ADA权重量化算法
在对神经网络进行量化时,主要方法是将每个浮点权重分配给其最接近的定点值。但这不是最佳的量化策略。本文引入的AdaRound(Adaptive Rounding),一种用于训练后量化的更好的权重舍入机制,它可以适应数据和任务损失,并且仅需要少量未标记的数据。
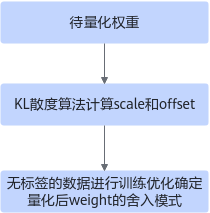
ADA权重量化算法用于PTQ流程,由于量化后的权重舍入模式会影响模型精度,ADA主要是对舍入模式进行微调,针对每个量化数据自适应向上或向下舍入模式,需要未标记的数据进行训练调优以确定不同的舍入模式。整体流程如下图所示,先将权重用KL散度算法计算Weight初始量化因子scale和offset,然后使用无标签的数据进行训练,调整weight的舍入模式。
量化后的weight计算公式如下:
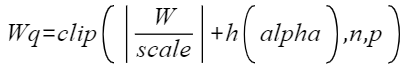 ,其中n和p分别是量化后的上下界。
,其中n和p分别是量化后的上下界。
训练过程主要是对alpha参数进行优化,目标是使得h(alpha)等于0或1:
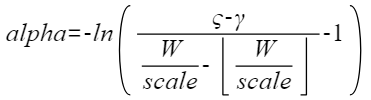 ,其中
,其中 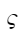 和
和 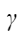 是伸缩参数,分别取值为1.1和-0.1。
是伸缩参数,分别取值为1.1和-0.1。
将原始weight量化,量化完成后加上h(alpha)将其反量化,将反量化的weight引入最后的算子计算中,最终输出带量化误差的结果:
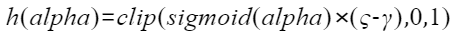
损失函数计算如下:
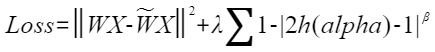
正则项(Loss函数的后半部分),用以约束h(alpha)向0和1两个值收敛,在迭代初期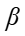 较大值可以使得正则项对整体损失的影响比重变大,就会促使优化过程快速调整 h(alpha),接近最优解的区域。迭代后期,此时h(alpha)已经处于最优解区域,使用较小
较大值可以使得正则项对整体损失的影响比重变大,就会促使优化过程快速调整 h(alpha),接近最优解的区域。迭代后期,此时h(alpha)已经处于最优解区域,使用较小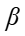 ,不会因为微小的参数变动导致正则项剧烈变化,从而让模型在微调参数时更加稳健,避免因过度调整而错过最优解,使h(alpha)逼近最优解。
,不会因为微小的参数变动导致正则项剧烈变化,从而让模型在微调参数时更加稳健,避免因过度调整而错过最优解,使h(alpha)逼近最优解。
父主题: 训练后量化算法