



昇腾MindSpeed MM支持全模态大模型分布式训练
发表于: 2025/06/26
2025年3月底通义系列首个端到端全模态大模型通义千问Qwen2.5-Omni-7B开源发布,可同时处理文本、图像、音频和视频等多种输入,并实时生成文本与自然语音合成输出。在权威的多模态融合任务OmniBench等测评中,Qwen2.5-Omni刷新业界纪录,全维度远超业界Gemini-1.5-Pro等同类模型。其音频、文本、视觉多个模态编码及Thinker-Talker双核架构需超大规模集群高效训练支撑。MindSpeed MM多模态训练框架开发团队快速对Qwen2.5-Omni模型系列进行适配,全面支持Qwen2.5-Omni超大规模训练。通过全模态异构Omni PP切分、全模态异构TP切分,实现文本、图像、视频等多模态数据的高效并行处理,为开发者提供高效易用的全模态开发体验。
Qwen2.5-Omni全模态模型结构特点及训练挑战
Qwen2.5-Omni全模态模型采用的是Thinker-Talker架构,Thinker主要负责处理视觉、音频、文本等多种模态的输入,生成中间表示和相应的文本,Talker负责接收来自Thinker的高级表示和文本tokens,生成离散的语音tokens。模型的数据处理涉及多个感知模块,包含视觉、音频、文本,将输入视频中的视觉token和音频token通过置编码和文本指令交织到一起,放入Thinker主干网络中进行多模态理解和文本生成,通过Talker进行语音的生成。
相比传统的多模态VLM模型,全模态模型的模态编码器和适配层更多。针对全模态的数据,如音频、视频、图像等,数据量更大,针对不同视频分辨率或者不同的音频采样率,全模态模型的的多编码器和主干LLM在不同任务上的计算负载存在显著差异。计算负载的差异在多卡集群计算时带来快卡和慢卡不均衡的挑战,进而约束模型训练性能。
基于MindSpeed MM的Qwen2.5-Omni全模态效果体验
输入视频(包含音频):
输入Prompt:
['<|im_start|>system\nYou are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech.请用中文文字和语音回答一切问题\nuser\n\nassistant\n']
输出文本:
这是一只熊猫,它正坐在木制的平台上,用爪子拿着一根竹子,看起来像是在吃竹子呢。熊猫的黑白毛色很可爱,背景是绿色的树木,环境看起来很自然。你要是还有关于熊猫或者其他的问题,都可以跟我说哦。
输出音频:
从输出结果来看,输出的音频流畅,和输出文本也一致。
昇腾MindSpeed MM全模态异构PP、TP自定义切分使让训练效率提升20%
针对全模态结构的特点和挑战,MindSpeed MM采取了全模态异构PP切分和全模态异构TP切分的关键特性进行优化,将不同模态在不同的卡上进行自定义切分使得训练效率更高。
支持全模态异构PP切分
相比于传统的多模态模型,Qwen2.5Omni模型包括音频模块、视觉模块、连接层以及语言主干网络,其中音频模块和视觉模块的激活值比较大,在前向计算时耗时较长,当视频或音频较长时会导致显存占用过大甚至OOM,同时影响多卡之间的负载均衡。
MindSpeed MM创新性地实现了Omni异构全模态流水线并行特性,包括视觉模块vit、音频模块audio、和语言模块LLM主干网络的流水线并行适配,在支撑实现更复杂场景和更大数据规模的训练微调的同时,时也缓解了负载不均衡的问题,有效的避免了快慢卡问题。基于全模态异构PP的最优切分下,性能相比默认配置提升20%以上。
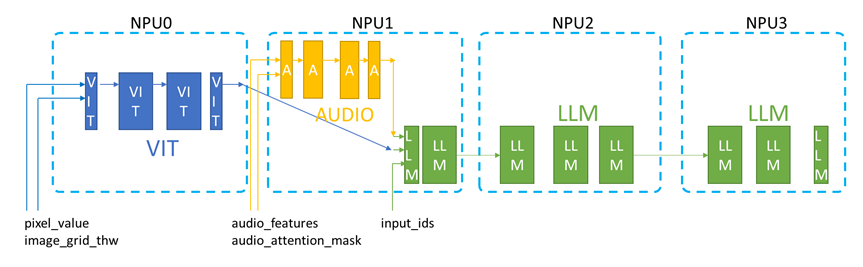
全模态异构数据PP并行切分示意图
全模态异构PP流水线切分配置方式:以下配置为本实践举例数据集的最优配置,仅供参考,用户可以根据实际场景下数据的大小,调整到最优内存使用
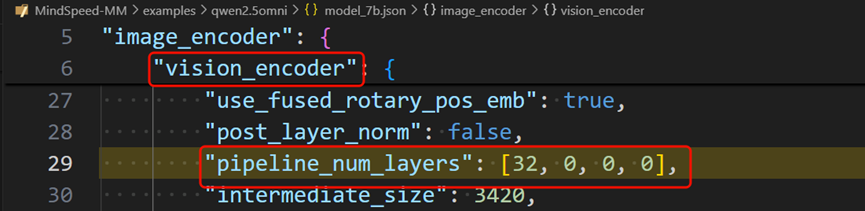
