异构计算
使用Ascend C进行编程时,会涉及到在两个不同的平台(Host、Device)上开发代码。本章简单介绍Host、Device之间的差异,便于开发者宏观的了解这个异构系统;同时给出算子相关的数据流,结合异构架构的特点,开发者可以进一步了解应该如何合理安排算子代码的执行位置,便于得到更好的性能。
Host侧CPU和Device侧NPU的主要区别
如何合理安排算子代码
开发者进行Ascend C算子开发时,可以将Host和Device视为一个协同的异构系统,为每个处理单元分配其擅长的工作。在Host侧推荐执行非计算密集型任务,一般为标量计算任务。在Device侧推荐进行计算密集型任务,利用Device侧NPU的SIMD(Single Instruction Multiple Data)指令可以高效的实现批量数据的矩阵运算、向量运算等。
Ascend C算子的实现主要包含两个部分:
- Host侧Tiling实现
由于NPU中AI Core内部存储无法完全容纳算子输入输出的所有数据,需要每次搬运一部分输入数据进行计算然后搬出,再搬运下一部分输入数据进行计算,这个过程就称之为Tiling。切分数据的算法称为Tiling算法或者Tiling策略。根据算子的shape等信息来确定数据切分算法相关参数(比如每次搬运的块大小,循环的总次数)的计算程序,称之为Tiling实现,也叫Tiling函数(Tiling Function)。由于Tiling实现中均为标量计算,AI Core并不擅长,所以我们将其独立出来放在Host侧CPU上执行。
- Device侧Kernel实现
Kernel实现即算子核函数实现,在Kernel函数内部通过解析Host侧传入的Tiling结构体获取Tiling信息,根据Tiling信息控制数据搬入搬出Local Memory的流程;通过调用计算、数据搬运、内存管理、任务同步等API实现算子逻辑。其核心逻辑基本上都为计算密集型任务,适合在Device侧NPU上执行。
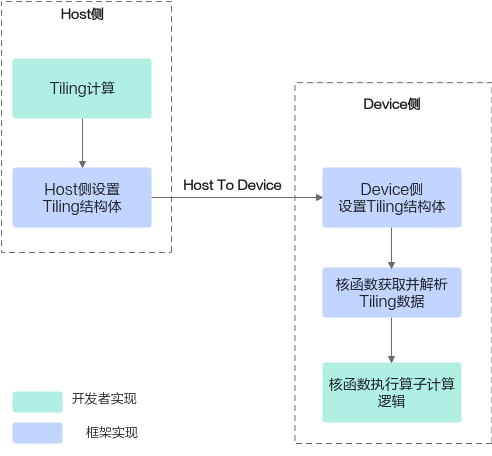
算子数据流
算子执行过程中涉及到Host和Device的数据交换。这里仅针对Tiling参数的传递,给出具体的数据流:Host侧Tiling算法根据算子具体输入输出的信息,完成Tiling参数的计算,并存放在Tiling结构体中;将Host侧的Tiling结构体发送到Device侧,Device侧的算子获取并解析Tiling结构体,基于该信息执行后续的算子计算逻辑。