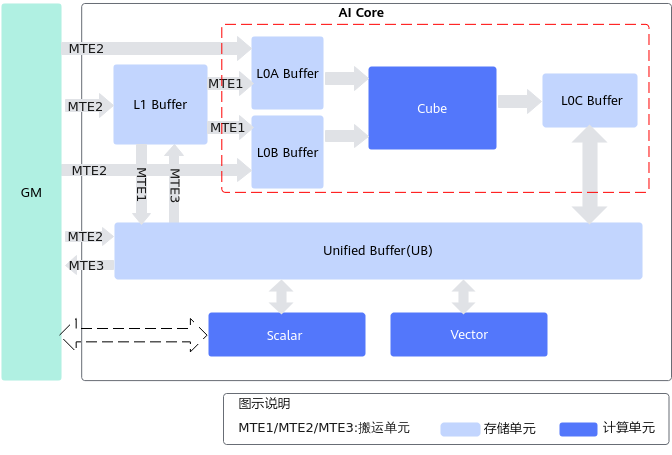
计算单元
计算单元是AI Core中提供强大算力的核心单元,包括三种基础计算单元:Cube(矩阵)计算单元、Vector(向量)计算单元和Scalar(标量)计算单元,完成AI Core中不同类型的数据计算。
Scalar
Scalar负责各类型的标量数据运算和程序的流程控制。功能上可以看做一个小CPU,完成整个程序的循环控制、分支判断、Cube/Vector等指令的地址和参数计算以及基本的算术运算,并且可以通过在事件同步模块中插入同步符的方式来控制AI Core中其他功能性单元的执行流水。相对于Host CPU,Scalar的计算能力较弱,重点用于发射指令,性能调优时尽量减少if/else及变量运算。
如下图所示:Scalar执行标量运算指令时,执行标准的ALU(Arithmetic Logic Unit)语句,ALU需要的代码段和数据段(栈空间)都来自于GM,ICache用于缓存代码段,缓存大小与硬件规格相关,比如为16K或32K,以2K为单位加载;DCache用于缓存数据段,大小也与硬件规格相关,比如为16K,以cacheline(64Byte)为单位加载。考虑到核内访问效率最高,应尽量保证代码段和数据段被缓存在ICache和DCache,避免核外访问; 同时根据数据加载单位不同,编程时可以考虑单次加载数据大小,来提升加载效率。例如在DCache加载数据时,当数据内存首地址与cacheline(64Byte)对齐时,加载效率最高。
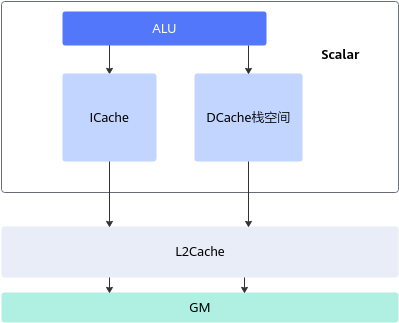

硬件提供L2Cache用于缓存访问GM的数据(包括代码段、数据段),以此加快访问速度,提高访问效率。核外L2Cache以cacheline为单位加载数据,根据硬件规格不同,cacheline大小不同(128/256/512Byte等)。
Vector
Vector负责执行向量运算。向量计算单元执行向量指令,类似于传统的单指令多数据(Single Instruction Multiple Data,SIMD)指令,每个向量指令可以完成多个操作数的同一类型运算。如下图所示,向量计算单元可以快速完成两个FP16类型的向量相加或者相乘。向量指令支持多次迭代执行,也支持对带有间隔的向量直接进行运算。
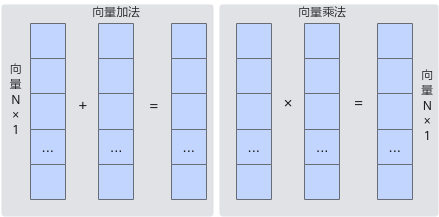
Vector所有计算的源数据以及目标数据都要求存储在Unified Buffer中,并要求首地址和操作长度都满足32Byte对齐。
Cube
Cube计算单元负责执行矩阵运算。Cube一次执行可以完成的A矩阵(M*K)与B矩阵(K*N)的矩阵乘。如下图所示红色虚线框划出了Cube计算单元及其访问的存储单元,其中左矩阵A来源于L0A,右矩阵B来源于L0B,L0C存储矩阵乘的结果和中间结果。