视觉编码器vision_encoder的PP切分配置[32,0,0,0],即总共四张卡,第一个卡上切32层,其他卡上不放。
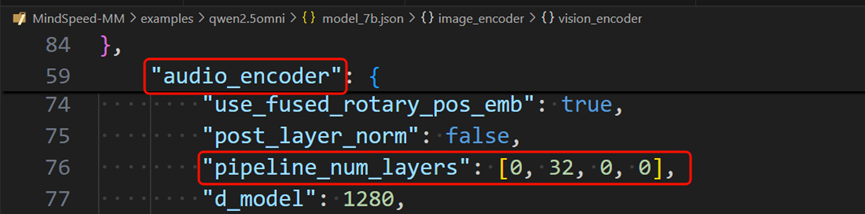
音频编码器audio_encoder的PP切分配置[0,32,0,0],即总共四张卡,第一个卡上不放,第二张卡上切32层,第三、四卡上不放。
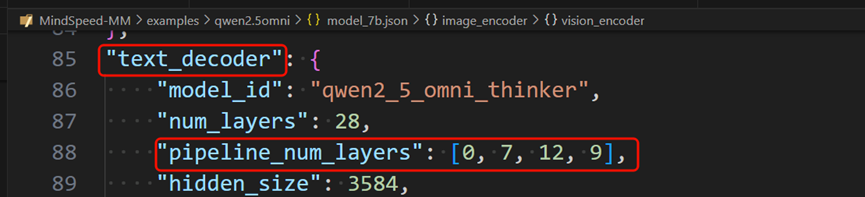
文本解码器text_decoder的PP切分配置[0,7,12,9],即总共四张卡,第一个卡上不放,第二张卡上切7层,第三张卡上切12层,第四张卡上切9层。
支持全模态异构TP切分
针对传统的LLM和多模态模型,可以对模型进行高效的MindSpeed的TP(张量并行)切分,但在全模态模型中,音频模块不会对QKV矩阵的K层做偏差项,导致无法直接使用TP切分。MindSpeed MM通过HOOK方案对QKV矩阵的K层进行初始化和梯度重置,在不改动底层逻辑的情况下支持全模态模型的TP并行切分。
全模态异构PP流水线切分配置方式:在入口脚本中配置tensor-model-parallel-size参数即可使能TP张量并行
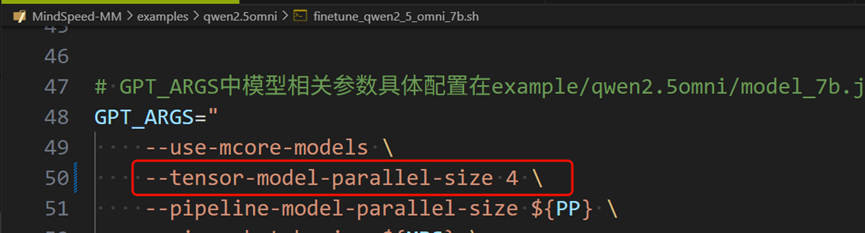
快速上手:基于MindSpeed MM玩转Qwen2.5Omni训练
环境安装
模型开发时推荐使用配套的环境版本,详见仓库中的”环境安装”
https://gitcode.com/Ascend/MindSpeed-MM/blob/2.2.0/examples/qwen2.5omni/README.md
权重下载及转换
1. 权重下载
从Huggingface库下载对应的模型权重:
模型地址: Qwen2.5-Omni-7B https://gitee.com/link?target=https%3A%2F%2Fhuggingface.co%2FQwen%2FQwen2.5-Omni-7B%2Ftree%2Fmain
将下载的模型权重保存到本地的ckpt/hf_path/Qwen2.5-Omni-7B目录下。
2. 权重转换(hf2mm)
MindSpeed-MM修改了部分原始网络的结构名称,使用mm-convert工具对原始预训练权重进行转换。该工具实现了huggingface权重和MindSpeed-MM权重的互相转换以及PP(Pipeline Parallel)权重的重切分。参考权重转换工具
# 7b
mm-convert Qwen2_5_OmniConverter hf_to_mm \
--cfg.mm_dir "ckpt/mm_path/Qwen2.5-Omni-7B" \
--cfg.hf_config.hf_dir "ckpt/hf_path/Qwen2.5-Omni-7B" \
--cfg.parallel_config.llm_pp_layers [[0,7,12,9]] \
--cfg.parallel_config.vit_pp_layers [[32,0,0,0]] \
--cfg.parallel_config.audio_pp_layers [[0,32,0,0]] \
--cfg.parallel_config.tp_size 1
# 其中:
# mm_dir: 转换后保存目录
# hf_dir: huggingface权重目录
# llm_pp_layers: llm在每个卡上切分的层数,注意要和model.json中配置的pipeline_num_layers一致
# vit_pp_layers: vit在每个卡上切分的层数,注意要和model.json中配置的pipeline_num_layers一致
# audio_pp_layers: audio在每个卡上切分的层数,注意要和model.json中配置的pipeline_num_layers一致
# tp_size: tp并行数量,注意要和微调启动脚本中的配置一致
如果需要用转换后模型训练的话,同步修改examples/qwen2.5omni/finetune_qwen2_5_omni_7b.sh中的LOAD_PATH参数,该路径为转换后或者切分后的权重,注意与原始权重 ckpt/hf_path/Qwen2.5-Omni-7B进行区分。
