使用说明
Ascend C提供一组Hccl高阶API,方便算子Kernel开发用户在AI Core侧灵活编排集合通信任务。
Hccl为集合通信任务客户端,主要对外提供了集合通信原语接口(以下统称为Prepare接口),对标集合通信C++接口,详细可参见HCCL接口参考,当前支持AllReduce、AllGather、ReduceScatter、AlltoAll接口等。本章的所有接口运行在AI Core上,且不执行通信任务,而是由用户调用Prepare接口将对应类型的通信任务信息发送给AI Cpu服务端,并在合适的时机通过Commit接口通知AI Cpu上的服务端执行对应的通信任务。
所谓合适的时机,取决于用户编排的是先通信后计算的任务,还是先计算后通信的任务。对于这两种场景,简述如下:
- 先通信后计算的任务:典型的如AllGather通信+MatMul计算任务编排。此场景下,用户在调用AllGather接口下发通信任务之后,通过AllGather接口返回的该通信任务标识handleId,可立即调用Commit接口通知服务端执行该handleId对应的任务,同时用户调用Wait阻塞接口等待服务端通知handleId对应的通信任务执行结束,待该通信任务结束后,再执行计算任务。
- 先计算后通信的任务:典型的如MatMul计算+AllReduce通信任务编排。此场景下,用户可以先调用AllReduce接口通知服务端先下发通信任务,再调用MatMul计算接口进行计算,这样AllReduce任务的组装和任务下发过程可以被MatMul的计算流水所掩盖,待计算任务完成后,调用Commit接口通知服务端执行AllReduce任务,无须调用Wait接口等待通信任务执行结束。
当后续无通信任务时,调用Finalize接口,通知服务端后续无通信任务,执行结束后退出,客户端检测并等待最后一个通信任务执行结束。以上介绍的AI Core下发Hccl通信任务的机制示意图如下图所示。
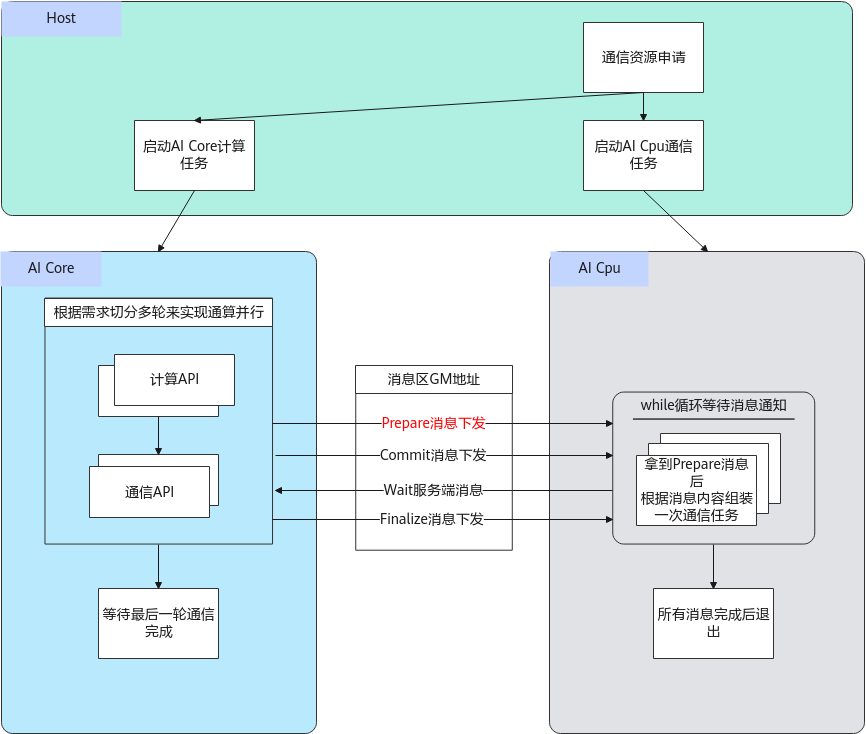
实现AI Core下发一个通信任务的具体步骤如下:
- 用户创建Hccl对象,并调用初始化接口。
1 2 3
Hccl<HCCL_SERVER_TYPE_AICPU> hccl; // 创建Hccl对象 GM_ADDR context = AscendC::GetHcclContext<HCCL_GROUP_ID_0>(); // 获取hccl上下文信息 hccl.Init(context); // hccl对象初始化
调用Init初始化接口时需要传入通信上下文信息,可以通过框架提供的获取通信上下文的接口GetHcclContext获取,该接口的函数原型如下;示例中HCCL_GROUP_ID_0为定义的全局变量,可参考表1。该接口返回的数据结构为HcclCombinOpParam,开发者也可以构造该数据结构作为Hccl对象初始化的信息传入,HcclCombinOpParam结构体说明参考表2。
1 2
template <uint32_t index> __aicore__ inline __gm__ uint8_t* __gm__ GetHcclContext(void)
表2 结构体HcclCombineOpParam说明 数据类型
说明
HcclCombineOpParam
Hccl通信上下文。
1 2 3 4 5 6 7 8 9 10
struct HcclCombineOpParam { uint64_t workSpace; // client和server之间通信的地址,hccl申请并清零 uint64_t workSpaceSize; // client和server之间通信的空间大小 uint32_t rankId; // 当前卡rankId uint32_t rankNum; // 所有卡的数量 uint64_t winSize; // 每个win大小 uint64_t windowsIn[HCCL_MAX_RANK_NUM]; // 作为输入的windows地址,rankID对应的为本卡地址,其他位置为跨卡映射地址 uint64_t windowsOut[HCCL_MAX_RANK_NUM]; // 作为输出的windows地址,rankID对应的为本卡地址,其他位置为跨卡映射地址 // 其他字段AI Cpu使用,对AI Core隐藏 }
