorflow as tf import numpy as np import npu_device from npu_device.compat.v1.npu_init import * npu_device.compat.enable_v1() tf.compat.v1.enable_resource_variables() #np.allclose比较函数的相对公差参数 atol = 0.001 #np.allclose比较函数的绝对公差参数 rtol = 0.001 def main(unused_argv): custom_op_lib = tf.load_op_library('./outputs/libcustom_ops.so') # 加载so为python模块 shape_params = (8, 2048) dtype_params = np.float16 x_data = np.random.uniform(-2, 2, size=shape_params).astype(dtype_params) y_data = np.random.uniform(-2, 2, size=shape_params).astype(dtype_params) x = tf.compat.v1.placeholder(dtype_params, shape=shape_params) y = tf.compat.v1.placeholder(dtype_params, shape=shape_params) tf_z = tf.math.add(x, y) # 调用TensorFlow原生算子 ac_z = custom_op_lib.add_custom(x, y) # 调用AscendC AddCustom自定义算子;add_custom是将REGISTER_OP(AddCustom)中的AddCustom由大驼峰命名转为下划线格式 config = tf.compat.v1.ConfigProto() custom_op = config.graph_options.rewrite_options.custom_optimizers.add() custom_op.name = "NpuOptimizer" config.graph_options.rewrite_options.remapping = RewriterConfig.OFF config.graph_options.rewrite_options.memory_optimization = RewriterConfig.OFF with tf.compat.v1.Session(config=config) as sess: sess.run(tf.global_variables_initializer()) tf_golden = sess.run(tf_z, feed_dict={x: x_data, y: y_data}) with tf.compat.v1.Session(config=config) as sess: sess.run(tf.global_variables_initializer()) ascend_out = sess.run(ac_z, feed_dict={x: x_data, y: y_data}) np.array(tf_golden).astype(dtype_params) np.array(ascend_out).astype(dtype_params) print('====================================') # 通过np.allclose比较昇腾AI处理器上运行的实际结果和使用TensorFlow原生算子运行的期望结果,其中atol和rtol为np.allclose比较函数的相对公差参数和绝对公差参数。 cmp_result = np.allclose(tf_golden, ascend_out, atol, rtol) print(cmp_result) print('====================================') if __name__ == "__main__": tf.app.run()
- TensorFlow 1.15.0调用代码示例
可选输入算子映射关系开发
TensorFlow的原型定义中不支持可选输入,对于包含可选输入的算子,其从TensorFlow到CANN的映射关系,不满足简单的一对一映射,需要在插件适配代码中,将输入转换为可选输入,调整原型的映射关系。下文以CANN算子库中的FlashAttentionScore算子为例,介绍针对此类算子的框架适配插件如何开发。
- 适配插件开发和上文中介绍的简单的一对一映射不同,进行插件适配开发时,需要调用ParseOpToGraphFn注册回调函数,回调函数中用于调整算子原型映射关系。此时:
- 通过ParseParamsByOperatorFn注册回调函数,回调函数中将TensorFlow原生算子映射到一个IR和TensorFlow一致的中间算子(调用AutoMappingByOpFn完成属性映射)。
- 通过ParseOpToGraphFn注册回调函数,调整算子原型映射关系,将中间算子最终映射到CANN算子库中的算子,这里映射到Graph图的概念是指一个算子构成的单算子图。
需要注意:在ParseParamsByOperatorFn的回调函数中,需要将TensorFlow算子名称设置到中间算子的original_type属性中,用于后续ParseOpToGraphFn回调函数的触发。示例代码如下:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145
#include <string> #include <vector> #include "register/register.h" #include "graph/operator.h" #include "graph/graph.h" #include "graph/operator_factory.h" namespace domi { using namespace ge; static Status AddOptionalPlaceholderForFA(const ge::Operator &tf_op, ge::Graph &graph) { // 1. 创建一个FlashAttentionScore算子npu_fa_op ge::AscendString op_name; tf_op.GetName(op_name); auto npu_fa_op = OperatorFactory::CreateOperator(op_name.GetString(), "FlashAttentionScore"); // 2. 