LOAD_PATH="ckpt/mm_path/Qwen2.5-Omni-7B"数据集准备及处理
1. 数据集下载(以coco2017数据集为例)
(1)用户需要自行下载COCO2017数据集COCO2017,并解压到项目目录下的./data/COCO2017文件夹中
(2)获取图片数据集的描述文件(LLaVA-Instruct-150K),下载至./data/路径下;
(3)运行数据转换脚本
python examples/qwen2vl/llava_instruct_2_mllm_demo_format.py;$playground
├── data
├── COCO2017
├── train2017
├── llava_instruct_150k.json
├── mllm_format_llava_instruct_data.json
...
当前支持读取多个以,(注意不要加空格)分隔的数据集,配置方式为data.json中 dataset_param->basic_parameters->dataset 从"./data/mllm_format_llava_instruct_data.json"修改为"./data/mllm_format_llava_instruct_data.json,./data/mllm_format_llava_instruct_data2.json"
同时注意data.json中dataset_param->basic_parameters->max_samples的配置,会限制数据只读max_samples条,这样可以快速验证功能。如果正式训练时,可以把该参数去掉则读取全部的数据。
2.纯文本或有图无图混合训练数据(以LLaVA-Instruct-150K为例)
现在本框架已经支持纯文本/混合数据(有图像和无图像数据混合训练)。
在数据构造时,对于包含图片的数据,需要保留image这个键值。
{
"id": your_id,
"image": your_image_path,
"conversations": [
{"from": "human", "value": your_query},
{"from": "gpt", "value": your_response},
],
}
在数据构造时,对于纯文本数据,可以去除image这个键值。
{
"id": your_id,
"conversations": [
{"from": "human", "value": your_query},
{"from": "gpt", "value": your_response},
],
}
3.视频音频数据集
1)加载视频数据集
数据集中的视频数据集取自llamafactory,https://github.com/hiyouga/LLaMA-Factory/tree/main/data
视频取自mllm_video_demo,使用时需要将该数据放到自己的data文件夹中去,同时将llamafactory上的mllm_video_audio_demo.json也放到自己的data文件中
之后根据实际情况修改 data.json 中的数据集路径,包括 model_name_or_path 、 dataset_dir 、 dataset 字段,并修改"attr"中 images 、 videos 字段,修改结果参考下图。
{
"dataset_param": {
"dataset_type": "huggingface",
"preprocess_parameters": {
"model_name_or_path": "./Qwen2.5-Omni-7B",
...
