TopK
功能说明
获取最后一个维度的前k个最大值或最小值及其对应的索引。
如果输入是向量,则在向量中找到前k个最大值或最小值及其对应的索引;如果输入是矩阵,则沿最后一个维度计算每行中前k个最大值或最小值及其对应的索引。本接口最多支持输入为二维数据,不支持更高维度的输入。
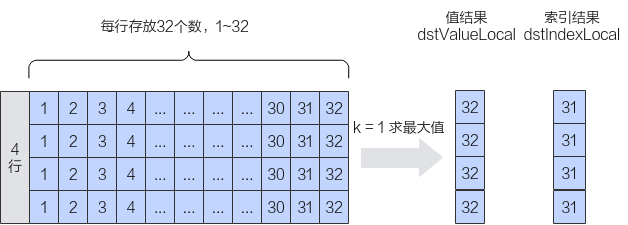
如下图所示,对shape为(4,32)的二维矩阵进行排序,k设置为1,输出结果为[[32] [32] [32] [32]]。
- 必备概念
基于如上样例,我们引入一些必备概念:行数称之为外轴长度(outter),每行实际的元素个数称之为内轴的实际长度(n)。本接口要求输入的内轴长度为32的整数倍,所以当n不是32的整数倍时,需要开发者将其向上补齐到32的整数倍,补齐后的长度称之为内轴长度(inner)。比如,如下的样例中,每行的实际长度n为31,不是32的整数倍,向上补齐后得到inner为32,图中的padding代表补齐操作。n和inner的关系如下:当n是32的整数倍时,inner=n;否则,inner > n。

- 接口模式
本接口支持两种模式:Normal模式和Small模式。Normal模式是通用模式;Small模式是为内轴长度固定为32(单位:元素个数)的场景提供的高性能模式。因为Small模式inner固定为32,可以进行更有针对性的处理,所以相关的约束较少,性能较高。内轴长度inner为32时建议使用Small模式。
- 附加功能:本接口支持开发者指定某些行的排序是无效排序。通过传入finishedLocal参数值来控制,finishedLocal对应行的值为true时,表示该行排序无效,此时排序后输出的dstIndexLocal的k个索引值会全部被置为无效索引n。

实现原理
以float类型,ND格式,shape为[outter, inner]的输入Tensor为例,描述TopK高阶API内部算法框图,如下图所示。
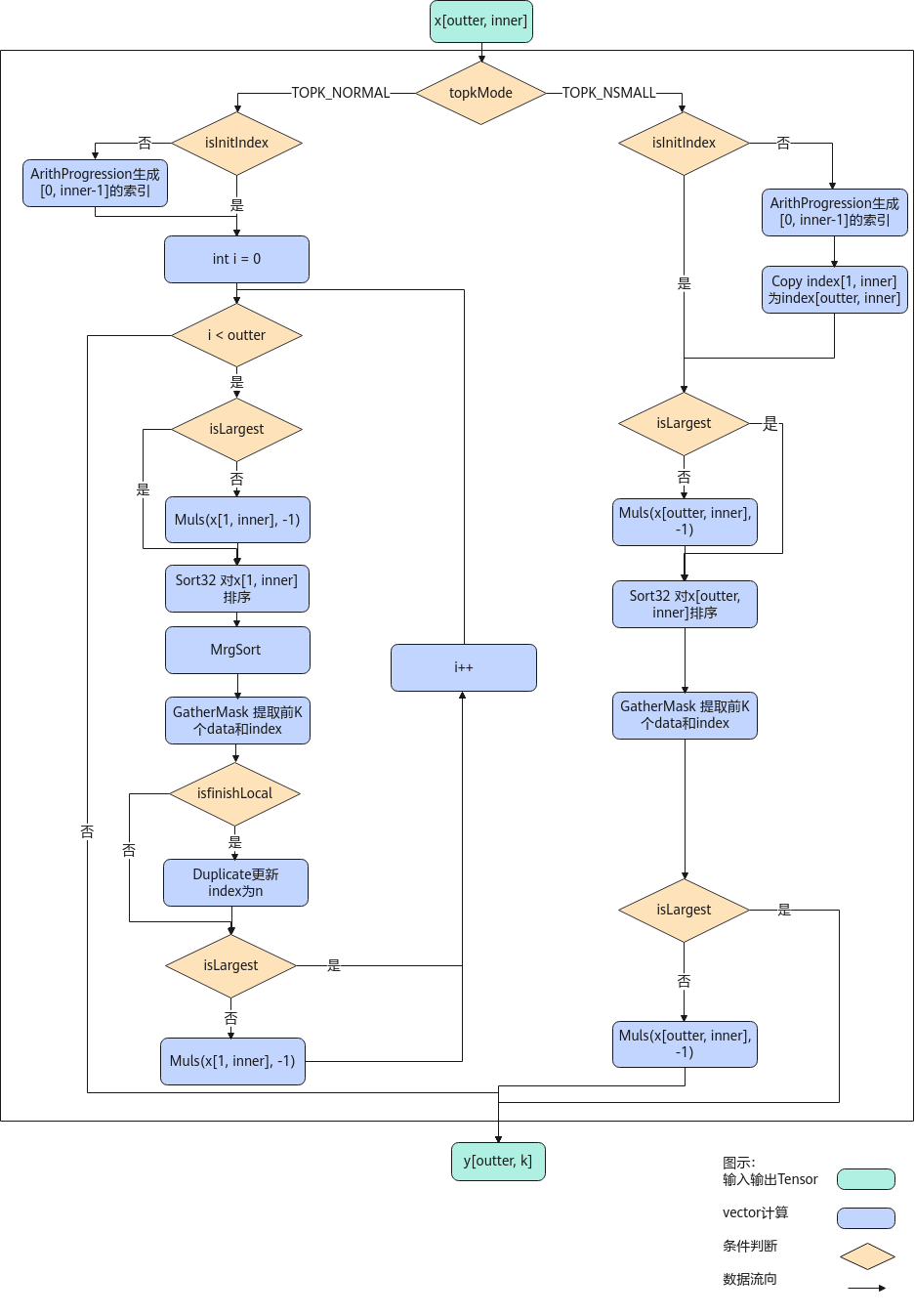
根据TopKMode不同的模式选择,可分为两个分支。
- 计算TopK NORMAL模式,过程如下:
- 模板参数isInitIndex为false,则使用ArithProgression生成0到inner - 1的索引;
- isLargest参数为false,由于Sort32指令默认为降序排序,则给数据乘以-1;
- 使用Sort32对数据排序,保证每32个数据是有序的;
- 使用MrgSort指令对所有的已排序数据块归并排序;
- 使用GatherMask指令提取前k个数据和索引;
- isfinishLocal为true,则更新所有索引为n;
- isLargest参数为false,则给数据乘以-1还原数据。
注意:Atlas 推理系列产品上使用ProposalConcat将data和index组合起来后,再使用RpSort16基础API对数据排序;使用MrgSort4进行归并;使用ProposalExtract基础API提取data和index。
- 计算TopK SMALL模式,过程如下:
- 模板参数isInitIndex为false,则使用ArithProgression生成0到inner - 1的索引值,并使用Copy指令将数据复制为outter条;
- isLargest参数为false,由于Sort32指令默认为降序排序,则给输入数据乘以-1;
- 使用Sort32对数据排序;
- 使用GatherMask指令提取前k个数据和索引;
- isLargest参数为false,则给输入数据乘以-1还原数据。
注意:Atlas 推理系列产品上使用ProposalConcat基础API将data和index组合起来后,再使用RpSort16基础API对数据排序;由于small模式下inner为32,RpSort16排序后为每16个数据有序,因此在步骤3和步骤4之间,使用MrgSort4基础API进行一次归并排序。
函数原型
- API内部申请临时空间
1 2
template <typename T, bool isInitIndex = false, bool isHasfinish = false, bool isReuseSrc = false, enum TopKMode topkMode = TopKMode::TOPK_NORMAL> __aicore__ inline void TopK(const LocalTensor<T> &dstValueLocal, const LocalTensor<int32_t> &dstIndexLocal, const LocalTensor<T> &srcLocal, const LocalTensor<int32_t> &srcIndexLocal, const LocalTensor<bool> &finishLocal, const int32_t k, const TopkTiling &tilling, const TopKInfo &topKInfo, const bool isLargest = true)