将TensorFlow算子属性映射到npu_fa_op算子上 float scale_value = 1.0; (void)tf_op.GetAttr("scale_value", scale_value); (void)npu_fa_op.SetAttr("scale_value", scale_value); float keep_prob = 1.0; (void)tf_op.GetAttr("keep_prob", keep_prob); (void)npu_fa_op.SetAttr("keep_prob", keep_prob); int32_t pre_tockens = 2147483647; (void)tf_op.GetAttr("pre_tockens", pre_tockens); (void)npu_fa_op.SetAttr("pre_tockens", pre_tockens); int32_t next_tockens = 2147483647; (void)tf_op.GetAttr("next_tockens", next_tockens); (void)npu_fa_op.SetAttr("next_tockens", next_tockens); int32_t head_num = 0; (void)tf_op.GetAttr("head_num", head_num); (void)npu_fa_op.SetAttr("head_num", head_num); std::string input_layout; (void)tf_op.GetAttr("input_layout", input_layout); (void)npu_fa_op.SetAttr("input_layout", input_layout); int32_t inner_precise = 0; (void)tf_op.GetAttr("inner_precise", inner_precise); (void)npu_fa_op.SetAttr("inner_precise", inner_precise); int32_t sparse_mode = 0; (void)tf_op.GetAttr("sparse_mode", sparse_mode); (void)npu_fa_op.SetAttr("sparse_mode", sparse_mode); int32_t pse_type = 1; (void)tf_op.GetAttr("pse_type", pse_type); (void)npu_fa_op.SetAttr("pse_type", pse_type); // 3. 创建输入Data std::vector<Operator> inputs; for (size_t i = 0UL; i < tf_op.GetInputsSize(); i++) { const std::string data_name = "Data_" + std::to_string(i); Operator data_op = OperatorFactory::CreateOperator(data_name.c_str(), "Data"); (void)data_op.SetAttr("index", static_cast<int32_t>(i)); inputs.emplace_back(data_op); } size_t index = 0UL; //4. 必选输入直接设置Data到算子输入 (void)npu_fa_op.SetInput("query", inputs[index++]); (void)npu_fa_op.SetInput("key", inputs[index++]); (void)npu_fa_op.SetInput("value", inputs[index++]); // 5. 可选输入需要判断type属性的个数是否为0,不为0则表示可选输入已经使能 std::vector<DataType> real_shift_type; (void)tf_op.GetAttr("real_shift_type", real_shift_type); if (!real_shift_type.empty()) { (void)npu_fa_op.SetInput("real_shift", inputs[index++]); } std::vector<DataType> drop_mask_type; (void)tf_op.GetAttr("drop_mask_type", drop_mask_type); if (!drop_mask_type.empty()) { (void)npu_fa_op.SetInput("drop_mask", inputs[index++]); } std::vector<DataType> padding_mask_type; (void)tf_op.GetAttr("padding_mask_type", padding_mask_type); if (!padding_mask_type.empty()) { (void)npu_fa_op.SetInput("padding_mask", inputs[index++]); } std::vector<DataType> atten_mask_type; (void)tf_op.GetAttr("atten_mask_type", atten_mask_type); if (!atten_mask_type.empty()) { (void)npu_fa_op.SetInput("atten_mask", inputs[index++]); } std::vector<DataType> prefix_type; (void)tf_op.GetAttr("prefix_type", prefix_type); if (!prefix_type.empty()) { (void)npu_fa_op.SetInput("prefix", inputs[index++]); } std::vector<DataType> actual_seq_qlen_type; (void)tf_op.GetAttr("actual_seq_qlen_type", actual_seq_qlen_type); if (!actual_seq_qlen_type.empty()) { (void)npu_fa_op.SetInput("actual_seq_qlen", inputs[index++]); } std::vector<DataType> actual_seq_kvlen_type; (void)tf_op.GetAttr("actual_seq_kvlen_type", actual_seq_kvlen_type); if (!actual_seq_kvlen_type.empty()) { (void)npu_fa_op.SetInput("actual_seq_kvlen", inputs[index++]); } std::vector<DataType> q_start_idx_type; (void)tf_op.GetAttr("q_start_idx_type", q_start_idx_type); if (!q_start_idx_type.empty()) { (void)npu_fa_op.SetInput("q_start_idx", inputs[index++]); } std::vector<DataType> kv_start_idx_type; (void)tf_op.GetAttr("kv_start_idx_type", kv_start_idx_type); if (!kv_start_idx_type.empty()) { (void)npu_fa_op.SetInput("kv_start_idx", inputs[index++]); } // 6. 使用npu_fa_op算子的输出构造图的输出。 