目标检测应用样例开发介绍(Python)
样例介绍
本文以MindX SDK来开发一个简单的目标检测应用,目标检测模型推理流程如图1 目标检测模型推理流程图所示。

本例中使用的是pytorch框架的yolov5模型。可以直接使用训练好的开源模型,也可以基于开源模型的源码进行修改、重新训练,还可以基于算法、框架构建适合的模型。
模型的输入数据与输出数据格式:
- 输入数据:RGB格式图片,分辨率为 640*640,输入形状为(1,3,640,640),即(batchsize,channel,height,width),对应每个batch的图片数量、图片的RGB维度、图片高度、图片宽度。
- 输出数据:目标检测框的坐标值、置信度、类别。
前期准备
- 获取代码文件。
单击获取链接或使用wget命令获取代码(使用wget时需确保开发者套件能够连接外网),下载代码文件压缩包,以root用户登录开发者套件。
wget https://ascend-repo.obs.cn-east-2.myhuaweicloud.com/Atlas%20200I%20DK%20A2/DevKit/models/sdk_cal_samples/yolo_sdk_python_sample.zip
- 将“yolo_sdk_python_sample.zip”压缩包上传到开发者套件,解压并进入目录。
unzip yolo_sdk_python_sample.zip cd yolo_sdk_python_sample
代码目录结构如下所示,按照正常开发流程,需要将框架模型文件转换成昇腾AI处理器支持推理的om格式模型文件,鉴于当前是入门内容,用户可直接获取已转换好的om模型进行推理。yolo_sdk_python_sample ├── main.py # 运行程序的脚本 ├── coco_names.txt # coco数据集所有类别名 ├── det_utils.py # 模型相关前后处理函数 ├── world_cup.jpg # 测试图片 ├── model │ ├── yolov5s_bs1.om # 已有om模型
代码解析
开发代码过程中,在“yolo_sdk_python_sample/main.py”文件中已包含读入数据、前处理、推理、后处理等功能,串联整个应用代码逻辑,此处仅对代码进行解析。
- 在“main.py”文件的开头有如下代码,用于导入需要的第三方库以及MindX SDK推理所需文件。
import cv2 # 图片处理三方库,用于对图片进行前后处理 import numpy as np # 用于对多维数组进行计算 import torch # 深度学习运算框架,此处主要用来处理数据 from mindx.sdk import Tensor # mxVision 中的 Tensor 数据结构 from mindx.sdk import base # mxVision 推理接口 from det_utils import get_labels_from_txt, letterbox, scale_coords, nms, draw_bbox # 模型前后处理相关函数
- 初始化资源、定义模型相关变量,如图片路径、模型路径、设备id等。
# 初始化资源和变量 base.mx_init() # 初始化 mxVision 资源 DEVICE_ID = 0 # 设备id model_path = 'model/yolov5s_bs1.om' # 模型路径 image_path = 'world_cup.jpg' # 测试图片路径
- 对输入数据进行前处理。先使用opencv读入图片,再进行相应的图片大小缩放填充、通道转换等处理,并将其转化为mindx sdk推理所需要的数据集格式(Tensor类)。
# 数据前处理 img_bgr = cv2.imread(image_path, cv2.IMREAD_COLOR) # 读入图片 img, scale_ratio, pad_size = letterbox(img_bgr, new_shape=[640, 640]) # 对图像进行缩放与填充,保持长宽比 img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, HWC to CHW,将形状转换为 channel first img = np.expand_dims(img, 0).astype(np.float32) # 得到(1, 3, 640, 640),即扩展第一维为 batchsize img = np.ascontiguousarray(img) / 255.0 # 转换为内存连续存储的数组 img = Tensor(img) # 将numpy转为转为Tensor类
- 使用MindX SDK接口进行模型推理,得到模型输出结果。