},
"basic_parameters": {
...
"dataset_dir": "./data",
"dataset": "./data/mllm_video_audio_demo.json",
"cache_dir": "./data/cache_dir",
...
},
...
"attr": {
"system": null,
"images": null,
"videos": "videos",
"audios": "audios",
...
},
},
...
}
2)修改模型配置
在model_xxx.json中,修改img_context_token_id为下图所示:
"img_context_token_id": 151656注意, image_token_id 和 img_context_token_id两个参数作用不一样。前者是固定的,是标识图片的 token ID,在qwen2_5_omni_get_rope_index中用于计算图文输入情况下序列中的图片数量。后者是标识视觉内容的 token ID,用于在forward中标记视觉token的位置,所以需要根据输入做相应修改。
微调
1. 准备工作
配置脚本前需要完成前置准备工作,包括:环境安装、权重下载及转换、数据集准备及处理,详情可查看对应章节。
2. 配置参数
【数据目录配置】
根据实际情况修改data.json中的数据集路径,包括model_name_or_path、dataset_dir、dataset等字段。
以Qwen2.5Omni-7B为例,data.json进行以下修改,注意model_name_or_path的权重路径为转换前的权重路径。
注意cache_dir在多机上不要配置同一个挂载目录避免写入同一个文件导致冲突。
{
"dataset_param": {
"dataset_type": "huggingface",
"preprocess_parameters": {
"model_name_or_path": "./ckpt/hf_path/Qwen2.5-Omni-7B",
...
},
"basic_parameters": {
...
"dataset_dir": "./data",
"dataset": "./data/mllm_format_llava_instruct_data.json",
"cache_dir": "./data/cache_dir",
...
},
...
},
...
}
【模型保存加载及日志信息配置】
根据实际情况配置examples/qwen2.5omni/finetune_qwen2_5_omni_7b.sh的参数,包括加载、保存路径以及保存间隔--save-interval(注意:分布式优化器保存文件较大耗时较长,请谨慎设置保存间隔)
...
# 加载路径
LOAD_PATH="ckpt/mm_path/Qwen2.5-Omni-7B"
# 保存路径
SAVE_PATH="save_dir"
...
GPT_ARGS="
...
--no-load-optim \ # 不加载优化器状态,若需加载请移除
--no-load-rng \ # 不加载随机数状态,若需加载请移除
--no-save-optim \ # 不保存优化器状态,若需保存请移除
--no-save-rng \ # 不保存随机数状态,若需保存请移除
...
"
...
OUTPUT_ARGS="
--log-interval 1 \ # 日志间隔
--save-interval 5000 \ # 保存间隔
...
--log-tps \ # 增加此参数可使能在训练中打印每步语言模块的平均序列长度,并在训练结束后计算每秒吞吐tokens量。
"
若需要加载指定迭代次数的权重、优化器等状态,需将加载路径LOAD_PATH设置为保存文件夹路径LOAD_PATH="save_dir",并修改latest_checkpointed_iteration.txt文件内容为指定迭代次数 (此功能coming soon)
$save_dir
├── latest_checkpointed_iteration.txt
├── ...