- 通过tmpLocal入参传入临时空间
1 2
template <typename T, bool isInitIndex = false, bool isHasfinish = false, bool isReuseSrc = false, enum TopKMode topkMode = TopKMode::TOPK_NORMAL> __aicore__ inline void TopK(const LocalTensor<T> &dstValueLocal, const LocalTensor<int32_t> &dstIndexLocal, const LocalTensor<T> &srcLocal, const LocalTensor<int32_t> &srcIndexLocal, const LocalTensor<bool> &finishLocal, const LocalTensor<uint8_t> &tmpLocal, const int32_t k, const TopkTiling &tilling, const TopKInfo &topKInfo, const bool isLargest = true)
由于该接口的内部实现中涉及复杂的逻辑计算,需要额外的临时空间来存储计算过程中的中间变量。临时空间支持API接口申请和开发者通过tmpLocal入参传入两种方式。
- API接口内部申请临时空间,开发者无需申请,但是需要预留临时空间的大小。
- 通过tmpLocal入参传入,使用该tensor作为临时空间进行处理,API接口内部不再申请。该方式开发者可以自行管理tmpLocal内存空间,并在接口调用完成后,复用该部分内存,内存不会反复申请释放,灵活性较高,内存利用率也较高。临时空间大小tmpLocal的BufferSize的获取方式如下:通过TopK Tiling中提供的GetTopKMaxMinTmpSize接口获取所需最大和最小临时空间大小。
参数说明
|
接口 |
功能 |
|---|---|
|
T |
待排序的数据类型: half/float |
|
isInitIndex |
是否传入输入数据的索引。
|
|
isHasfinish |
Topk接口支持开发者通过finishedLocal参数来指定某些行的排序是无效排序。该模板参数用于控制是否启用上述功能,true表示启用,false表示不启用。 Normal模式支持的取值:true / false Small模式支持的取值:false isHasfinish参数和finishedLocal的配套使用方法请参考表2中的finishedLocal参数说明。 |
|
isReuseSource |
是否允许修改源操作数。该参数预留,传入默认值false即可。 |
|
TopKMode |
Topk的模式选择,数据结构如下: enum class TopKMode {
TOPK_NORMAL, // Normal模式
TOPK_NSMALL, // Small模式
}; |
|
参数名 |
输入/输出 |
描述 |
|---|---|---|
|
dstValueLocal |
输出 |
目的操作数。用于保存排序出的k个值。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 目的操作数的数据类型需要与源操作数srcLocal的类型保持一致。 Atlas A2训练系列产品/Atlas 800I A2推理产品,支持的数据类型为:half/float Atlas推理系列产品AI Core,支持的数据类型为:half/float Normal模式:
Small模式:
|
|
dstIndexLocal |
输出 |
目的操作数。用于保存排序出的k个值对应的索引。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 Atlas A2训练系列产品/Atlas 800I A2推理产品,支持的数据类型为:int32_t Atlas推理系列产品AI Core,支持的数据类型为:half/float Normal模式:
Small模式:
|
|