# 模型推理, 得到模型输出 model = base.model(modelPath=model_path, deviceId=DEVICE_ID) # 初始化 base.model 类 output = model.infer([img])[0] # 执行推理。输入数据类型:List[base.Tensor], 返回模型推理输出的 List[base.Tensor]
- 对模型输出进行后处理。将base.tensor类并转换为利于处理的numpy数组,再进行非极大值抑制、缩放图片、画出检测框等步骤(所涉及到的 nms、scale_coords及draw_bbox函数都可参见 det_utils.py ),得到最终可以用于显示的的目标检测结果,最后保存图片文件。
# 后处理 output.to_host() # 将Tensor数据转移到内存 output = np.array(output) # 将数据转为 numpy array 类型 boxout = nms(torch.tensor(output), conf_thres=0.4, iou_thres=0.5) # 利用非极大值抑制处理模型输出,conf_thres 为置信度阈值,iou_thres 为iou阈值 pred_all = boxout[0].numpy() # 转换为numpy数组 scale_coords([640, 640], pred_all[:, :4], img_bgr.shape, ratio_pad=(scale_ratio, pad_size)) # 将推理结果缩放到原始图片大小 labels_dict = get_labels_from_txt('./coco_names.txt') # 得到类别信息,返回序号与类别对应的字典 img_dw = draw_bbox(pred_all, img_bgr, (0, 255, 0), 2, labels_dict) # 画出检测框、类别、概率 # 保存图片到文件 cv2.imwrite('result.png', img_dw) print('save infer result success')
运行推理
- 配置环境变量。
- Ubuntu OS:
. /usr/local/Ascend/mxVision/set_env.sh
- openEuler OS:
. $HOME/Ascend/mxVision/set_env.sh
- Ubuntu OS:
- 运行主程序。
python main.py
命令行输出如下,表明运行成功:
save infer result success
推理完成后,在当前文件夹下生成“result.png”文件,如图2所示:
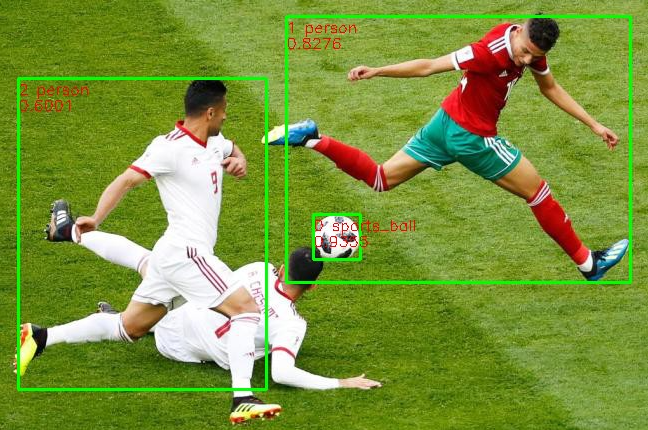
样例总结与扩展
以上代码包括以下几个步骤:
1. 前处理:对图片进行 缩放填充,维度转换、连续内存排列、以及转化为base.Tensor操作。
2. 推理:利用Model或者base.model 初始化模型,并用infer进行推理。
3. 后处理:用 非极大值抑制函数 处理模型输出结果,并将检测框坐标对应到原图上,再将结果画到原图上并保存。
MindX SDK接口分类总结:
分类 |
接口函数 |
描述 |
|---|---|---|
推理相关 |
base.model(model_path, device_id) |
初始化模型 |
model.infer([img]) |
通过输入Tensor列表进行模型推理 |
理解各个接口含义后,用户可进行灵活运用。除此外,此样例中只示范了图片推理,若需要对视频流数据进行推理,可用两种方式输入视频流数据:USB摄像头、手机摄像头。具体使用方式可参考《摄像头拉流》,用户只需将前处理、推理及后处理代码放入摄像头推理代码的循环中即可,注意有些细节地方需进行相应修改。
其中注释与图片读入和保存相关代码,并将前处理、推理及后处理代码加到了参考《摄像头拉流》所示的循环中。cv2.VideoCapture(url)这种读取方式会出现延迟高,掉帧多等现象,所以手动将帧率fps设置为5,用户也可根据实际情况设置fps。除此外,也可利用多线程来缓解此问题,由于本案例是入门案例,不再向外拓展。
下面以手机摄像头的rtsp拉流为例,改动后的代码如下:
# coding=utf-8
import cv2 # 图片处理三方库,用于对图片进行前后处理
import numpy as np # 用于对多维数组进行计算
import torch # 深度学习运算框架,此处主要用来处理数据
from mindx.sdk import Tensor # mxVision 中的 Tensor 数据结构
from mindx.sdk import base # mxVision 推理接口
from det_utils import get_labels_from_txt, letterbox, scale_coords, nms, draw_bbox # 模型前后处理相关函数