【单机运行配置】
配置examples/qwen2.5omni/finetune_qwen2_5_omni_7b.sh参数如下
# 根据实际情况修改 ascend-toolkit 路径
source /usr/local/Ascend/ascend-toolkit/set_env.sh
NPUS_PER_NODE=8
MASTER_ADDR=localhost
MASTER_PORT=29501
NNODES=1
NODE_RANK=0
WORLD_SIZE=$(($NPUS_PER_NODE * $NNODES))
注意,当开启PP时,model.json中配置的vision_encoder和text_decoder的pipeline_num_layer参数控制了各自的PP切分策略。对于流水线并行,要先处理vision_encoder再处理text_decoder。 比如7b默认的值[32,0,0,0]、[1,10,10,7],其含义为PP域内第一张卡先放32层vision_encoder再放1层text_decoder、第二张卡放text_decoder接着的10层、第三张卡放text_decoder接着的10层、第四张卡放text_decoder接着的7层,vision_encoder没有放完时不能先放text_decoder(比如[30,2,0,0]、[1,10,10,7]的配置是错的)
同时注意,如果某张卡上的参数全部冻结时会导致没有梯度(比如vision_encoder冻结时PP配置[30,2,0,0]、[0,11,10,7]),需要在finetune_qwen2_5_omni_7b.sh中GPT_ARGS参数中增加--enable-dummy-optimizer,参考dummy_optimizer特性文档。
3. 启动微调
以Qwen2.5Omni-7B为例,启动微调训练任务。
bash examples/qwen2.5omni/finetune_qwen2_5_omni_7b.sh4. 训练过程
训练过程loss如下图:
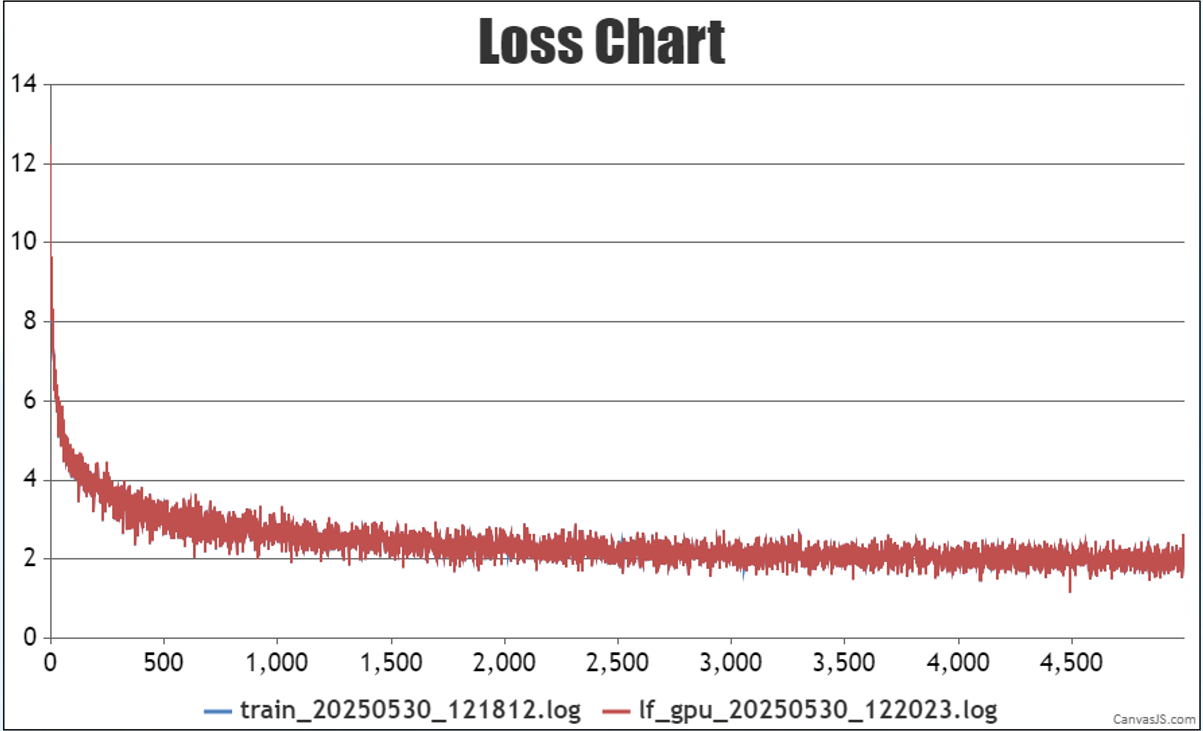
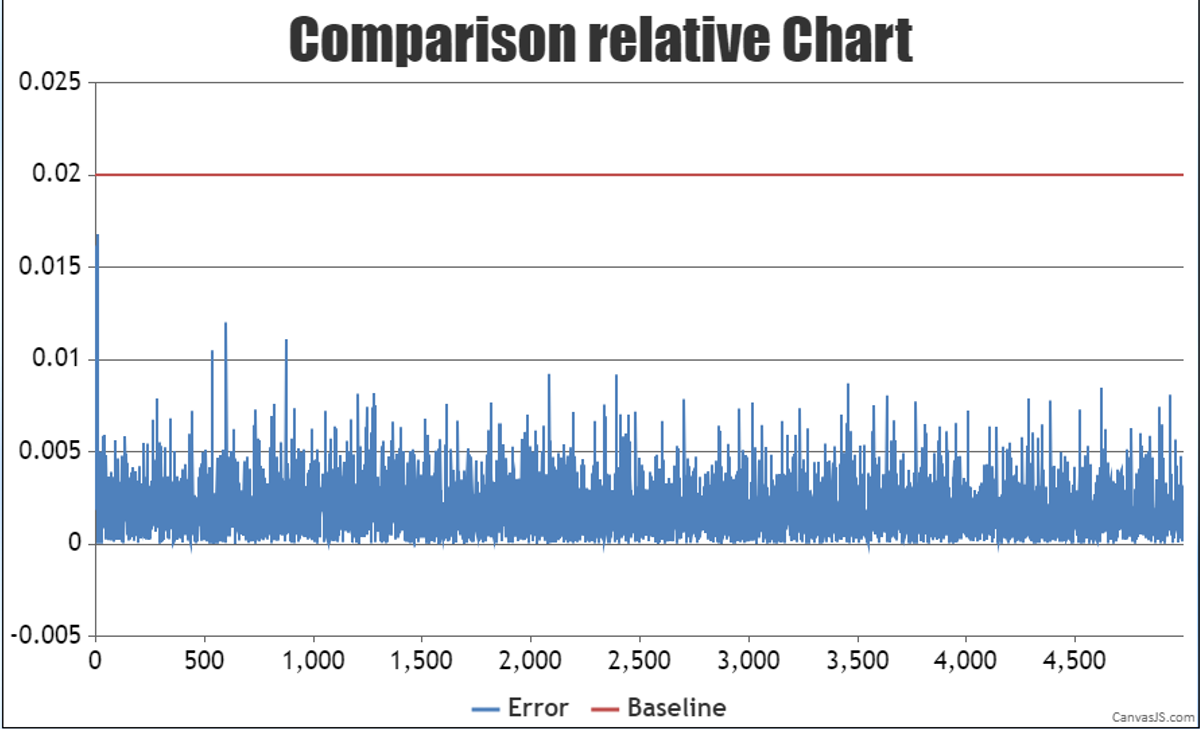
图表 NPU和业界设备长跑5000步loss误差对比
从图中可以看到,训练loss正常收敛,在NPU和业界设备分别长跑5000步以后,对比每步的loss,可以看到loss的平均相对误差在0.19%(整体在精度误差范围内)。
权重回合
