采集&解析性能数据
本节介绍推理场景下使用msprof命令行方式采集和解析性能数据、并通过生成的结果文件分析性能瓶颈的基本方法,关于msprof命令行的详细参数介绍、以及其它性能数据采集分析方式请参见《性能分析工具使用指南》。
采集、解析并导出性能数据
- 执行msprof命令一键式采集、解析并导出性能数据。
msprof --application=/home/HwHiAiUser/HIAI_PROJECTS/MyAppname/out/main --output=/home/HwHiAiUser/profiling_output
表1 常用参数说明 参数
描述
可选/必选
--application
配置为运行环境上AI任务文件。
不建议配置其他用户目录下的AI任务,避免提权风险。
不建议使用此参数进行有安全风险的高危操作,如删除文件或目录、修改密码、提权命令等。
必选
--output
收集到的Profiling数据的存放路径,默认为AI任务文件所在目录。
可选
默认情况下,导出迭代数最多的模型ID(Model ID)对应的第一轮迭代的性能数据。
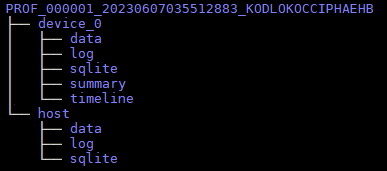
- 命令执行完成后,在output指定的目录下生成PROF_XXX目录,存放采集并解析后的性能数据,目录结构如图1所示。
- data/sqlite文件夹为采集和解析的过程数据,一般无需关注。
- log文件夹为日志文件,一般无需关注。
- summary文件夹汇总了AI任务运行时的软硬件数据。
- timeline文件夹汇总了AI任务运行的时序信息。
- 进入summary和timeline目录,查看性能数据文件。
默认情况下采集到的文件请参考表2。
表2 msprof默认配置采集的性能数据文件 文件夹
文件名
说明
timeline
msprof*.json
timeline数据总表。
acl_*.json
AscendCL接口调用时序。训练场景不生成。
ai_stack_time_*.json
昇腾AI软件栈各组件(AscendCL,GE,Runtime,Task Scheduler等)运行时序。
ge_*.json
GE接口耗时数据。
step_trace_*.json
迭代轨迹数据,每轮迭代的耗时。
task_time_*.json
Task Scheduler任务调度时序。
thread_group_*.json
AscendCL,GE,Runtime组件耗时数据。
ge_op_execute_*.json
算子下发各阶段耗时数据。当模型为动态Shape时自动采集并生成该文件。
summary
acl_*.csv
AscendCL API调用过程。训练场景不生成。
acl_statistic_*.csv
AscendCL API数据统计。训练场景不生成。
op_summary_*.csv
AI Core和AI CPU算子数据。