# 变量初始化
base.mx_init() # 初始化 mxVision 资源
DEVICE_ID = 0 # 设备id
model_path = 'model/yolov5s_bs1.om' # 模型路径
# image_path = 'world_cup.jpg' # 测试图片路径
# 利用手机ip摄像头
url = 'rtsp://admin:password@192.168.0.102:8554/live' # 这里需要替换为自己的链接
cap = cv2.VideoCapture(url)
# 获取保存视频相关变量
fps = 5 # 使用rtsp推流时,不能使用cap.get(cv2.CAP_PROP_FPS)来获取帧率,且由于延迟较高,手动指定帧率,可以根据实际情况调节
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
outfile = 'video_result.mp4'
video_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
video_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
writer = cv2.VideoWriter(outfile, fourcc, fps, (video_width, video_height))
try:
while(cap.isOpened()): # 在摄像头打开的情况下循环执行
ret, frame = cap.read() # 此处 frame 为 bgr 格式图片
# 数据前处理
# img_bgr = cv2.imread(image_path, cv2.IMREAD_COLOR) # 读入图片
# img, scale_ratio, pad_size = letterbox(img_bgr, new_shape=[640, 640]) # 对图像进行缩放与填充,保持长宽比
img, scale_ratio, pad_size = letterbox(frame, new_shape=[640, 640]) # 对图像进行缩放与填充,保持长宽比
img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, HWC to CHW
img = np.expand_dims(img, 0).astype(np.float32) # 将形状转换为 channel first (1, 3, 640, 640),即扩展第一维为 batchsize
img = np.ascontiguousarray(img) / 255.0 # 转换为内存连续存储的数组
img = Tensor(img) # 将numpy转为转为Tensor类
# 模型推理, 得到模型输出
model = base.model(modelPath=model_path, deviceId=DEVICE_ID) # 初始化 base.model 类
output = model.infer([img])[0] # 执行推理。输入数据类型:List[base.Tensor], 返回模型推理输出的 List[base.Tensor]
# 后处理
output.to_host() # 将 Tensor 数据转移到 Host 侧
output = np.array(output) # 将数据转为 numpy array 类型
boxout = nms(torch.tensor(output), conf_thres=0.4, iou_thres=0.5) # 利用非极大值抑制处理模型输出,conf_thres 为置信度阈值,iou_thres 为iou阈值
pred_all = boxout[0].numpy() # 转换为numpy数组
scale_coords([640, 640], pred_all[:, :4], frame.shape, ratio_pad=(scale_ratio, pad_size)) # 将推理结果缩放到原始图片大小
labels_dict = get_labels_from_txt('./coco_names.txt') # 得到类别信息,返回序号与类别对应的字典
img_dw = draw_bbox(pred_all, frame, (0, 255, 0), 2, labels_dict) # 画出检测框、类别、概率
# 将推理结果写入视频
writer.write(img_dw)
except KeyboardInterrupt:
cap.release()
writer.release()
finally:
cap.release()
writer.release()
# 保存图片到文件
print('save infer result success')