- 用户通过对应的Prepare接口异步下发对应类型的通信任务,并获取到该任务的标识handleId,服务端接收到后开始通信任务的展开和下发,示例如下。
1 2 3 4 5 6 7 8
auto handleId = hccl.ReduceScatter<false>(aGM, cGM, recvCount, AscendC::HCCL_DATA_TYPE_FP16, HCCL_REDUCE_SUM, strideCount, 1); // 对于Prepare接口,在调试时可增加异常值校验和PRINTF打印 // if (handleId == INVALID_HANDLE_ID) { // PRINTF("[ERROR] call ReduceScatter failed, handleId is -1."); // return; // }
示例的Prepare接口为ReduceScatter,其他接口可参考后续章节的内容。其中的参数AscendC::HCCL_DATA_TYPE_FP16是Hccl任务的数据类型,其数据结构为HcclDataType,对应的参数说明参考表3;参数HCCL_REDUCE_SUM是一种Reduce操作,AllReduce和ReduceScatter规约操作支持的Reduce操作类型参见表4。
表3 HcclDataType参数说明 数据类型
说明
HcclDataType
Hccl任务的数据类型。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
enum HcclDataType { HCCL_DATA_TYPE_INT8 = 0, /* *< int8 */ HCCL_DATA_TYPE_INT16 = 1, /* *< int16 */ HCCL_DATA_TYPE_INT32 = 2, /* *< int32 */ HCCL_DATA_TYPE_FP16 = 3, /* *< fp16 */ HCCL_DATA_TYPE_FP32 = 4, /* *< fp32 */ HCCL_DATA_TYPE_INT64 = 5, /* *< int64 */ HCCL_DATA_TYPE_UINT64 = 6, /* *< uint64 */ HCCL_DATA_TYPE_UINT8 = 7, /* *< uint8 */ HCCL_DATA_TYPE_UINT16 = 8, /* *< uint16 */ HCCL_DATA_TYPE_UINT32 = 9, /* *< uint32 */ HCCL_DATA_TYPE_FP64 = 10, /* *< fp64 */ HCCL_DATA_TYPE_BFP16 = 11, /* *< bfp16 */ HCCL_DATA_TYPE_RESERVED /* *< reserved */ }
- 用户调用Commit接口通知服务端执行handleId对应的通信任务。
1 2
// 等待通信任务执行时机成熟,调用Commit接口通知服务端执行 hccl.Commit(handleId);
- 用户调用Wait阻塞接口,等待服务端执行完对应的通信任务。
1 2 3 4 5 6 7 8 9
auto ret = hccl.Wait(handleId); // 对于Wait和Query接口,在调试时可增加异常值校验和PRINTF打印 // if (ret == HCCL_FAILED) { // PRINTF("[ERROR] call Wait for handleId[%d] failed.", handleId); // return; // } // 调用核间同步接口,防止部分核执行较快退出,触发hccl析构,影响执行较慢的核 // 开发者可根据实际的业务场景,选择调用, , 接口,保证全部核的任务完成后再退出执行
- 用户调用Finalize接口,通知服务端后续无通信任务,执行结束后退出;客户端检测并等待最后一个通信任务执行结束。
1hccl.Finalzie();