srcLocal |
输入 |
源操作数。用于保存待排序的值。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 Atlas A2训练系列产品/Atlas 800I A2推理产品,支持的数据类型为:half/float
Atlas推理系列产品AI Core,支持的数据类型为:half/float
|
|
srcIndexLocal |
输入 |
源操作数。用于保存待排序的值对应的索引。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 Atlas A2训练系列产品/Atlas 800I A2推理产品,支持的数据类型为:int32_t Atlas推理系列产品AI Core,支持的数据类型为:half/float 该参数和模板参数isInitIndex配合使用,isInitIndex为false时,srcIndexLocal只需进行定义,不需要赋值,将定义后的srcIndexLocal传入接口即可;isInitIndex为true时,开发者需要通过srcIndexLocal参数传入索引值。srcIndexLocal参数设置的规则如下: Normal模式:
Small模式:
|
|
finishedLocal |
输入 |
源操作数。用于指定某些行的排序是无效排序,其shape为(outter, 1)。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 Atlas A2训练系列产品/Atlas 800I A2推理产品,支持的数据类型为:bool Atlas推理系列产品AI Core,支持的数据类型为:half/float 该参数和模板参数isHasfinish配合使用,Normal模式下支持isHasfinish配置为true/false,Small模式下仅支持isHasfinish配置为false。
|
|
tmpLocal |
输入 |
临时空间。接口内部复杂计算时用于存储中间变量,由开发者提供。数据类型固定uint8_t。 类型为LocalTensor,逻辑位置仅支持VECCALC,不支持其他逻辑位置。 临时空间大小BufferSize的获取方式请参考TopK Tiling。 |
|
k |
输入 |
获取前k个最大值或最小值及其对应的索引。数据类型为int32_t。 k的大小应该满足: 1 <= k <= n。 |
|
tiling |
输入 |
Topk计算所需Tiling信息,Tiling信息的获取请参考TopK Tiling。 |
|
topKInfo |
输入 |
srcLocal的shape信息。TopKInfo类型,具体定义如下: struct TopKInfo {
int32_t outter = 1; // 表示输入待排序数据的外轴长度
int32_t inner; // 表示输入待排序数据的内轴长度,inner必须是32的整数倍
int32_t n; // 表示输入待排序数据的内轴的实际长度
};
|
|
isLargest |
输入 |
类型为bool。取值为true时默认降序排列,获取前k个最大值;取值为false时进行升序排列,获取前k个最小值。 |
返回值
无
支持的型号
Atlas A2训练系列产品/Atlas 800I A2推理产品
Atlas推理系列产品AI Core
注意事项
- 操作数地址偏移对齐要求请参见通用约束。
- 不支持源操作数与目的操作数地址重叠。
- 当存在srcLocal[i]与srcLocal[j]相同时,如果i>j,则srcLocal[j]将首先被选出来,排在前面。
- inf在Topk中被认为是极大值。
- nan在topk中排序时无论是降序还是升序,均被排在前面。
- 对于Atlas推理系列产品AI Core:
- 输入srcLocal类型是half,模板参数isInitIndex值为false时,传入的topKInfo.inner不能大于2048。
- 输入srcLocal类型是half,模板参数isInitIndex值为true时,传入的srcIndexLocal中的索引值不能大于2048。
调用示例
本样例实现了Normal模式和Small模式的代码逻辑。样例代码如下:
template <typename T, bool isInitIndex = false, bool isHasfinish = false, bool isReuseSrc = false,
enum AscendC::TopKMode topkMode = AscendC::TopKMode::TOPK_NORMAL>