std::vector<std::pair<Operator, std::vector<size_t>>> output_indexs; std::vector<size_t> node_output_index; for (size_t i = 0UL; i < npu_fa_op.GetOutputsSize(); i++) { node_output_index.emplace_back(i); } (void)output_indexs.emplace_back(std::make_pair(npu_fa_op, node_output_index)); (void)graph.SetInputs(inputs).SetOutputs(output_indexs); return SUCCESS; } static Status FlashAttentionScoreMapping(const ge::Operator& op_src, ge::Operator& op_dst) { // 1. 调用默认映射函数即可 if (AutoMappingByOpFn(op_src, op_dst) != ge::GRAPH_SUCCESS) { return FAILED; } // 2. 需要将TensorFlow算子名称设置到op_dst的original_type属性中,用于后续ParseOpToGraphFn回调函数的触发 op_dst.SetAttr("original_type", "FlashAttentionScore"); return SUCCESS; } REGISTER_CUSTOM_OP("FlashAttentionScore") .FrameworkType(TENSORFLOW) .OriginOpType({"FlashAttentionScore"}) .ParseParamsByOperatorFn(FlashAttentionScoreMapping) // 注册此函数用于实现算子本身属性的映射 .ParseOpToGraphFn(AddOptionalPlaceholderForFA); // 注册此函数用于实现将tf中的输入转化为可选输入,改变连边关系 } // namespace domi
- 在TensorFlow开源框架里注册FlashAttentionScore算子的原型定义,由于TensorFlow不支持可选输入,需要将其可选输入在TensorFlow原型中表示为动态输入,并通过属性来标记动态输入的个数,这些可选输入需要放置在原型定义的最后。示例代码(FlashAttentionScore.cc)如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65
#include <algorithm> #include <atomic> #include <map> #include "tensorflow/core/framework/common_shape_fns.h" #include "tensorflow/core/framework/op.h" #include "tensorflow/core/framework/op_kernel.h" using namespace tensorflow; using shape_inference::InferenceContext; using shape_inference::ShapeHandle; using namespace std; using namespace chrono; using OpKernelConstructionPtr = OpKernelConstruction*; using OpKernelContextPtr = OpKernelContext*; using InferenceContextPtr = ::tensorflow::shape_inference::InferenceContext*; namespace { class CustOps : public OpKernel { public: explicit CustOps(OpKernelConstructionPtr context) : OpKernel(context) {} void Compute(OpKernelContextPtr context) override { std::cout << "Cust Ops not installed!!" << std::endl; } ~CustOps() override = default;}; } // namespace namespace tensorflow { REGISTER_OP("FlashAttentionScore") .Input("query: T") .Input("key: T") .Input("value: T") .Input("real_shift: real_shift_type") // 可选输入在TensorFlow原型中注册为动态输入 .Input("drop_mask: drop_mask_type") .Input("padding_mask: padding_mask_type") .Input("atten_mask: atten_mask_type") .Input("prefix: prefix_type") .Input("actual_seq_qlen: actual_seq_qlen_type") .Input("actual_seq_kvlen: actual_seq_kvlen_type") .Input("q_start_idx: q_start_idx_type") .Input("kv_start_idx: kv_start_idx_type") .Output("softmax_max: float32") .Output("softmax_sum: float32") .Output("softmax_out: T") .Output("attention_out: T") .Attr("scale_value: float = 1.0") .Attr("keep_prob: float = 1.0") .Attr("pre_tockens: int = 2147483647") .Attr("next_tockens: int = 2147483647") .Attr("head_num: int") .Attr("input_layout: string") .Attr("inner_precise: int = 0") .Attr("sparse_mode: int = 0") .Attr("pse_type: int = 1") .Attr("T: {float16, float32, bfloat16} = DT_FLOAT") .Attr("real_shift_type: list({float16, float32, bfloat16}) >= 0") // 通过属性来标记动态输入个数 .Attr("drop_mask_type: list({uint8}) >= 0") .Attr("padding_mask_type: list({float16, float32, bfloat16}) >= 0") .Attr("atten_mask_type: list({bool, uint8}) >= 0") .Attr("prefix_type: list({int64}) >= 0") .Attr("actual_seq_qlen_type: list({int64}) >= 0") .Attr("actual_seq_kvlen_type: list({int64}) >= 0") .Attr("q_start_idx_type: list({int64}) >= 0") .Attr("kv_start_idx_type: list({int64}) >= 0") .SetShapeFn([](InferenceContext *c) { return Status::OK(); }); REGISTER_KERNEL_BUILDER(Name("FlashAttentionScore").Device(DEVICE_CPU), CustOps)}