注意:调用步骤2到步骤5的接口前,必须指定接口代码运行在AI Cube核或者AI Vector核上,实现时如下代码所示。
1 2 3 4 5 |
// 通过g_coreType来判断AI Cube核或者AI Vector核 if (g_coreType == AIV) { // if (g_coreType == AIC) { 调用Hccl接口 } |
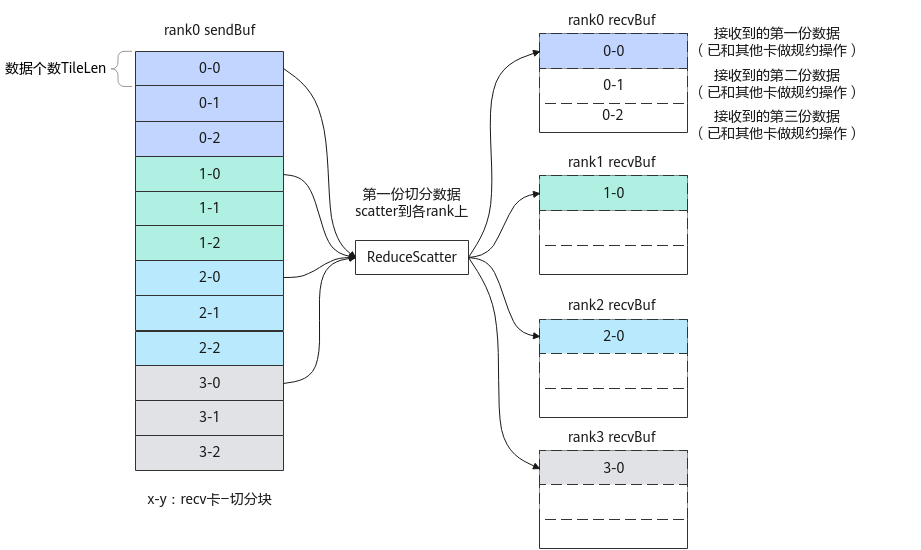
基于以上对单个通信任务下发的了解,介绍各Prepare接口中repeat参数的灵活使用方式。每个handleId对应的通信任务,其Commit接口和Wait接口的调用次数,与Prepare接口的repeat入参的值相等。以图2 ReduceScatter通信示例进行说明,假设共4张卡,每张卡上源数据首先按照rankId均匀分成4份,每份数据被切分成3份,最终被切分后的每份数据的个数为TiliLen,每次ReduceScatter通信仅通信一组切分数据(如图中数据0-0、1-0、2-0、3-0为一组切分数据),因此需要做3次ReduceScatter操作,全部数据才能通信完。
注意:数据的切分数量不要超过16块,否则会影响算子性能或者可能导致部分资源不足。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
const size_t rankSize = 4U; // 4张卡 const size_t tileCnt = 3U; // 卡上的数据按照rankId均匀分成rankSize份,且每份又被切分成3份 const size_t TileLen = 100U;// 被切分后的每份数据个数 // for循环中生成了3个handleId,每个handleId只调用了repeat=1次Commit和Wait接口 for (int i = 0; i < tileCnt; ++i) { auto handleId = ReduceScatter(sendBuf, recvBuf, TileLen, HCCL_DATA_TYPE_FP32 , HCCL_REDUCE_SUM, TileLen*tileCnt, repeat = 1); Commit(handleId); auto ret = Wait(handleId); // 执行其他计算逻辑 .... // 更新ReduceScatter的收发地址 sendBuf += TileLen * sizeof(float32); recvBuf += TileLen * sizeof(float32); } |
由于每张卡上3份数据的源地址SendBuf是连续的,且每张卡中目的地址recvBuf用来存储3份通信结果数据的内存也是连续的,因此以上代码可以优化,将ReduceScatter接口中的repeat参数设置为3,从而调用1次ReduceScatter接口,达到下发3个通信任务的效果。此时,只有1个handleId的任务,但是需要调用3次Commit和Wait接口,对应代码片段如下。
1 2 3 4 5 6 7 8 9 10 11 |
const size_t rankSize = 4U; // 4张卡 const size_t tileCnt = 3U; // 卡上的数据按照rankId均匀分成rankSize份,且每份又被切分成3份 const size_t TileLen = 100U;// 被切分后的每份数据个数 auto handleId = ReduceScatter(sendBuf, recvBuf, TileLen, HCCL_DATA_TYPE_FP32, HCCL_REDUCE_SUM, TileLen*tileCnt, repeat = tileCnt); for (int i = 0; i < tileCnt; ++i) { Commit(handleId); auto ret = Wait(handleId); // 执行其他计算逻辑 .... } |
|
数据类型 |
说明 |
||
|---|---|---|---|
|
MC2_BUFFER_LOCATION |
预留参数。计算和通信中间结果的Buffer存放位置。用户在Tiling侧可设置该字段。
|