class KernelTopK {
public:
__aicore__ inline KernelTopK()
{}
__aicore__ inline void Init(GM_ADDR srcGmValue, GM_ADDR srcGmIndex, GM_ADDR finishGm, GM_ADDR dstGmValue,
GM_ADDR dstGmIndex, int32_t kGm, int32_t outter, int32_t inner, int32_t n, bool isLargestGm, uint32_t tmpsizeGm,
const TopkTiling &tilingData)
{
tiling = tilingData;
k = kGm;
tmpsize = tmpsizeGm;
// 计算输出值的padding,输出值的数据类型half/float。将其进行32Byte对齐
if (sizeof(T) == sizeof(float)) {
// 当输入的srcLocal和dstValueLocal的类型是float时,float是4字节,因此将k向上取整设置为8的倍数k_pad,即可满足32Byte对齐
k_pad = (k + 7) / 8 * 8;
} else {
// 当输入的srcLocal和dstValueLocal的类型是half时,half是2字节,因此将k向上取整设置为16的倍数k_pad,即可满足32Byte对齐
k_pad = (k + 15) / 16 * 16;
}
// 由于dstIndexLocal是int32_t类型,是4字节。因此将k向上取整设置为8的倍数kpad_index,即可满足32Byte对齐
kpad_index = (k + 7) / 8 * 8;
isLargest = isLargestGm;
topKInfo.outter = outter;
topKInfo.inner = inner;
topKInfo.n = n;
inDataSize = topKInfo.inner * topKInfo.outter;
// 为输出值和输出索引开辟内存大小,内存开辟都进行32Byte对齐。此处outValueDataSize和outIndexDataSize表示的是元素个数。
outValueDataSize = k_pad * topKInfo.outter;
outIndexDataSize = kpad_index * topKInfo.outter;
// Normal模式下,srcIndexLocal的大小为topKInfo.inner
inputdexDataSize = topKInfo.inner;
if (topkMode == AscendC::TopKMode::TOPK_NSMALL) {
// Small模式下,srcIndexLocal的内存大小需要为(topKInfo.inner * topKInfo.outter *
// sizeof(int32_t))Byte。此处inputdexDataSize值元素个数
inputdexDataSize = inDataSize;
}
finishLocalBytes = topKInfo.outter * sizeof(bool);
if (finishLocalBytes % 32 != 0) {
// 内存申请需要32bytes对齐
finishLocalBytes = (finishLocalBytes + 31) / 32 * 32;
}
srcGlobal1.SetGlobalBuffer(reinterpret_cast<__gm__ T *>(srcGmValue), inDataSize);
srcGlobal2.SetGlobalBuffer(reinterpret_cast<__gm__ int32_t *>(srcGmIndex), inputdexDataSize);
srcGlobal3.SetGlobalBuffer(reinterpret_cast<__gm__ bool *>(finishGm), finishLocalBytes / sizeof(bool));
dstGlobal1.SetGlobalBuffer(reinterpret_cast<__gm__ T *>(dstGmValue), outValueDataSize);
dstGlobal2.SetGlobalBuffer(reinterpret_cast<__gm__ int32_t *>(dstGmIndex), outIndexDataSize);
