KV Cache量化
本节介绍什么是KV Cache、为什么要进行KV Cache量化,量化支持的层,并给出了KV Cache量化调用流程。
简介
KV Cache(Key-Value Cache)是一种缓存技术,通过存储键值对的形式来复用计算结果,以达到提高性能和降低内存消耗的目的。在大规模训练和推理中,随着batch_size和sequence_length的不断增长,KV Cache占用的内存开销也快速增大,甚至会超过模型本身;而对KV Cache进行INT8量化可以大幅度减少模型运行中的内存消耗,降低模型部署成本。
KV Cache量化支持的层:torch.nn.Linear,原始数据类型为float32和float16。KV Cache量化样例请参见样例列表。
该特性只有Atlas A2训练系列产品/Atlas 800I A2推理产品、Atlas 推理系列产品、Atlas A3 训练系列产品支持。
接口调用流程
KV Cache量化接口调用流程如图1所示。
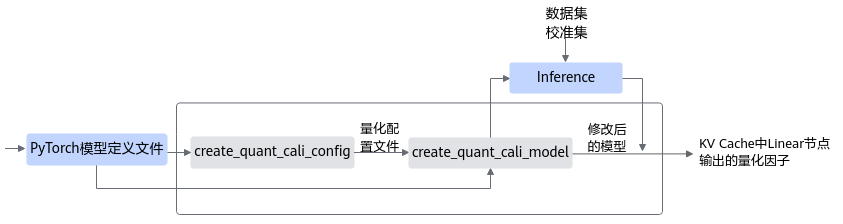
蓝色部分为用户实现,灰色部分为用户调用AMCT提供的API实现,简要流程如下:
- 用户首先构造PyTorch的原始模型,然后使用create_quant_cali_config生成量化配置文件。
- 根据PyTorch模型和量化配置文件,找到模型对应的待量化Lienar算子,即可调用create_quant_cali_model接口对原始PyTorch模型进行修改,在Linear输出后添加IFMR/HFMG量化算子。
- 使用校准集在PyTorch环境下执行前向推理,根据量化算法配置调用IFMR/HFMG量化算法对输出做校准,并将结果依据对应格式输出到量化因子文件中。
如果用户需要支持更多算子类型,或者用户自定义了其他操作,则可以使用QuantCalibrationOp接口,进行构图,然后进行量化校准,并输出量化因子文件。
调用示例

- 如下示例标有“由用户补充处理”的步骤,需要用户根据自己的模型和数据集进行补充处理,示例中仅为示例代码。
- 如下示例调用AMCT的部分,函数入参请根据实际情况进行调整。
- 导入AMCT包,并通过安装后处理>AMCT(PyTorch)中的环境变量设置日志级别。
1import amct_pytorch as amct
- (可选,由用户补充处理)在PyTorch原始环境中验证推理脚本及环境。
建议使用原始待量化的模型和测试集,在PyTorch环境下推理,验证环境、推理脚本是否正常。
推荐执行该步骤,请确保原始模型可以完成推理且精度正常;执行该步骤时,可以使用部分测试集,减少运行时间。
1user_do_inference_torch(ori_model, test_data, test_iterations)
- 调用AMCT,量化模型。
- 解析量化配置quant.cfg,生成量化配置文件。
1 2 3 4 5
config_file = './tmp/config.json' amct.create_quant_cali_config(config_file=config_file, model=ori_model, quant_layers=None, config_defination="./configs/quant.cfg")
- 修改图,在图插入量化相关的算子,用于计算量化相关参数。
- (由用户补充处理)基于PyTorch环境,使用修改后的模型(calibration_model)在校准集(calibration_data)上做模型推理,生成量化因子。
- 校准集及其预处理过程数据要与模型匹配,以保证量化的精度。
- 前向推理的次数为batch_num,如果次数不够,后续过程会失败。
校准过程中如果提示[IFMR]: Do layer xxx data calibration failed!错误信息,则请参见校准执行过程中提示“[IFMR]: Do layer xxx data calibration failed!”解决。
1user_do_inference_torch(calibration_model, calibration_data, batch_num)
- 输出量化因子文件。
- 解析量化配置quant.cfg,生成量化配置文件。
父主题: 扩展更多特性