异步场景
Matmul的Iterate和IterateAll接口提供了同步和异步两种模式。
同步模式指的是程序执行时,需要等待某个操作完成后才能继续执行下一步操作。 异步模式指的是程序执行时,不需要等待某个操作完成就可以继续执行下一步操作。
Iterate&GetTensorC的同步和异步
- 同步:执行完一次Iterate迭代计算后,执行GetTensorC搬运矩阵C分片,搬运完成后,才能进行下一次计算。
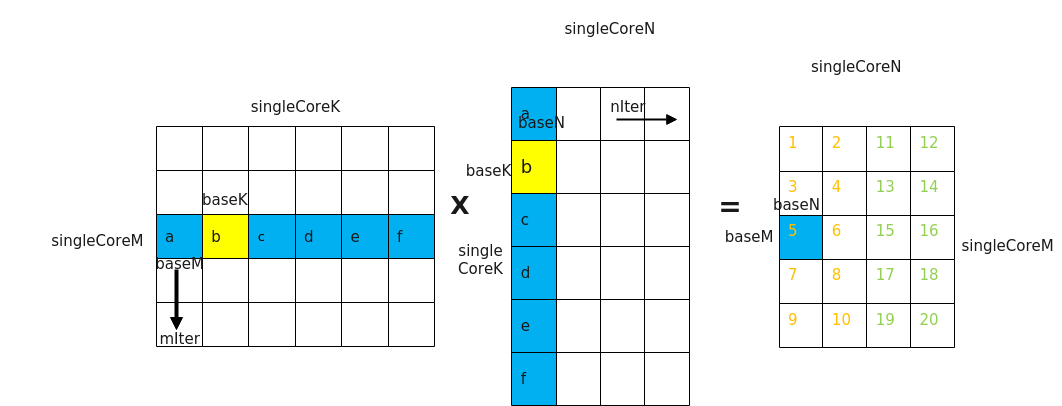
如下图所示,C矩阵中,矩阵块1搬走后,才能计算矩阵块2,阵块2搬运完成后,才能计算矩阵块3。
同步模式的样例代码如下
1 2 3
while (mm. Iterate ()) { mm. GetTensorC (gm_c); }
- 异步:通过设置模板参数开启异步模式。调用Iterate后,无需立即调用GetTensorC同步等待,可以先执行其他操作,待需要获取结果时再调用GetTensorC。异步方式可以减少同步等待,提高并行度,开发者对计算性能要求较高时,可以选用该方式。异步场景时,需要使用一块临时空间来缓存Iterate计算结果,否则会覆盖计算结果,调用GetTensorC时会在该临时空间中获取C的矩阵分片。临时空间通过SetWorkspace接口进行设置。SetWorkspace接口需要在Iterate接口之前调用。
1 2 3 4 5 6 7 8
mm.SetWorkspace(workspace, size); // 其中,workspace 为临时空间的物理地址,size为singleCoreM * singleCoreN大小的矩阵C占用的内存大小: singleCoreM * singleCoreN * sizeof(cDataType) // 异步模式 mm.template Iterate<false>(); …… // 执行其他操作 for (int i = 0; i < singleCoreM/baseM*singleCoreN/baseN; ++i) { mm.GetTensorC<false> (gm_c); }
IterateAll的同步和异步
- 同步:后续操作需要同步等待IterateAll执行结束
1 2 3 4 5 6
mm.SetTensorA(gm_a); // 设置左矩阵A mm.SetTensorB(gm_b); // 设置右矩阵B mm.SetBias(gm_bias); // 设置Bias mm.IterateAll(gm_c); // 后续操作 ...
- 异步:后续操作不需要同步等待IterateAll执行结束,需要IterateAll的结果时,调用WaitIterateAll等待IterateAll异步接口返回。
1 2 3 4 5 6 7 8 9
matmul::Matmul<aType, bType, cType, biasType> mm; mm.SetTensorA(queryGm[tensorACoreOffset]); mm.SetTensorB(keyGm[tensorBCoreOffset + sInnerStart * singleProcessSInnerSize * tilingData->attentionScoreOffestStrideParams.matmulHead], true); mm.SetTail(singleProcessSOuterSize, mmNNum); mm.template IterateAll<false>(workspaceGm[tmp_block_idx * mmResUbSize * sInnerLoopTimes],false,true); // do some others compute mm.WaitIterateAll(); // 等待IterateAll完成 DataCopy(dstUB, GM); // 进行GM到UB的拷贝
父主题: 矩阵编程(高阶API)