使用如下命令对上述代码进行编译,产物为libcustom_ops.so,后续的算子调用脚本中可通过load_op_library接口加载该so为python模块,从而调用自定义算子。TF_CFLAGS=( $(python3 -c 'import tensorflow as tf; print(" ".join(tf.sysconfig.get_compile_flags()))') ) // 获取TensorFlow编译选项 TF_LFLAGS=( $(python3 -c 'import tensorflow as tf; print(" ".join(tf.sysconfig.get_link_flags()))') ) // 获取TensorFlow链接选项 SOURCE_FILES=FlashAttentionScore.cc // 包含TensorFlow算子注册和CPU内核实现的cc文件 g++ -std=c++14 -shared $SOURCE_FILES -o ${Path}/libflashattention.so -fPIC ${TF_CFLAGS[@]} ${TF_LFLAGS[@]} -O2 // 编译命令,产物为libflashattention.so,${Path}为自定义的路径,后续TensorFlow可通过load_op_library加载该so为python模块,调用自定义算子 - 封装一个TensorFlow的算子调用接口,在此接口中处理可选输入。在该脚本需要加载上一步骤编译好的动态库。
from tensorflow.python.framework import ops import tensorflow as tf tfOpLib = tf.load_op_library("../build/tf_ops/libflashattention.so") # 假如外部未使能该可选输入,则给底层传入空列表 def create_optional_input_list(input): input_list = [] if not input is None: input_list.append(input) return input_list # flash_attention_score 封装函数 def npu_flash_attention(query, key, value, head_num, input_layout, real_shift=None, drop_mask=None, padding_mask=None, atten_mask=None, prefix=None, actual_seq_qlen=None, actual_seq_kvlen=None, q_start_idx=None, kv_start_idx=None, scale_value=1.0, keep_prob=1.0, pre_tockens=2147483647, next_tockens=2147483647, inner_precise=0, sparse_mode=0, pse_type=1): output = tfOpLib.flash_attention_score(query=query, key=key, value=value, real_shift=create_optional_input_list(real_shift), drop_mask=create_optional_input_list(drop_mask), padding_mask=create_optional_input_list(padding_mask), atten_mask=create_optional_input_list(atten_mask), prefix=create_optional_input_list(prefix), actual_seq_qlen=create_optional_input_list(actual_seq_qlen), actual_seq_kvlen=create_optional_input_list(actual_seq_kvlen), q_start_idx=create_optional_input_list(q_start_idx), kv_start_idx=create_optional_input_list(kv_start_idx), scale_value=scale_value, keep_prob=keep_prob, pre_tockens=pre_tockens, next_tockens=next_tockens, head_num=head_num, input_layout=input_layout, inner_precise=inner_precise, sparse_mode=sparse_mode, pse_type=pse_type) return output - 测试脚本中实现自定义算子的调用。假设上一步骤中代码文件保存为ops.py,从ops中导入npu_flash_attention函数并使用。TensorFlow 2.6.5调用代码如下:
import sys from ops import npu_flash_attention import tensorflow as tf import numpy as np tf.compat.v1.disable_eager_execution() import npu_device from npu_device.compat.v1.npu_init import * npu_device.compat.enable_v1() def sess_config(): config = tf.compat.v1.ConfigProto() custom_op = config.graph_options.rewrite_options.custom_optimizers.add() custom_op.name = "NpuOptimizer" config.graph_options.rewrite_options.remapping = RewriterConfig.OFF config.graph_options.rewrite_options.memory_optimization = RewriterConfig.OFF return config shape = [1, 32, 32] query_np = np.random.randn(*shape).astype(np.float16) key_np = np.random.randn(*shape).astype(np.float16) value_np = np.random.randn(*shape).astype(np.float16) query = tf.Variable(query_np, tf.float16) key = tf.Variable(key_np, tf.float16) value = tf.Variable(value_np, tf.float16) mask = tf.zeros(shape=(shape[0], 1, shape[1], shape[1]), dtype=tf.uint8) head_num = 1 input_layout = "BSH" flash_result_t = npu_flash_attention(query, key, value, head_num, input_layout, atten_mask=mask) with tf.compat.v1.Session(config=sess_config()) as sess: sess.run(tf.compat.v1.global_variables_initializer()) flash_result = sess.run(flash_result_t) print(flash_result)
动态输入算子映射关系开发
对于存在动态输入/输出的算子,需要在插件的回调函数ParseParamByOpFunc中使用AutoMappingByOpFnDynamic实现TensorFlow算子和CANN算子的匹配。通过DynamicInputOutputInfo结构类描述动态输入/输出的信息,将动态输入/输出的名称和描述其个数的属性名绑定,再传入AutoMappingByOpFnDynamic实现自动匹配。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
#include "register/register.h" namespace domi { Status ParseSingleExampleMapping(const ge::Operator& op_src, ge::Operator& op) { std::vector<DynamicInputOutputInfo> value; const std::string dynamic_input_name_dense_defaults = "dense_defaults"; const std::string dynamic_input_attr_name_dense_defaults = "Tdense"; DynamicInputOutputInfo input(kInput, dynamic_input_name_dense_defaults.c_str(), dynamic_input_name_dense_defaults.size(), dynamic_input_attr_name_dense_defaults.c_str(), dynamic_input_attr_name_dense_defaults.size()); value.push_back(input); const std::string dynamic_output_name_sparse_indices = "sparse_indices"; const std::string dynamic_output_attr_name_sparse_indices = "num_sparse"; DynamicInputOutputInfo output(kOutput, dynamic_output_name_sparse_indices.c_str(), dynamic_output_name_sparse_indices.size(), dynamic_output_attr_name_sparse_indices.c_str(), dynamic_output_attr_name_sparse_indices.size()); value.push_back(output); const std::string dynamic_output_name_sparse_values = "sparse_values"; const std::string dynamic_output_attr_name_sparse_values = "sparse_types"; DynamicInputOutputInfo output1(kOutput, dynamic_output_name_sparse_values .c_str(), dynamic_output_name_sparse_values .size(), dynamic_output_attr_name_sparse_values.c_str(), dynamic_output_attr_name_sparse_values.size()); value.push_back(output1); const std::string dynamic_output_name_sparse_shapes = "sparse_shapes"; const std::string dynamic_output_attr_name_sparse_shapes = "sparse_types"; DynamicInputOutputInfo output1(kOutput, dynamic_output_name_sparse_shapes.c_str(), dynamic_output_name_sparse_shapes.size(), dynamic_output_attr_name_sparse_shapes.c_str(), dynamic_output_attr_name_sparse_shapes.size()); value.push_back(output2); const std::string dynamic_output_name_dense_values = "dense_values"; const std::string dynamic_output_attr_name_dense_values = "Tdense"; DynamicInputOutputInfo output1(kOutput, dynamic_output_name_dense_values .c_str(), dynamic_output_name_dense_values .size(), dynamic_output_attr_name_dense_values.c_str(), dynamic_output_attr_name_dense_values.size()); value.push_back(output3); AutoMappingByOpFnDynamic(op_src, op, value); return SUCCESS; } // register ParseSingleExample op to GE REGISTER_CUSTOM_OP("ParseSingleExample") .FrameworkType(TENSORFLOW) .OriginOpType("ParseSingleExample") .ParseParamsByOperatorFn(ParseSingleExampleMapping) } |

暂不支持同时有可选输入和动态输入的算子映射。