pipe.InitBuffer(inQueueX1, 1, inDataSize * sizeof(T));
pipe.InitBuffer(inQueueX2, 1, inputdexDataSize * sizeof(int32_t));
pipe.InitBuffer(inQueueX3, 1, finishLocalBytes);
pipe.InitBuffer(outQueueY1, 1, outValueDataSize * sizeof(T));
pipe.InitBuffer(outQueueY2, 1, outIndexDataSize * sizeof(int32_t));
if (tmpsize != 0) {
pipe.InitBuffer(tmpBuf, tmpsize);
}
}
__aicore__ inline void Process()
{
CopyIn();
Compute();
CopyOut();
}
private:
__aicore__ inline void CopyIn()
{
AscendC::LocalTensor<T> srcLocalValue = inQueueX1.AllocTensor<T>();
AscendC::LocalTensor<int32_t> srcLocalIndex = inQueueX2.AllocTensor<int32_t>();
AscendC::LocalTensor<bool> srcLocalFinish = inQueueX3.AllocTensor<bool>();
AscendC::DataCopy(srcLocalValue, srcGlobal1, inDataSize);
AscendC::DataCopy(srcLocalIndex, srcGlobal2, inputdexDataSize);
AscendC::DataCopy(srcLocalFinish, srcGlobal3, finishLocalBytes / sizeof(bool));
inQueueX1.EnQue(srcLocalValue);
inQueueX2.EnQue(srcLocalIndex);
inQueueX3.EnQue(srcLocalFinish);
}
__aicore__ inline void Compute()
{
AscendC::LocalTensor<T> dstLocalValue = outQueueY1.AllocTensor<T>();
AscendC::LocalTensor<int32_t> dstLocalIndex = outQueueY2.AllocTensor<int32_t>();
AscendC::LocalTensor<T> srcLocalValue = inQueueX1.DeQue<T>();
AscendC::LocalTensor<int32_t> srcLocalIndex = inQueueX2.DeQue<int32_t>();
AscendC::LocalTensor<bool> srcLocalFinish = inQueueX3.DeQue<bool>();
if (tmpsize == 0) {
AscendC::TopK<T, isInitIndex, isHasfinish, isReuseSrc, topkMode>(dstLocalValue,
dstLocalIndex,
srcLocalValue,
srcLocalIndex,
srcLocalFinish,
k,
tiling,
topKInfo,
isLargest);
} else {
AscendC::LocalTensor<uint8_t> tmpTensor = tmpBuf.Get<uint8_t>();
AscendC::TopK<T, isInitIndex, isHasfinish, isReuseSrc, topkMode>(dstLocalValue,
dstLocalIndex,
srcLocalValue,
srcLocalIndex,
srcLocalFinish,
tmpTensor,
k,
tiling,
topKInfo,
isLargest);
}
outQueueY1.EnQue<T>(dstLocalValue);
outQueueY2.EnQue<int32_t>(dstLocalIndex);
inQueueX1.FreeTensor(srcLocalValue);
inQueueX2.FreeTensor(srcLocalIndex);
inQueueX3.FreeTensor(srcLocalFinish);