op_statistic _*.csv
AI Core和AI CPU算子调用次数及耗时统计。
step_trace_*.csv
迭代轨迹数据。
task_time_*.csv
Task Scheduler任务调度信息。
ai_stack_time_*.csv
昇腾AI软件栈各组件(AscendCL,GE,Runtime,Task Scheduler等)信息。
fusion_op_*.csv
模型中算子融合前后信息。
ge_op_execute_*.csv
算子下发各阶段耗时数据。当模型为动态Shape时自动采集并生成该文件。
prof_rule_0.json
调优建议。
注:“*”表示{device_id}_{model_id}_{iter_id},其中{device_id}表示设备ID,{model_id}表示模型ID,{iter_id}表示某轮迭代的ID。


性能分析
从上文我们可以看到,性能数据文件较多,分析方法也较灵活,以下介绍几个重要文件及分析方法。
- 通过msprof*.json文件从整体角度查看AI任务运行的时序信息,进而分析出可能存在的瓶颈点。
图4 msprof*.json文件示例
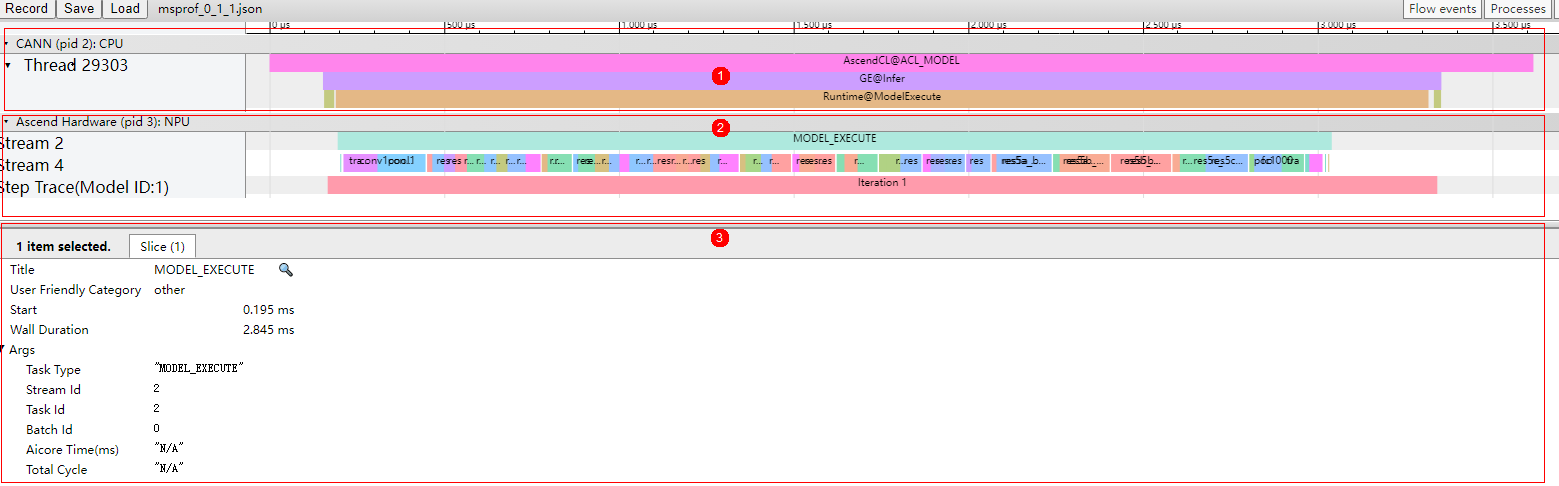
- 区域1:CANN层数据,主要包含AscendCL、GE和Runtime组件的耗时数据。
- 区域2:底层NPU数据,主要包含Task Schduler组件耗时数据、迭代轨迹数据。
- 区域3:展示timeline中各算子、接口的详细信息,单击区域1和区域2中各timeline时展示。
从上图可以大致分析出AI任务在哪个阶段耗时较多,比如发现区域1的AscendCL aclmdlExecute接口执行阶段耗时较多,可以继续查看区域2的Task Schduler任务调度信息,分析执行推理过程中具体耗时较长的任务,查看区域3的耗时较长的接口和算子,再结合summary文件进行量化分析,定位出具体的性能瓶颈。
- 通过op_statistic_*.csv文件分析各类算子的调用总时间、总次数等,排查是否某类算子总耗时较长,进而分析这类算子是否有优化空间。
图5 op_statistic_*.csv文件示例
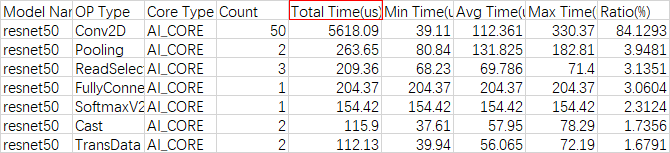
可以按照Total Time排序,找出哪类算子耗时较长。
- 通过op_summary_*.csv文件分析具体某个算子的信息和耗时情况,从而找出高耗时算子,进而分析该算子是否有优化空间。
图6 op_summary*.csv文件示例
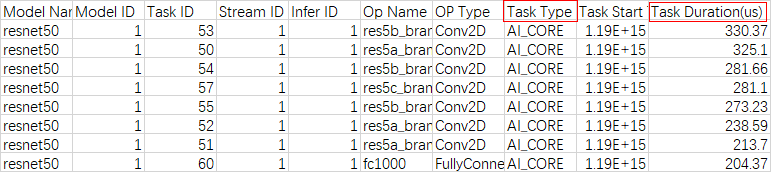
Task Duration字段为算子耗时信息,可以按照Task Duration排序,找出高耗时算子;也可以按照Task Type排序,查看不同核(AI Core和AI CPU)上运行的高耗时算子。