任务说明
根据亲和性策略,对通过节点预选的所有节点打分,并由调度器选择最终的节点。
例如Pod任务需要1个昇腾AI处理器,现在有满足任务的两个节点A和B,其中节点A的某一个HCCL环剩余1个昇腾AI处理器,节点B两个环分别剩余2个和3个昇腾AI处理器,根据亲和性策略,节点A会获得更高的分数。
具体实现
具体代码实现请参考开源代码中ScoreBestNPUNodes方法,其中getNodeBestScore方法实现了根据亲和性确定节点优先级。在选择节点时,优先检测是否配置了交换机亲和性调度和逻辑超节点亲和性调度。既没有配置交换机亲和性调度,又没有逻辑超节点亲和性调度,则使用普通节点优选原则。
普通节点优选原则
使用二维数组表示节点对任务的契合度,如affScoreList[i][j],i表示任务的1个Pod所需的芯片数量减1,j表示节点当前可用的芯片数量减1,affScoreList[i][j]取值表示该节点的不契合程度。
例如任务的1个Pod所需的芯片数量为6,此时可用芯片数为1~5的节点为完全不满足调度需求的节点,因此不契合程度就设置成最高的8。可用芯片数为6的节点刚好满足调度需求,且不会产生资源碎片,不契合程度就设置成最低的0。对于可用芯片数为7、8的节点,考虑到尽量减少资源碎片,因此他们的不契合程度分别为1,2。因此可推出:
affScoreList[5] = []int{8,8,8,8,8,0,1,2}
同理可得
affScoreList[3] = []int{8,8,8,0,1,2,3,4}
部分产品的总芯片数量不一致,或者存在HCCS环等情况,该二维数组存在微调,但是总体逻辑都一致。
交换机亲和性调度节点优化原则
集群调度组件通过basic-tor配置文件,获取整个集群的节点与交换机的对应关系;通过Ascend Device Plugin组件上报的芯片使用信息,获取所有的Spine网络空闲交换机下的节点资源。Spine网络空闲交换机,即交换机下没有任务,或者只有不使用Spine网络的填充任务的交换机。
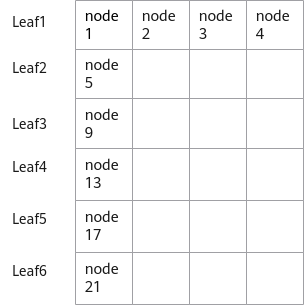
将空闲交换机资源分成两个二维数组,一个按照Leaf交换机下连接的节点横向划分;一个按照节点在Leaf交换机所处的相对位置竖向划分(不同Leaf交换机下不同位置的节点可以组成一个网络亲和的逻辑交换机)。两个二维数组都按照剩余节点从大到小的顺序排序。划分二维数组的方式说明如下:
- 划分方式1:按照Leaf交换机下的节点划分,如[node1,node2,node3,node4]一组。
- 划分方式2:按照Leaf交换机下的相对位置划分,如[node1,node5,node9,node13,node17,node21]一组。
任务类型 |
任务说明 |
节点优化原则 |
|---|---|---|
填充任务 |
该任务只能下发在一个交换机下 |
从二维数组的末尾开始选取出第一个满足任务部署的交换机,如果遍历完二维数组还不存在,则任务等待。 |
大模型任务 |
该任务可以跨多个交换机,且一定满足交换机亲和性 |
从二维数组的开头选取完整的交换机资源,如果资源足够,则调度成功;如果资源不足。分为以下两种情况。
|
普通任务 |
该任务尽量满足交换机亲和性,资源不足时,允许随机该任务 |
普通任务前部分的调度逻辑与大模型任务一致,只是在最终凑逻辑交换机资源仍然不足时,允许随机使用剩余节点。 |
逻辑超节点亲和性调度
- 根据任务的逻辑超节点大小,将剩余超节点分布成两个队列。队列1是大于或等于逻辑超节点+备用节点数的超节点;队列2是大于或等于逻辑超节点大小,小于逻辑超节点+备用节点数大小的超节点。
- 优先使用队列1的数据,将队列1拆分成一个三维数组。以逻辑超节点大小为18,所需逻辑超节点个数为2,预留节点数为2为例。首先按照超节点可用节点数,将其放入一个二维数组中,每个二维数组中,放置的是相同节点数的多个超节点,因此整体是一个三维数组。此时超节点选取的先后顺序如图2所示,即优先使用可用节点数为18的超节点,不满足的话,就按照超节点可用节点18、26、19、27,一直到33的顺序,查找可用超节点。如果还找不到,后续需要按照超节点可用节点数34、35、36、37.....46、47、48的顺序优选超节点。
- 若资源仍然不足,则使用队列2的资源,队列2按照剩余节点数从大到小排序,超节点选择从第一个数据开始往后选择。