}
__aicore__ inline void CopyOut()
{
AscendC::LocalTensor<T> dstLocalValue = outQueueY1.DeQue<T>();
AscendC::LocalTensor<int32_t> dstLocalIndex = outQueueY2.DeQue<int32_t>();
AscendC::DataCopy(dstGlobal1, dstLocalValue, outValueDataSize);
AscendC::DataCopy(dstGlobal2, dstLocalIndex, outIndexDataSize);
outQueueY1.FreeTensor(dstLocalValue);
outQueueY2.FreeTensor(dstLocalIndex);
}
private:
AscendC::GlobalTensor<T> srcGlobal1;
AscendC::GlobalTensor<int32_t> srcGlobal2;
AscendC::GlobalTensor<bool> srcGlobal3;
AscendC::GlobalTensor<T> dstGlobal1;
AscendC::GlobalTensor<int32_t> dstGlobal2;
AscendC::TPipe pipe;
AscendC::TQue<AscendC::QuePosition::VECIN, 1> inQueueX1;
AscendC::TQue<AscendC::QuePosition::VECIN, 1> inQueueX2;
AscendC::TQue<AscendC::QuePosition::VECIN, 1> inQueueX3;
AscendC::TQue<AscendC::QuePosition::VECOUT, 1> outQueueY1;
AscendC::TQue<AscendC::QuePosition::VECOUT, 1> outQueueY2;
AscendC::TBuf<AscendC::TPosition::VECCALC> tmpBuf;
uint32_t inDataSize = 0;
uint32_t inputdexDataSize = 0;
uint32_t inputdexBytes = 0;
uint32_t finishLocalBytes;
uint32_t outValueDataSize = 0;
uint32_t outIndexDataSize = 0;
int32_t k;
int32_t k_pad;
int32_t kpad_index;
bool isLargest = true;
uint32_t tmpsize;
AscendC::TopKInfo topKInfo;
TopkTiling tiling;
};
extern "C" __global__ __aicore__ void topk_custom(
GM_ADDR srcVal, GM_ADDR srcIdx, GM_ADDR finishLocal, GM_ADDR dstVal, GM_ADDR dstIdx, GM_ADDR tiling)
{
GET_TILING_DATA(tilingData, tiling);
KernelTopK<float, true, true, false, AscendC::TopKMode::TOPK_NORMAL> op;
op.Init(srcVal,
srcIdx,
finishLocal,
dstVal,
dstIdx,
tilingData.k,
tilingData.outter,
tilingData.inner,
tilingData.n,
tilingData.islargest,
tilingData.tmpsize,
tilingData.topkTilingData);
op.Process();
}
|
样例描述 |
本样例为对shape为(2,32)、数据类型为float的矩阵进行排序的示例,分别求取每行数据的前5个最小值。 使用Normal模式的接口,开发者自行传入输入数据索引,传入finishedLocal来指定某些行的排序是无效排序。 |
|---|---|
|
输入 |
|
|
输出数据 |
|
|
样例描述 |
本样例为对shape为(4,17)、类型为float的输入数据进行排序的示例,求取每行数据的前8个最大值。 使用Small模式的接口,开发者自行传入输入数据索引。 |
|---|---|
|
输入 |
|
|
输出数据 |
|