MindSpeed MM修改了部分原始网络的结构名称,在微调后,如果需要将训练部分权重转回并合并至huggingface格式,可使用mm-convert权重转换工具对微调后的权重进行转换,将权重名称修改为与原始网络一致。
mm-convert Qwen2_5_OmniConverter mm_to_hf \
--cfg.save_hf_dir "ckpt/mm_to_hf/Qwen2.5-Omni-7B" \
--cfg.mm_dir "ckpt/mm_path/Qwen2.5-Omni-7B" \
--cfg.hf_config.hf_dir "ckpt/hf_path/Qwen2.5-Omni-7B" \
--cfg.parallel_config.llm_pp_layers [0,7,12,9] \
--cfg.parallel_config.vit_pp_layers [32,0,0,0] \
--cfg.parallel_config.audio_pp_layers [0,32,0,0] \
--cfg.parallel_config.tp_size 1
# 其中:
# save_hf_dir: mm微调后转换回hf模型格式的目录
# mm_dir: 微调后保存的权重目录
# hf_dir: huggingface权重目录
# llm_pp_layers: llm在每个卡上切分的层数,注意要和model.json中配置的pipeline_num_layers一致
# vit_pp_layers: vit在每个卡上切分的层数,注意要和model.json中配置的pipeline_num_layers一致
# audio_pp_layers: audio在每个卡上切分的层数,注意要和model.json中配置的pipeline_num_layers一致
# tp_size: tp并行数量,注意要和微调启动脚本中的配置一致
【更多参数见MindSpeed MM仓库】
准备工作和参数说明见MindSpeed MM开源代码仓链接:
https://gitcode.com/Ascend/MindSpeed-MM/tree/2.2.0/examples/qwen2.5omni
结语
MindSpeed MM是面向大规模分布式训练的昇腾多模态大模型套件,同时支持多模态生成、多模态理解及全模态大模型分布式训练,旨在为昇腾设备提供端到端的多模态训练解决方案, 包含预置业界主流模型,数据工程,分布式训练及加速,预训练、微调、在线推理任务等特性。MindSpeed MM即将上线更加丰富的支持Qwen2.5Omni模型的特性,敬请期待。欢迎关注
MindSpeed MM:https://gitee.com/ascend/MindSpeed-MM