matmul
函数原型
matmul(dst, a, b, m, k, n, init_l1out=True, bias=None)
参数说明
|
参数名称 |
输入/输出 |
含义 |
|---|---|---|
|
dst |
输出 |
矩阵相乘结果操作数的起始element, 支持的数据类型请参考表2,Tensor的scope为L1OUT。 结果张量格式:[N1, M, N0],N = N1 * N0
|
|
a |
输入 |
源操作数,左矩阵Tensor,支持的数据类型请参考表2, Tensor的scope为L1。 输入张量格式:[K1, M, K0], K = K1 * K0
|
|
b |
输入 |
源操作数,右矩阵Tensor,支持的数据类型请参考表2, Tensor的scope为L1。 输入张量格式:[K1, N, K0], K = K1 * K0
|
|
m |
输入 |
左矩阵有效Height,范围:[1, 4096],支持的数据类型为:立即数(int)。 注意:m可以不是16的倍数。 |
|
k |
输入 |
左矩阵有效Width、右矩阵有效Height,支持的数据类型为:立即数(int)。 当输入张量a的数据类型为float16时,范围:[1, 16384] 当输入张量a的数据类型为int8时,范围:[1, 32768] 注意:k可以不是16的倍数。 |
|
n |
输入 |
右矩阵有效Width,范围:[1, 4096],支持的数据类型为:立即数(int)。 注意:n可以不是16的倍数。 |
|
init_l1out |
输入 |
表示dst是否需要初始化。支持的数据类型为:bool类型。默认值为True。
|
|
bias |
输入 |
矩阵乘偏置,默认值为None,表示不添加偏置。 若使能偏置,输入bias为偏置操作数的起始 element,支持的数据类型为 Tensor(int32, float32),需与dst的数据类型保持一致,shape形状为[N,],N为输入b矩阵N方向大小;Tensor 的scope为L1。 注意: |
支持的型号
Atlas 200/300/500 推理产品
Atlas 训练系列产品
Atlas推理系列产品AI Core
Atlas A2训练系列产品/Atlas 800I A2推理产品
Atlas 200/500 A2推理产品
注意事项
- 单步调试时间比较长,不建议使用。
- 当操作数带有偏移时,如果使用tensor[imm]和tensor[scalar],表示只有一个元素。如果要表示从某一个位置开始,请使用tensor[imm:]和tensor[scalar:]方式。
- 该指令源操作数a和b首地址应满足512B对齐要求,例如采用tensor切片作为输入时,当源操作数为float16类型时,可使用tensor[256:],而tensor[2:]不满足对齐要求,可能产生未知错误。
- 目的操作数dst首地址应满足1024B对齐要求,例如采用tensor切片作为输入时,当目的操作数为int32类型时,可使用tensor[256:],而tensor[2:]不满足对齐要求,可能产生未知错误。
- 该接口不支持与vector相关指令一起使用。
- 参数m,k,n可以不是16对齐,但因硬件原因,操作数dst,a和b的shape需满足对齐要求,即m方向,n方向要求向上16对齐,k方向根据操作数数据类型按16或32向上对齐。
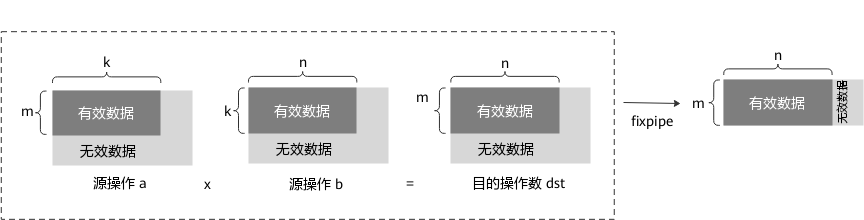
- 当n不是16的倍数时,dst中n维度上的无效数据需要用户自行处理;当m不是16的倍数时,dst中m维度上的无效数据可在fixpipe指令中删除。具体如下图所示,虚线框内为matmul接口实现效果;最右侧数据块为dst经过fixpipe接口处理后的输出结果:
- 该指令应与fixpipe指令配合使用。
- 操作数地址偏移对齐要求请见通用约束。
返回值
无
调用示例
- 示例:a和b的数据类型为int8,dst的数据类型为int32,且在fixpipe实现relu功能。
from tbe import tik tik_instance = tik.Tik() # 定义tensor a_gm = tik_instance.Tensor("int8", [2, 32, 32], name='a_gm', scope=tik.scope_gm) b_gm = tik_instance.Tensor("int8", [2, 160, 32], name='b_gm', scope=tik.scope_gm) # 由于matmul矩阵计算m=30,fixpipe会将dst_l1out中无效数据删除,因此dst_gm的shape在m方向上设置为30即可 dst_gm = tik_instance.Tensor("int32", [10, 30, 16], name='dst_gm', scope=tik.scope_gm) a_l1 = tik_instance.Tensor("int8", [2, 32, 32], name='a_l1', scope=tik.scope_cbuf) b_l1 = tik_instance.Tensor("int8", [2, 160, 32], name='b_l1', scope=tik.scope_cbuf) dst_l1out = tik_instance.Tensor("int32", [10, 32, 16], name='dst_l1out', scope=tik.scope_cbuf_out) # 将数据搬至源操作数 tik_instance.data_move(a_l1, a_gm, 0, 1, 64, 0, 0) tik_instance.data_move(b_l1, b_gm, 0, 1, 320, 0, 0) # 进行matmul操作,mkn分别为30,64,160,dst_l1out的shape在m维度向上16对齐取值至32 tik_instance.matmul(dst_l1out, a_l1, b_l1, 30, 64, 160) # 将数据搬移至dst_gm,其中burst_len = 30*16*dst_l1out_dtype_size//32 = 60 tik_instance.fixpipe(dst_gm, dst_l1out, 10, 60, 0, 0, extend_params={"relu": True}) tik_instance.BuildCCE(kernel_name="matmul", inputs=[a_gm, b_gm], outputs=[dst_gm])结果示例:
输入数据: a_l1 = [[[-1, -1, -1, ..., -1, -1, -1] ... [-1, -1, -1, ..., -1, -1, -1]] [[-1, -1, -1, ..., -1, -1, -1] ... [-1, -1, -1, ..., -1, -1, -1]]] b_l1 = [[[1, 1, 1, ..., 1, 1, 1] ... [1, 1, 1, ..., 1, 1, 1]] [[1, 1, 1, ..., 1, 1, 1] ... [1, 1, 1, ..., 1, 1, 1]]] 输出数据: dst_gm = [[[0, 0, 0, ..., 0, 0, 0] ... [0, 0, 0, ..., 0, 0, 0]] ... [[0, 0, 0, ..., 0, 0, 0] ... [0, 0, 0, ..., 0, 0, 0]]] - 示例:matmul接口的端到端调用示例,此示例中,输入a和b仅支持固定shape,且shape要求分别为 [16, 64]与[64, 1024]。调用示例请参见matmul样例。